The question: Why does our For Each loop only write one line to CleanTOC.txt instead of all matching lines?
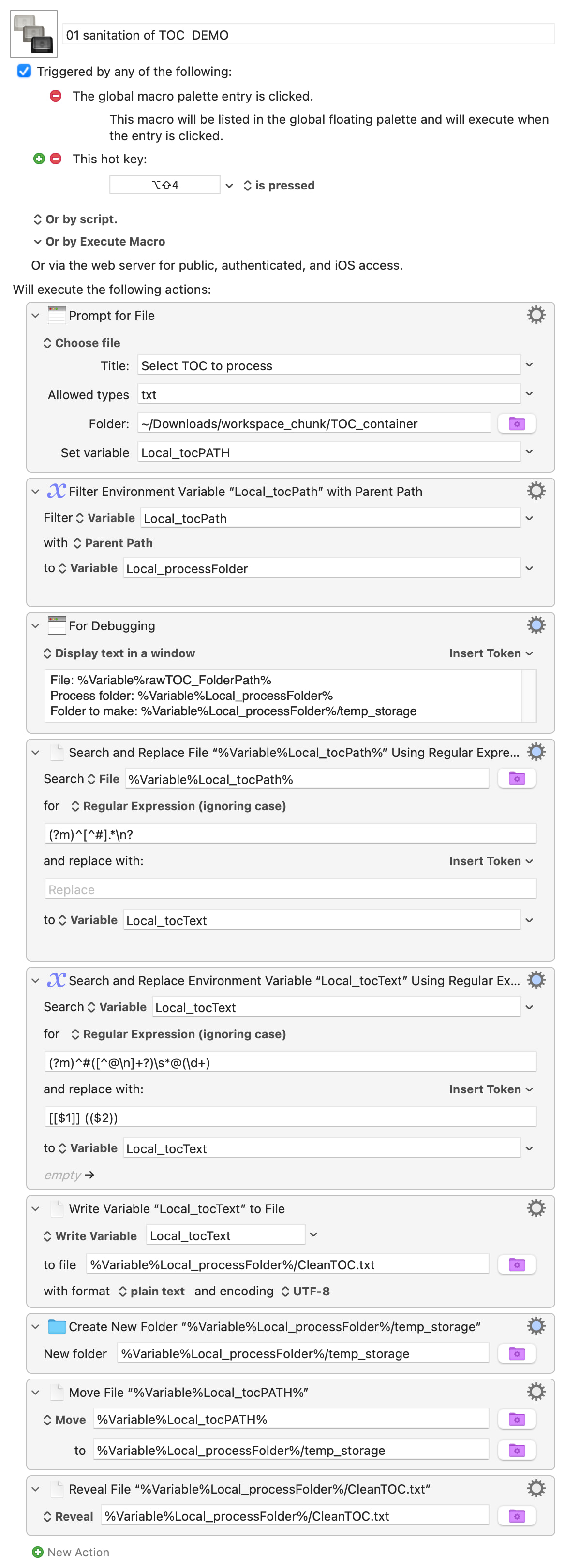
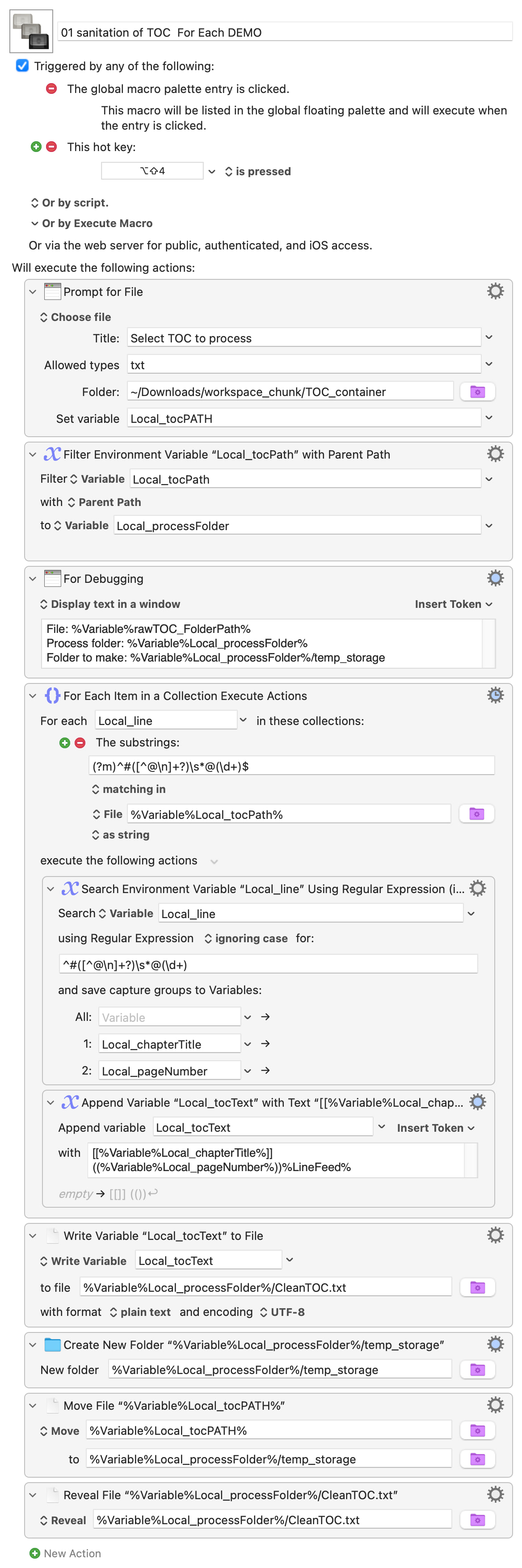
What we are trying to do: A macro that reads a marked TOC text file (rawTOC.txt) line by line, extracts lines marked with #title @pagenumber, converts them to wiki format [[title]] ((pagenumber)), and appends each matching line to CleanTOC.txt in the same book folder.
The macro logic:
-
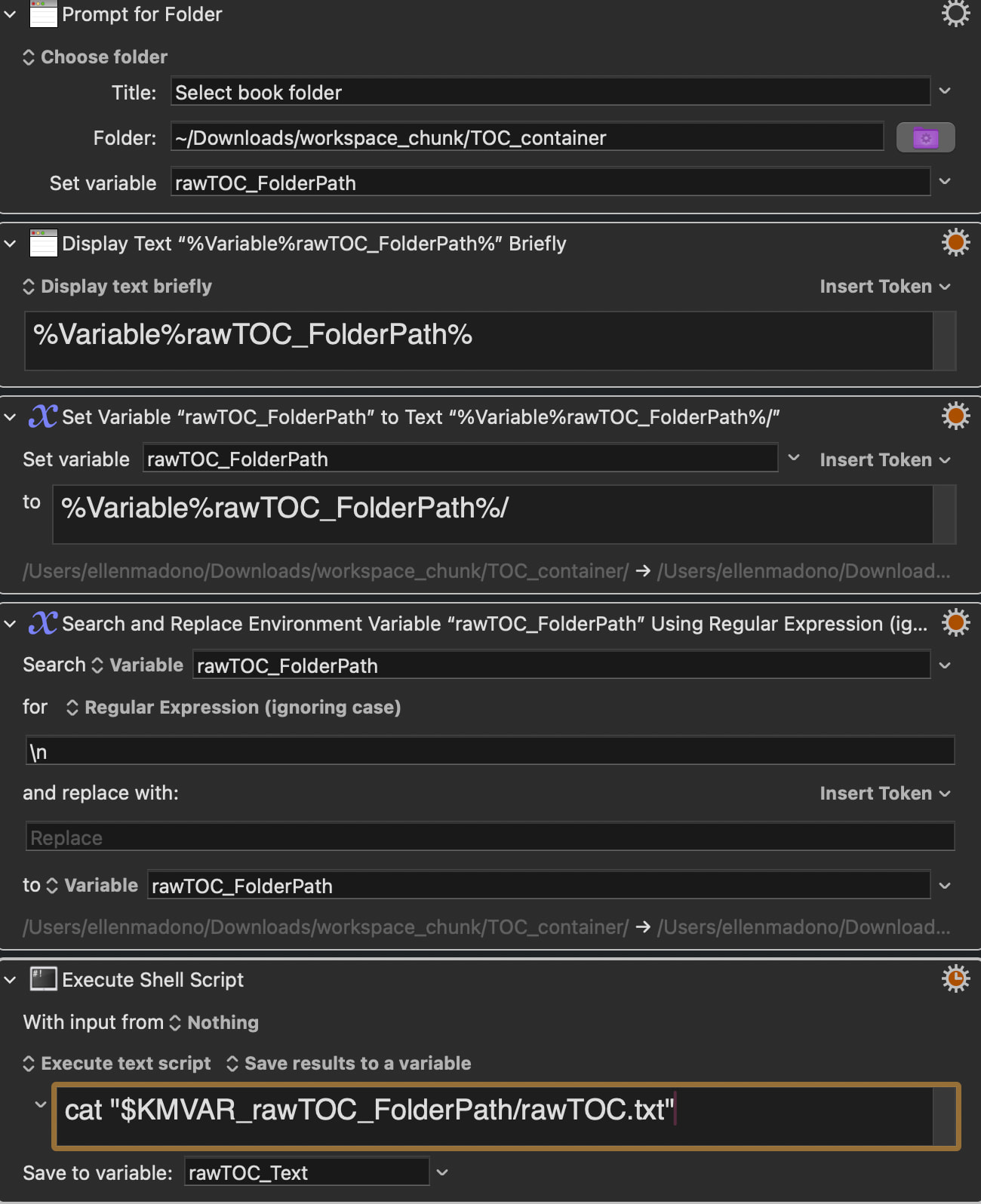
Prompt for Folder →
rawTOC_FolderPath -
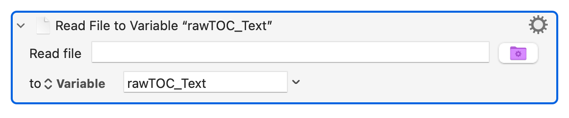
Read rawTOC.txt →
rawTOC_Text -
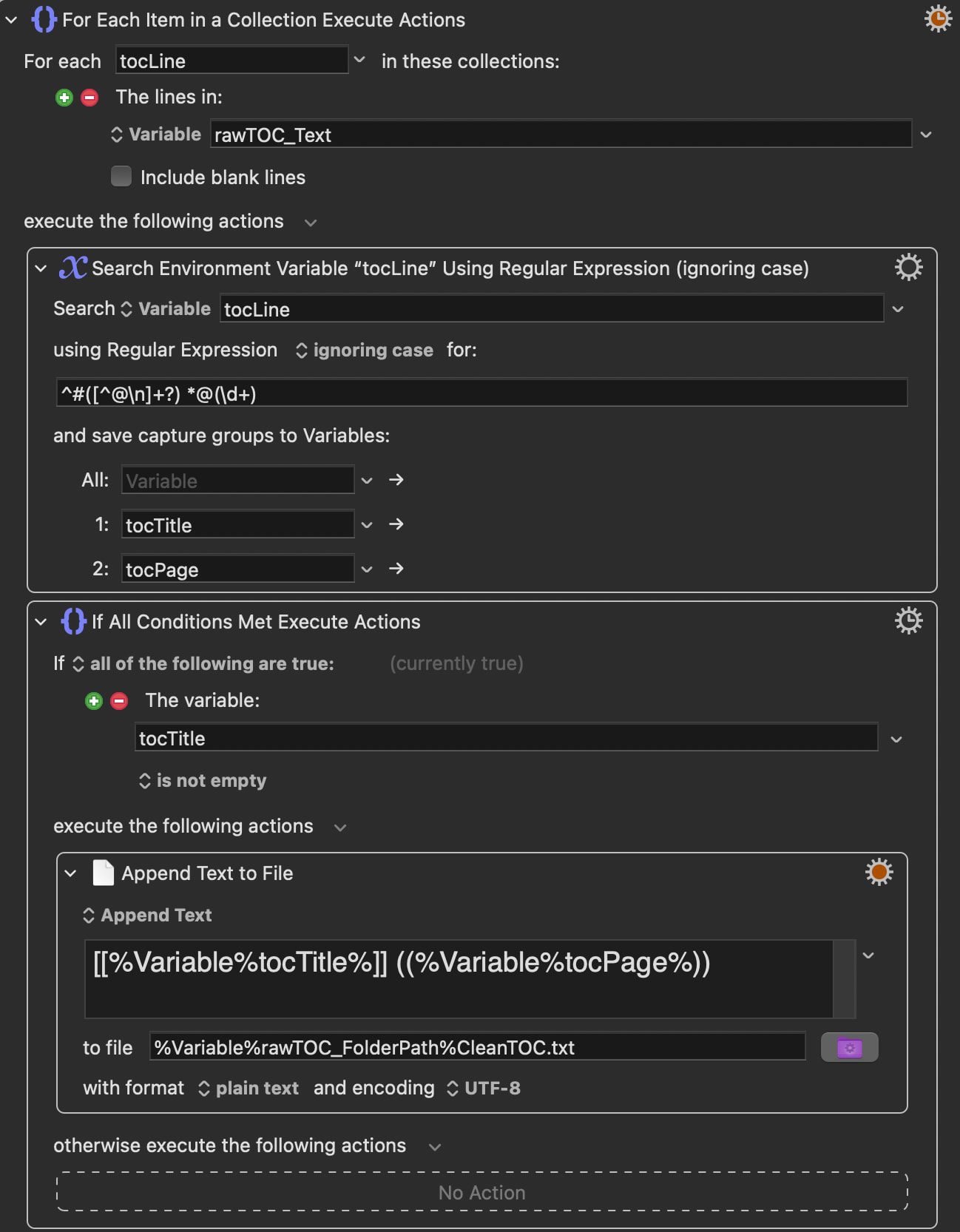
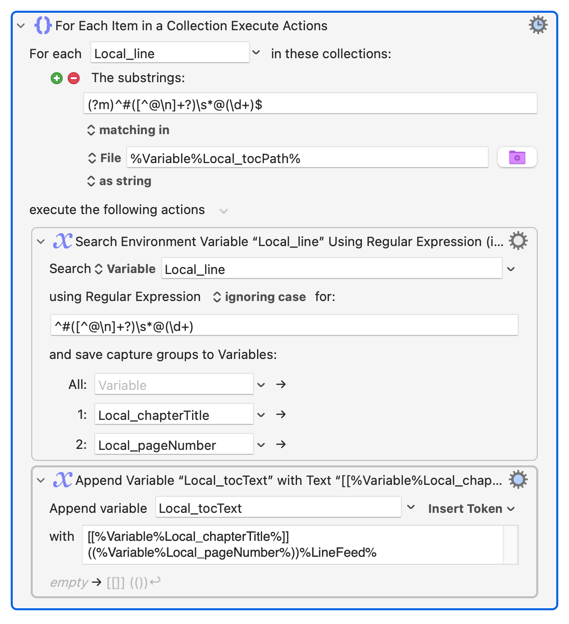
For Each line in
rawTOC_Text→tocLine -
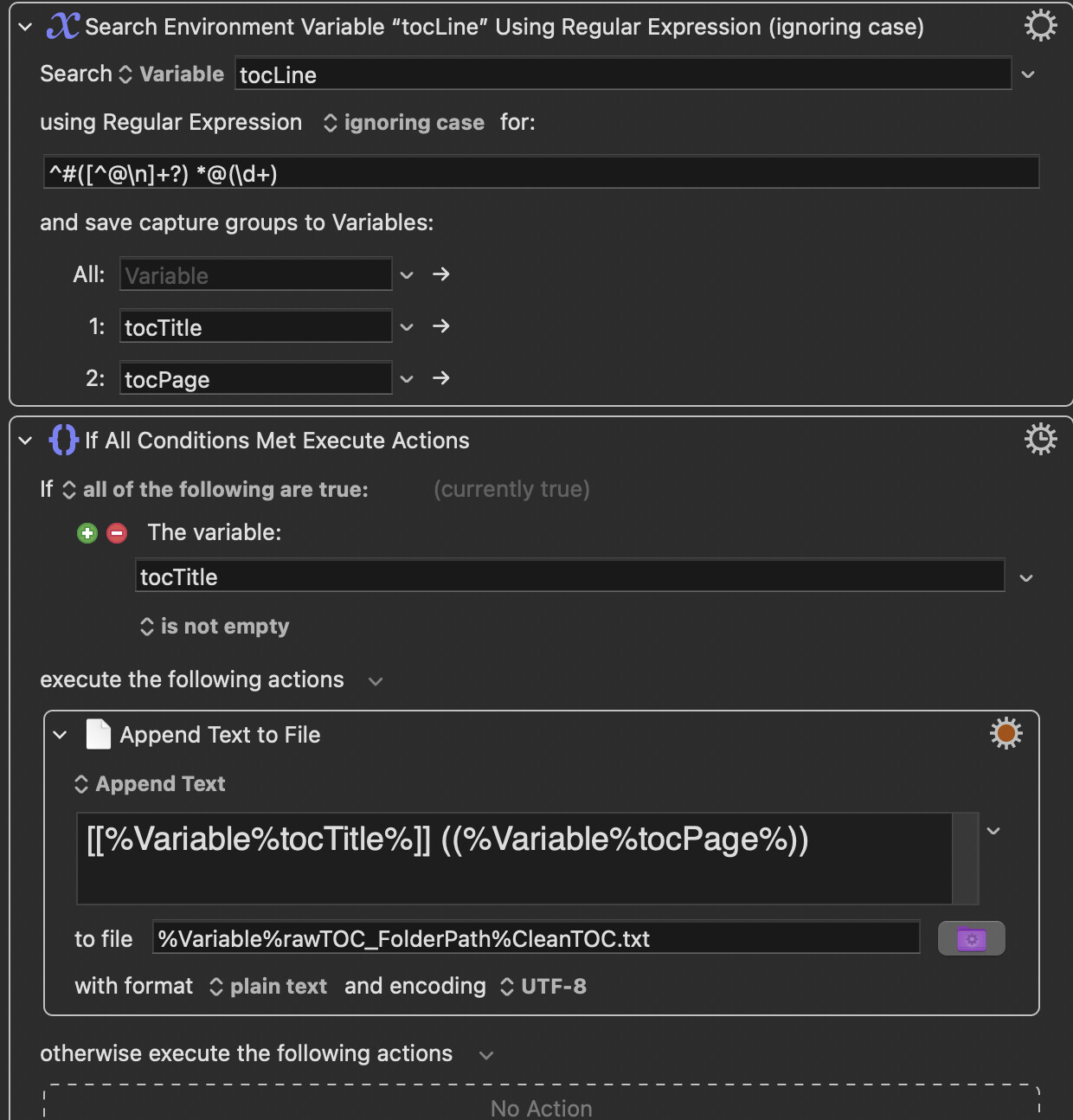
Search
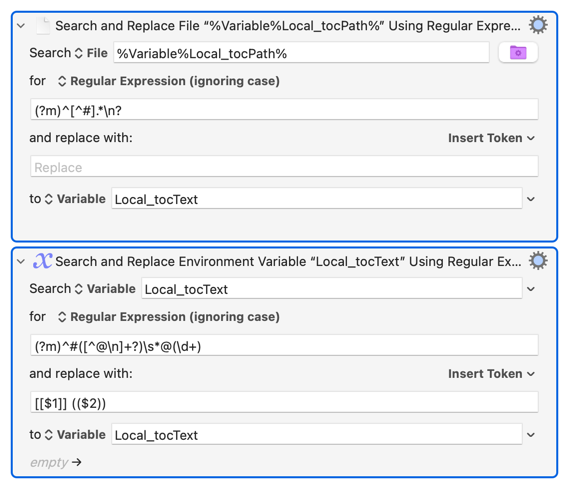
tocLinewith regex^#([^@\n]+?) *@(\d+)→ capturestocTitleandtocPage -
If
tocTitleis not empty → Append[[tocTitle]] ((tocPage))to CleanTOC.txt
The problem: CleanTOC.txt is created in the right folder but contains only one line — the first matching entry — instead of all matching entries from rawTOC.txt.
The question again: Why is the Append Text to File action inside the For Each loop only executing once instead of for every matching line?
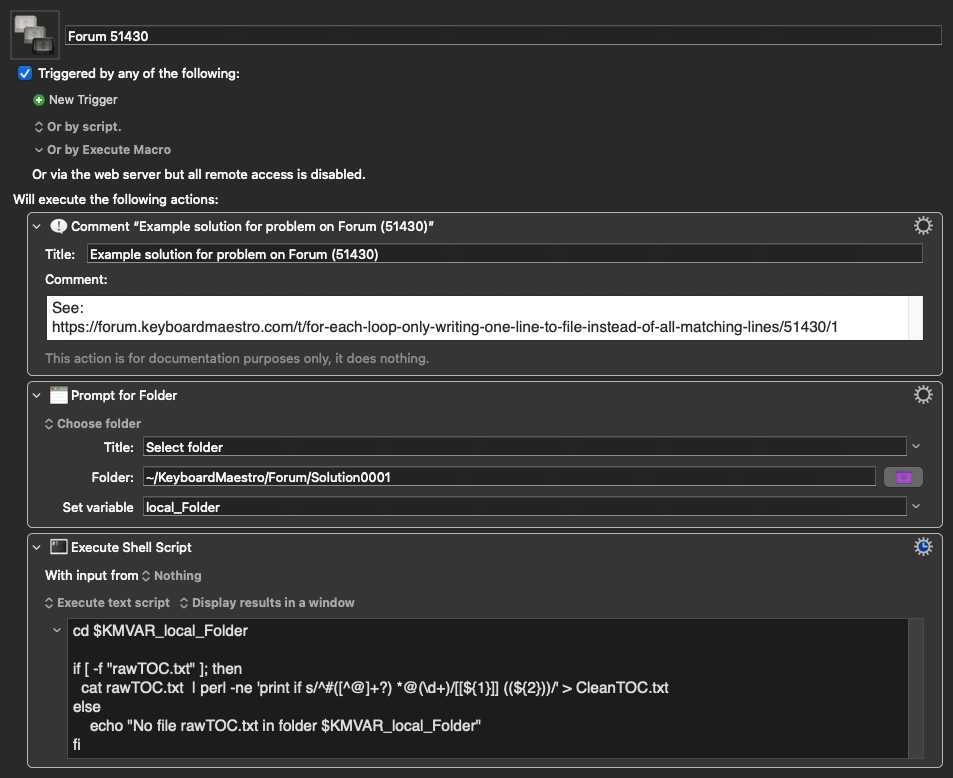
Problem action:
01 sanitation of TOC .kmmacros (10.2 KB)
Engine log:
The log suggests that the regex is incorrect
2026-04-04 15:24:29 Action 100976430 failed: Search Regular Expression failed to match ^#([^@\n]+?) *@(\d+)
2026-04-04 15:24:29 Search Regular Expression failed to match ^#([^@\n]+?) *@(\d+). Macro “01a sanitation of TOC copy” cancelled (while executing Search Environment Variable “tocLine” Using Regular Expression (ignoring case)).
2026-04-04 15:26:28 Execute macro “01a sanitation of TOC copy” from trigger The Global Macro Palette
2026-04-04 15:26:32 Action 100976421 failed: Read File action failed because source is not a full path (null)
2026-04-04 15:26:32 Read File action failed because source is not a full path (null) in macro “01a sanitation of TOC copy” (while executing Read File to Variable “rawTOC_Text”).
2026-04-04 15:26:33 Action 100976430 failed: Search Regular Expression failed to match ^#([^@\n]+?) *@(\d+)
2026-04-04 15:26:33 Search Regular Expression failed to match ^#([^@\n]+?) *@(\d+). Macro “01a sanitation of TOC copy” cancelled (while executing Search Environment Variable “tocLine” Using Regular Expression (ignoring case)).