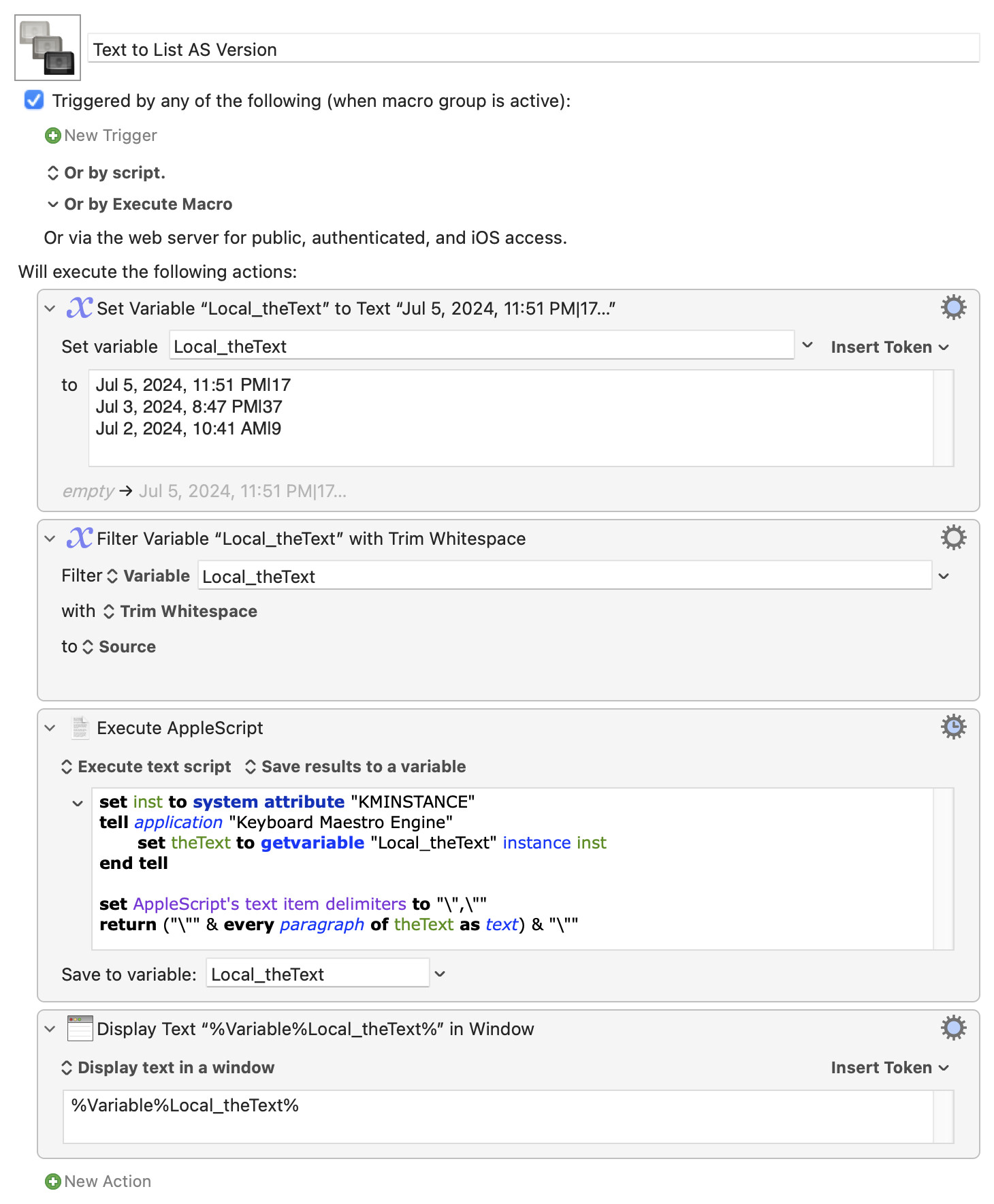
UPDATE (Jul 20, 2024)
I finally understand how the combo For Each+Search and Replace works.
Feel free to read what I just posted here
I can learn fast and understand complex concepts, but I gotta be honest: I feel pretty stupid when it comes to using these two together, because to me, it just makes no sense most of the time
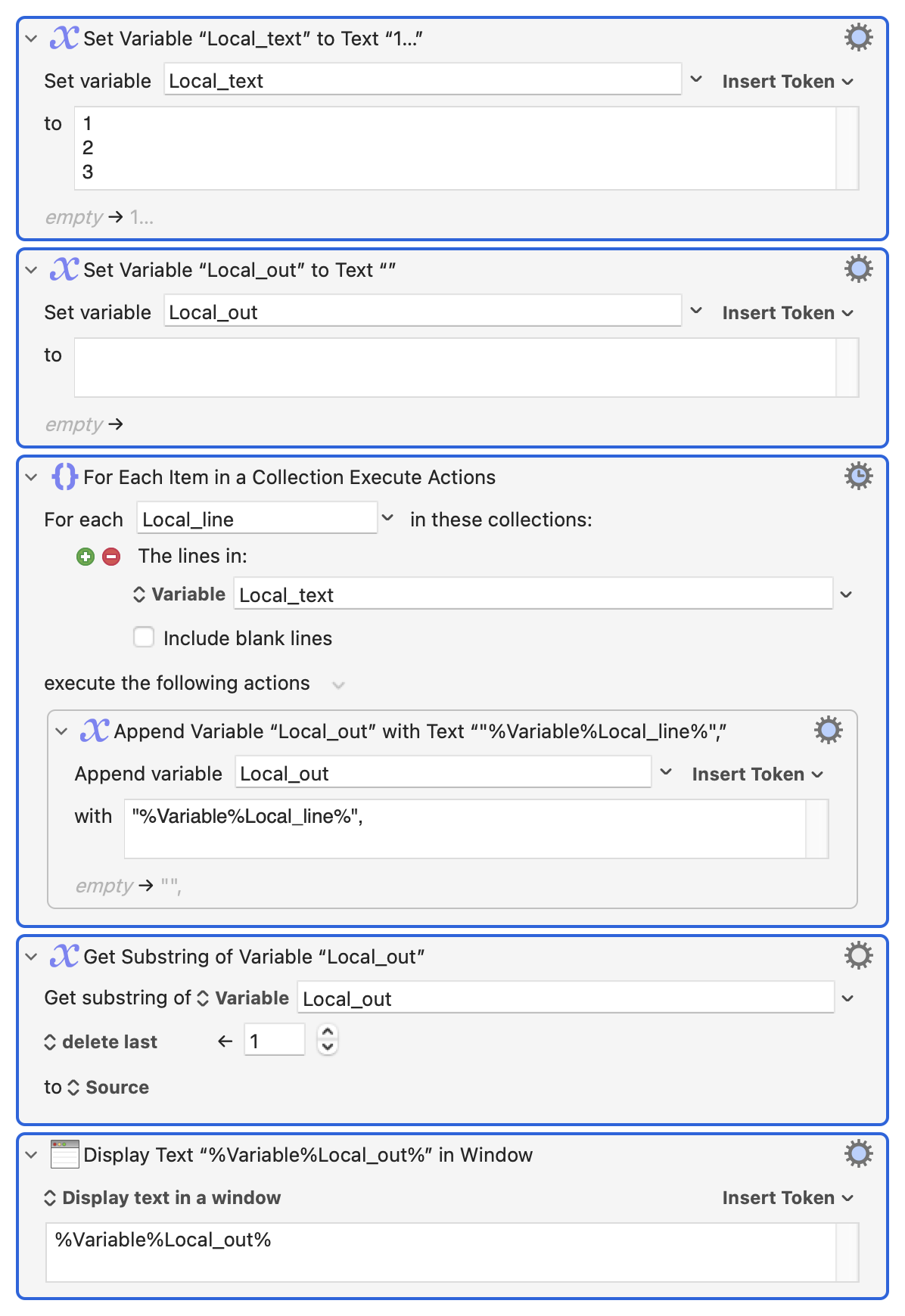
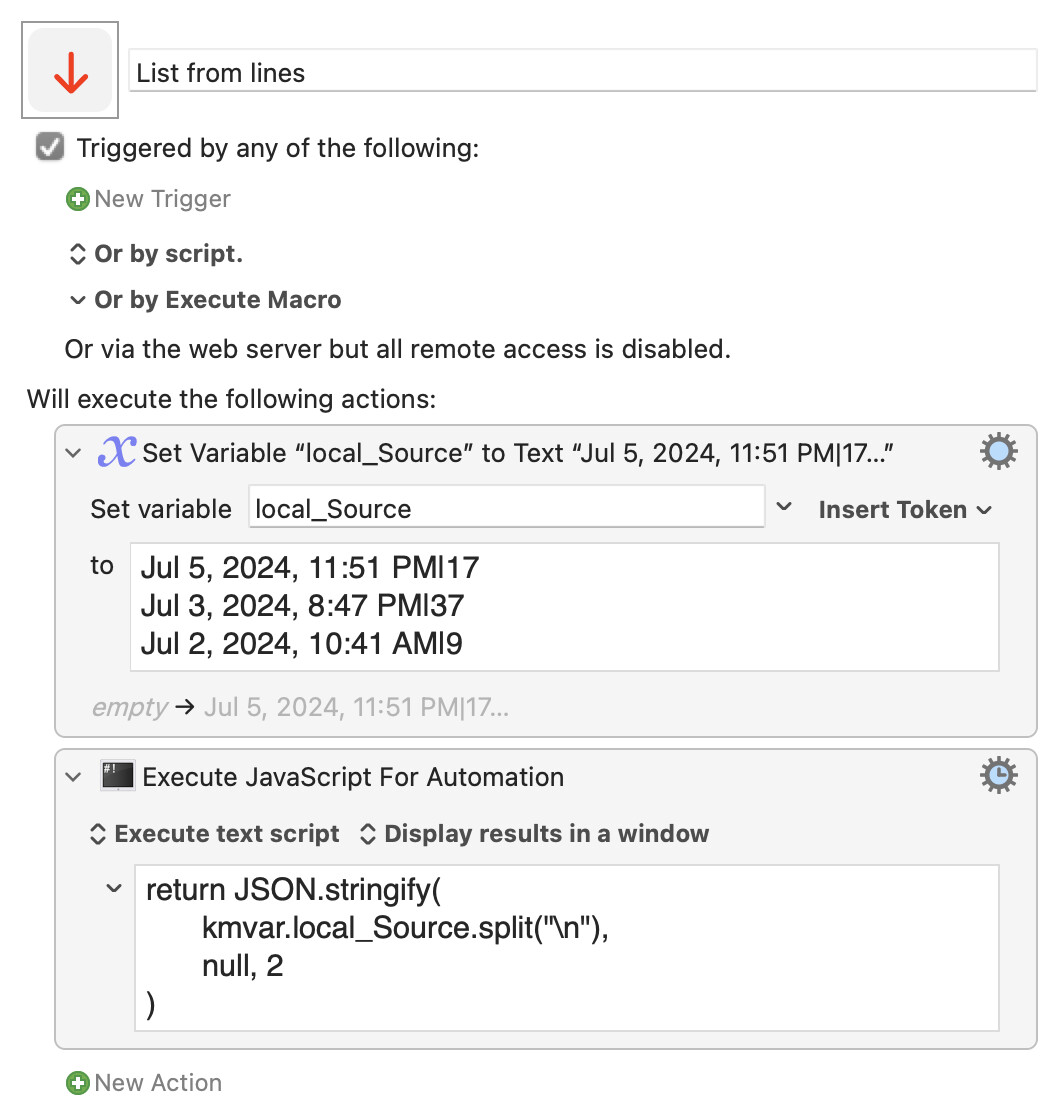
So I have this list:
Jul 5, 2024, 11:51 PM|17
Jul 3, 2024, 8:47 PM|37
Jul 2, 2024, 10:41 AM|9
And what I want to achieve is a list like this:
"Jul 5, 2024, 11:51 PM|17","Jul 3, 2024, 8:47 PM|37","Jul 2, 2024, 10:41 AM|9"
So I'm surrounding each line with double quotes and adding a comma to separate them. I know I could do this:
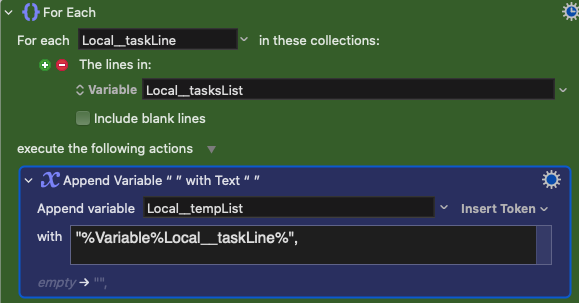
but this creates a list that ends with an extra comma, which is not what I need.
But even if there's a different approach, I would like to explore the one below so I can understand what's going on and if there's something I'm missing (I'm definitely missing it, but I can't understand the issue here).
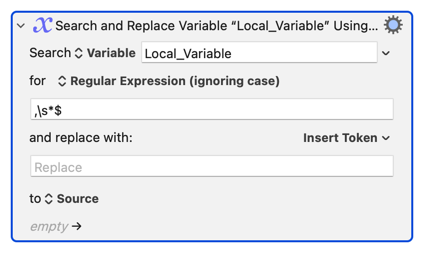
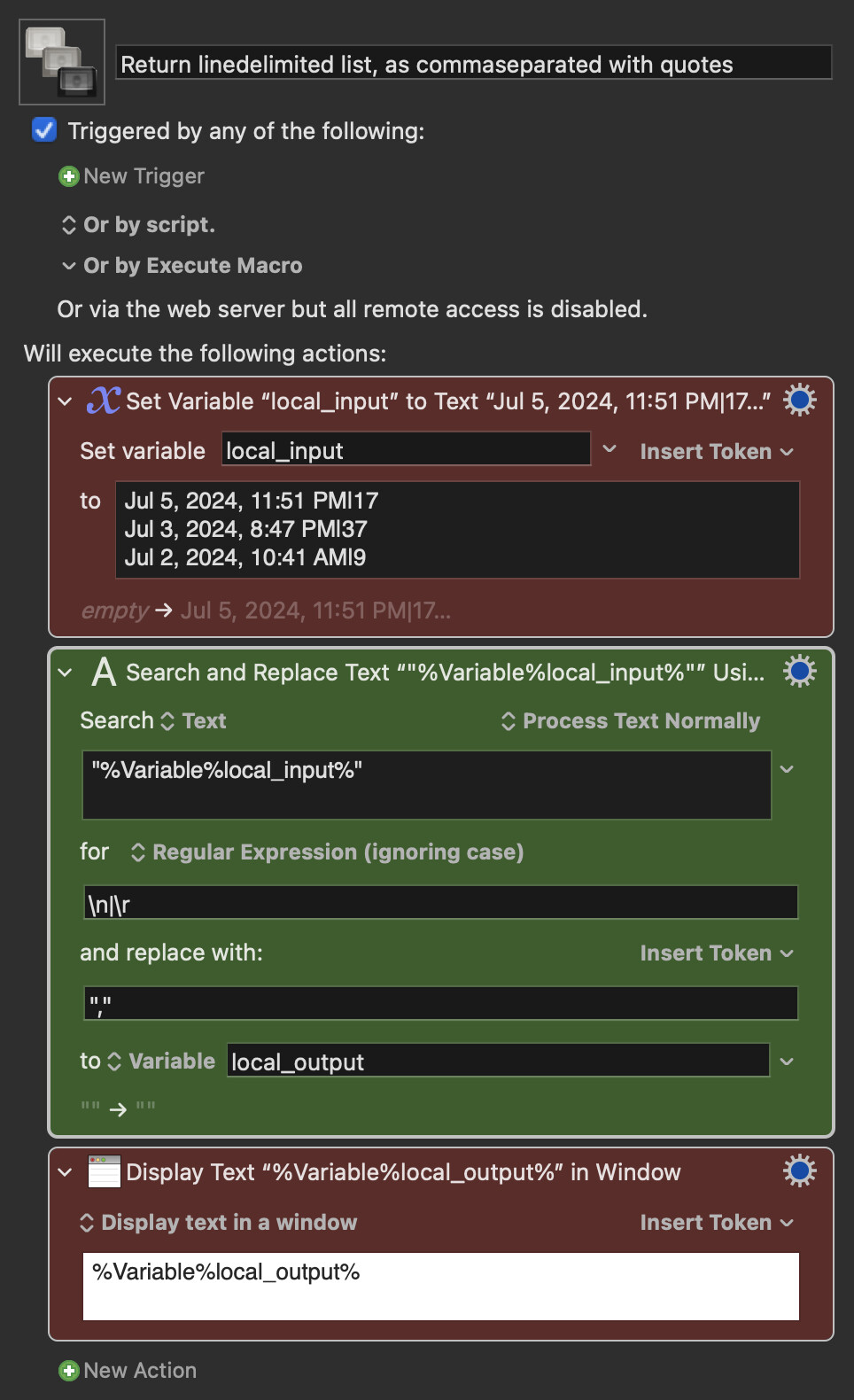
So I decided to use 2 Search and Replace actions and that's where I have no idea what's going on...
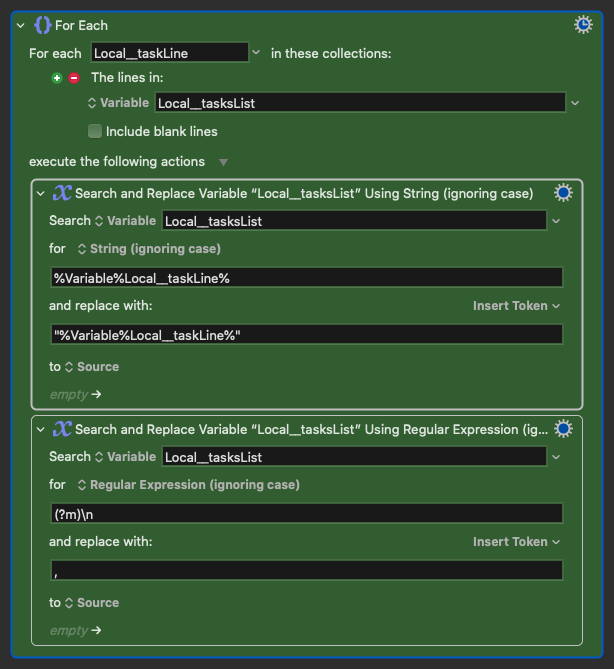
If I just activate the first SnR action, I indeed get the list like this:
"Jul 5, 2024, 11:51 PM|17"
"Jul 3, 2024, 8:47 PM|37"
"Jul 2, 2024, 10:41 AM|9"
But when I activate the second SnR, nothing happens.
Isn't the first action updating the source "Local__tasksList" with the new versions of each line, so isn't the list already updated to
"Jul 5, 2024, 11:51 PM|17"
"Jul 3, 2024, 8:47 PM|37"
"Jul 2, 2024, 10:41 AM|9"
when I then run the second SnR to replace each new line with a comma? ![]()
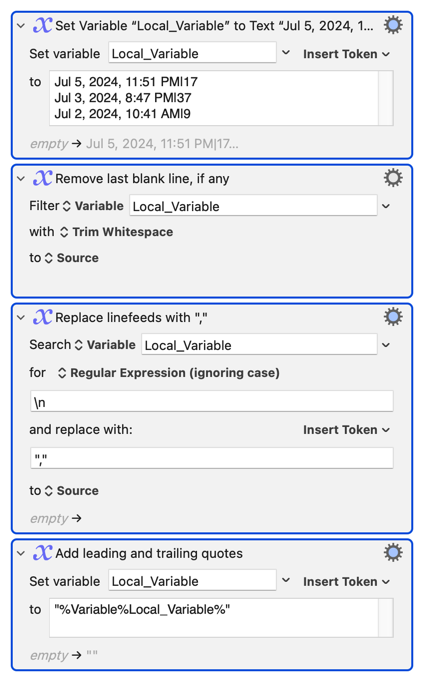
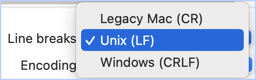
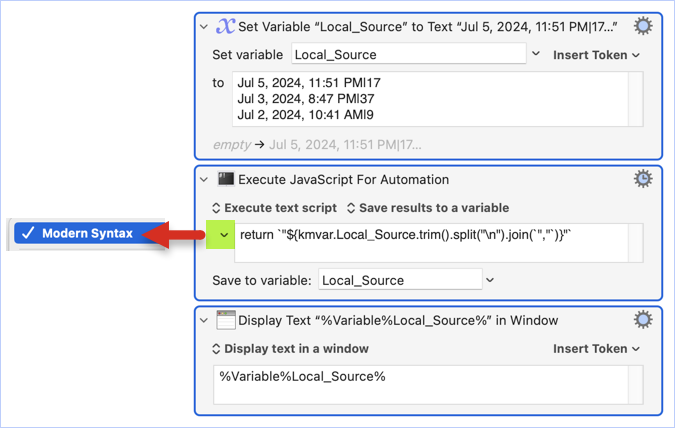
EDIT: Ok, I think the issue in this particular case is how KM is handling the \n because I moved the second SnR action outside the For Each loop and changed it to this:
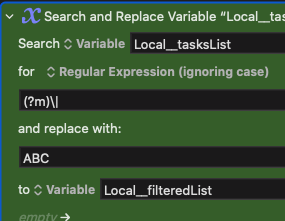
And it worked:

But when I change it back to this:
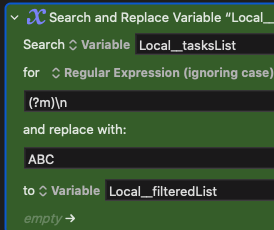
... it doesn't work, even thogh on the RegEx website, it works:
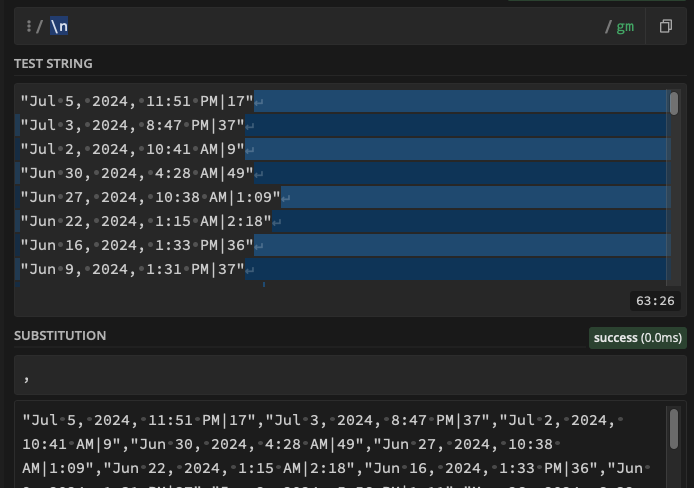
IMPORTANT NOTE: Even if this is indeed an issue with \n I still find the For Each + SnR combination to be confusing most of the time. ![]()