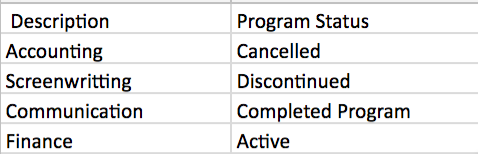
I need to search student profiles on an online database and see whether they're either 'Active in a program' or have 'Completed' it (see pic). If they have done either, I need to copy the description.
I would like to know how I could make KM find the word 'Active', copy the description on the left, if not, find the word 'Completed' and copy the left description.
I believe when you select the rows of the table and copy them to the clipboard, you strip the HTML in Safari, Firefox and Chrome. So you end up with columns separated by tabs.
That's all you need.
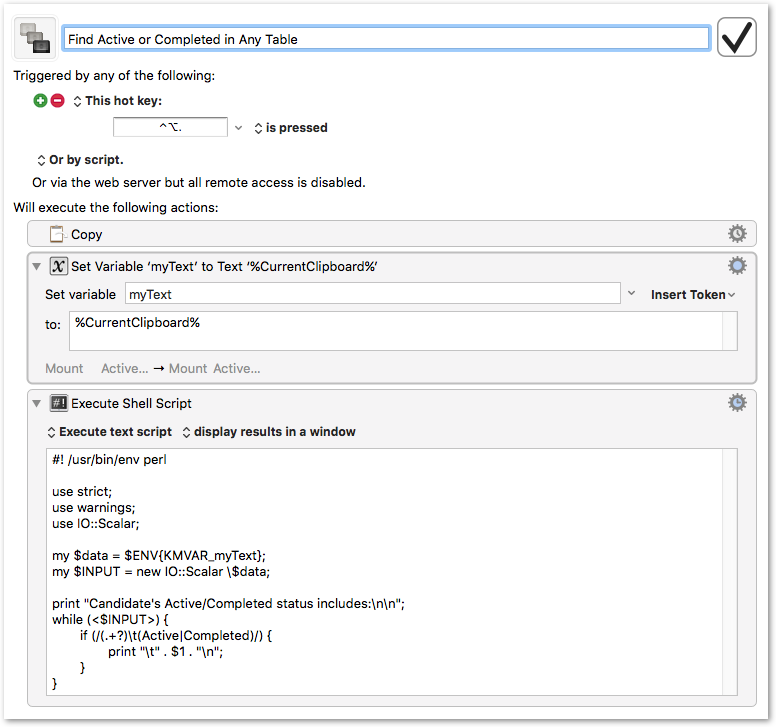
Taking your example data, the attached macro will report which Descriptions are Active or Completed in a window whose text you can copy.
As a proof, I've entered the data in the second action, so just hit the Control-Option-Period key to see it work.
But to actually use it, you should disable the second action and enable the first one, which reads the clipboard into a variable rather than the hard coded text.
You will have to select the rows and Copy them but if this works for you, you can start the macro off with a Copy action to save a step.
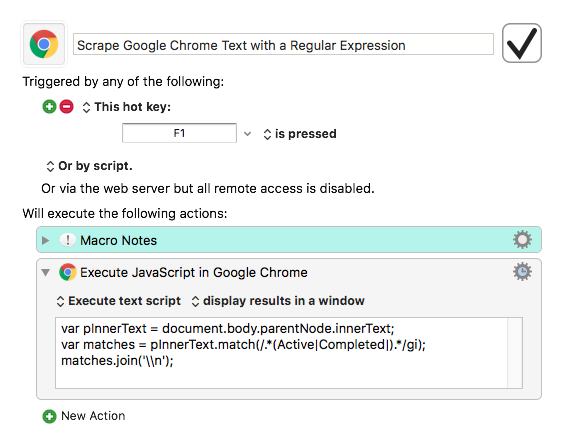
Intrigued, I installed Chrome to try this out. It returned the whole innerText of my test page which included a two-column table whose second column had the “Active,” etc. labels.
But you’re using a different regex than I was. I was capturing the text before a tab followed by either the Active or Completed label (case sensitive):
var matches = pInnerText.match(/(.+?)\t(Active|Completed)/g);
And the captured text would be returned as matches[1], I believe.
Chris, if you are talking about JavaScript here, it is quite easy to return capture groups with matches:
var sourceStr = `
ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA
`
var regEx = /(ABCD\-[^\s]+)/g;
var captureList = [];
var matchResults;
while (matchResults = regEx.exec(sourceStr)) {
captureList.push(matchResults[1]);
}
captureList
//--- RESULTS ---
/*
["ABCD-123abc", "ABCD-abc234", "ABCD-76y65yj90", "ABCD-76yABC90", "ABCD-code6547AA"]
*/
A one-liner would be easy. That is convoluted – although not ridiculously hard to do or to understand.
In the original context I believe Mike thought that the one line would return capture 1, and as I said it's not quite that easy.
Mike – please correct me if I'm wrong.
This is more simply done in Perl:
#!/usr/bin/env perl -sw
my $string = "
ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA
";
my @strings = $string =~ m/(ABCD\-[^\s]+)/gi;
$, = "\n";
print @strings;
It's easier yet using AppleScript and the Satimage.osax.
set theString to "
ABCD-123abc
Some text ABCD-abc234 some other text
ABCD-76y65yj90
ABCD-76yABC90 some text ABCD-code6547AA
"
set foundStrings to find text "(ABCD\\-[^\\s]+)" in theString using "$1" with regexp, all occurrences and string result
# CHANGE the dollar sign in “using "$1"” above to backslash backslash
# There is a bug in Discourse that prevents the correct syntax from displaying properly.
The downloadable AppleScript has the correct syntax:
Using Safari instead of Chrome makes this a walk in the park when using the Satimage.osax.
Again using the Boom Table as source.
tell application "Safari" to set pageText to text of front document
set foundList to find text ".*life.*" in pageText using "\\0" with regexp, all occurrences and string result
I don't know what you mean by "convoluted".
It is standard, normal, JavaScript.
Your Perl and AppleScript (which really requires Satimage.osax) may seem simpler to you because you already understand them very well. You can't even do RegEx in normal AppleScript. You have to use either a scripting addition like Satimage.osax, of resort to the very complex ASObjC.
The choice of tool/language depends on both which does the best job, and which tools the user know how to use. So I don't put down any particular tool, especially if I don't understand it very well.
I do have to say that JavaScript is probably more widely used and known than any of the other languages (Perl, AppleScript) that are mentioned here.
If anyone wants to know how to do something in JavaScript, then a simple google with "JavaScript" and the keywords (like "regex", "capture", etc) will give you many hits/solutions.
Yep, that does the trick (who'd a thunk it). I do find it easier to do this in Perl, as Chris mentioned, but I liked his innerText approach enough to fiddler around with the JavaScript.