Is there a simple way to insert the first word of current clipboard (a person’s full name) into a web form (Facebook)? I can’t find an example of what I want. I am familiar with Applescript but have no idea how to send and return text from KM to a script.
Yes, I am familiar with the Applescript, what I wanted to know was how to incorporate it into KM. Do I have to save the script in the Library/Scripts folder and refer to it in KM or is there a way of putting the actual code somewhere in KM as a function?
Put the AppleScript into a Execute AppleScript action in KM.
Thank you, that is exactly what I wanted.
1 Like
Hey Ed,
It's a little easier than that:
set fName to first word of (the clipboard)
Hey Joe,
AppleScript works fine for this sort of thing, but Keyboard Maestro has regular expressions and can do the job with greater precision.
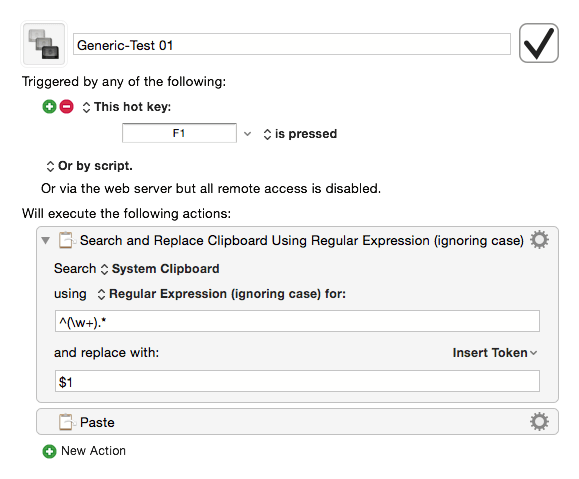
The regular expression captures any word-characters from the beginning of the text until a non-word character is found.
The clipboard's contents is replaced with the captured text and then pasted.
If you're using the same form over and over then you might want to look into the following actions:
Submit Google Chrome Form
Submit Safari Form
If those won't work then you can still very likely use an Execute JavaScript Action in either Safari or Chrome.
The advantage is that text is automatically placed in the correct field in the browser without having to paste from the clipboard, but for this to be practical the form has to be the same every time.
If you're pasting into random form fields then using the clipboard is the way to go.
-Chris
P.S. You can add regular expression support to AppleScript by installing the Satimage.osax — and I do on all Macs under my control.
1 Like
Hey Chris, thanks for sharing. That is very cool.
BTW, you wouldn't happen to have in your vast library of snippets RegEx code for the following cases:
- First n words
- nth word from beginning
- Last n words
- nth word from the end
I'm NOT asking you to go develop these. Just asking for a share if you already have them. ![]()
Thanks, oh master of AppleScript and RegEx. ![]()
Hey Michael,
This is the sort of stuff you spend hours reading books, Googling, and wrestling with to learn. ![]()
These are far from bombproof, because I've just thrown them together — I reckon one of the RegEx Cookbooks has some excellent and well-tested formulae for them though.
In these I'm only handling alphabetic characters, and I'm not doing anything to manage punctuation.
-------------------------------------------------------------------
# NOTE that '$1' is the return string for Keyboard Maestro's RegEx Find/Replace (clipboard or variable).
-------------------------------------------------------------------
# Demo String
one two three four five six seven eight nine ten
-------------------------------------------------------------------
First n words:
# Words = {n}
# May have a trailing space or tab:
^((?:\w+(?:[[:blank:]]|$)){4}).*
$1
# Words = {n} + 1
# Prevents trailing space or tab:
^((?i)(?:[a-z]+[[:blank:]]){3}[a-z]+(?=[[:blank:]]|$)).*
$1
-------------------------------------------------------------------
nth word from beginning:
# 4th Word - word = {n} + 1
^(?i)(?:[a-z]+[[:blank:]]){3}([a-z]+)(?=[[:blank:]]|$).*
$1
-------------------------------------------------------------------
Last n words:
# 4 Words - words = {n} + 1
(?i)^.*?((?:[a-z]+[[:blank:]]){3}[a-z]+)[[:blank:]]*$
.*?((([a-z]+)(?:[[:blank:]]|$)){4}$)
$1
-------------------------------------------------------------------
nth word from the end:
# Word -4 - Word index = ({n} + 1) * -1
.*?([a-z]+)(?:[[:blank:]]|$)(?:([a-z]+)(?:[[:blank:]]|$)){3}$
-------------------------------------------------------------------
Dealing with "words" can get quite tricky, so when I do this kind of thing I'm most likely going to build a function (handler in AppleScript) to take care of some of the more obvious pitfalls.
This handler removes any whitespace and/or punctuation from the beginning and/or end of the input-string.
It then breaks up the words using the whitespace between them.
From there you have a simple list of words to deal with.
----------------------------------------------------------
# REQUIRES THE SATIMAGE.OSAX { http://tinyurl.com/dc3soh }
----------------------------------------------------------
set _text to " “one two three four five six seven eight nine ten.” "
set wordsFromFront to getWords(4, _text, 1, " ")
set wordsFromEnd to getWords(4, _text, -1, " ")
on getWords(wordNum, _text, _direction, _delim)
set _text to change "^[[:blank:][:punct:]]+|[[:blank:][:punct:]]+$" into "" in _text with regexp
set wordList to splittext _text using "[[:blank:]]+" with regexp
if length of wordList ≥ wordNum then
set wordList to items (1 * _direction) thru (wordNum * _direction) of wordList
set wordList to join wordList using _delim
else
error "Error in Handler getWords()" & return & return & ¬
"Length of wordList (" & (length of wordList) & ¬
") inconsistent with variable wordNum (" & wordNum & ")."
end if
end getWords
You can take the same basic design and get an individual word rather than a range.
----------------------------------------------------------
# REQUIRES THE SATIMAGE.OSAX { http://tinyurl.com/dc3soh }
----------------------------------------------------------
set _text to " “one two three four five six seven eight nine ten.” "
set wordFromFront to getWord(4, _text)
set wordFromEnd to getWord(-4, _text)
on getWord(wordNum, _text)
set _text to change "^[[:blank:][:punct:]]+|[[:blank:][:punct:]]+$" into "" in _text with regexp
set wordList to splittext _text using "[[:blank:]]+" with regexp
if length of wordList ≥ (abs wordNum) as integer then
return item wordNum of wordList
else
error "Error in Handler getWords()" & return & return & ¬
"Length of wordList (" & (length of wordList) & ¬
") inconsistent with variable wordNum (" & wordNum & ")."
end if
end getWord
ASObjC has powerful if rather un-pretty methods of dealing with this sort of thing that I have yet to learn, and Rob will probably pop in and show how easily JXA can manage strings.
-Chris
2 Likes
Yep. Admonishment deserved and accepted. ![]()
You weren't supposed to go development them -- just share if you already had them. ![]()
But I really appreciate your effort and kindness. I'm sure they will be extremely useful, for me and others who discover this thread.
Do you have any of these Cookbooks that you would recommend?
Hey Michael,
This is a pretty decent book:
Regular Expressions Cookbook (Amazon-link)
One of the authors is Jan Goyvaerts who develops some pretty good Windows software and operates one of the better regex-info sites on the Net:
You can make a small donation and get a printable PDF of the whole site. I've been using that site for reference a long time, so I donated a few years ago. The PDF is definitely easier to read and is searchable.
-Chris
1 Like
Thanks, Chris. I’ll take a look. Much appreciated.
:- )
In Javascript you could pass your regex pattern to the String .split() function,
and then return particular sections or items of the word list with the Array .slice() function.
The definition of a word or token will depend a bit on the case, but for two simple definitions (gap-delimited, or word-boundary delimited – the latter yields punctuation items as tokens) you might write:
var str =
'Regular expressions are patterns used to match character combinations in strings. In JavaScript, regular expressions are also objects. These patterns are used with the exec and test methods of RegExp, and with the match, replace, search, and split methods of String. This chapter describes JavaScript regular expressions.';
// two simple definitions of a word or token
var lstWords = str.split(/\s+/),
lstAltWords = str.split(/\s*\b\s*/),
n = 4;
var dctResult = {
//First n words
firstN: [
lstWords.slice(0, n),
lstAltWords.slice(0, n)
],
//nth word from beginning
nth: [
lstWords[n - 1],
lstAltWords[n - 1]
],
//Last n words
lastN: [
lstWords.slice(-n),
lstAltWords.slice(-n)
],
//nth word from the end
nthFromEnd: [
lstWords.slice(-n, -n + 1),
lstAltWords.slice(-n, -n + 1)
]
};
Obtaining:
{
"firstN": [
[
"Regular",
"expressions",
"are",
"patterns"
],
[
"Regular",
"expressions",
"are",
"patterns"
]
],
"nth": [
"patterns",
"patterns"
],
"lastN": [
[
"describes",
"JavaScript",
"regular",
"expressions."
],
[
"JavaScript",
"regular",
"expressions",
"."
]
],
"nthFromEnd": [
[
"describes"
],
[
"JavaScript"
]
]
}
1 Like
Thanks, Rob.
Adding this to my JS lib and JS study list.
I hope to upgrade at least my test Mac to Yosemite in the next few days. And, if all goes well, then my main Mac. I am very much looking forward to re-learning and using JS and JXA.