Hi there, so I see that there are tokens to get the browser page title and url when it's the front most window, but I'm wondering if it's possible to get this information from just a link? I saw this great post with a macro that lets you download webarchives without opening the browser and got interested: Create Web Archives (Download Web Page) from a List of URLs @ccstone
I download a lot of video from spreadsheets with custom naming. The only thing keeping me from making this a fully background task is that I use the browser title and full urls to generate the various names, which means opening each link one by one to get that info.
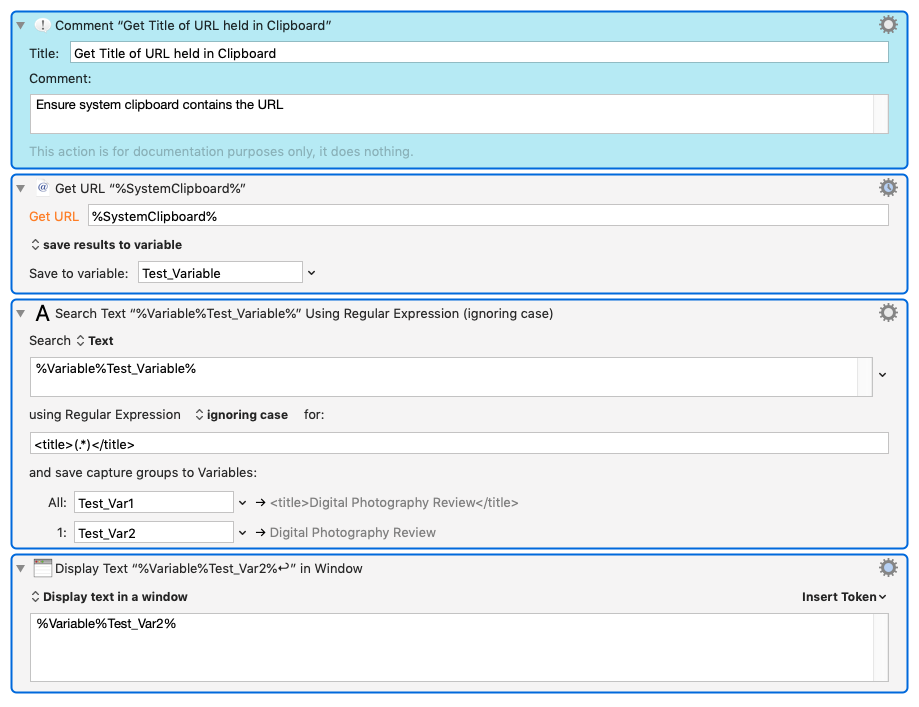
I'm pretty sure there are some clever ways of doing this but my simple-minded approach to get the title of the page from its URL without loading it up in a browser is this:
Re-opening this because I'm suddenly having an issue with Twitter links. The Get URL function is not giving me any info about the Browser Title, if anyone has any ideas that would be excellent.
Random Cat Video EX:
Link: https://twitter.com/damn_elle/status/1269873428804190208
Browser Title expected results: I think we should all watch this cat try ice cream for the first time.
Just tried this out again and it seems that what the Get URL action returns is not the same as the source of the web page (which you can look at in a browser). I'm not sure why they're different but it must be to do with the way the browser renders the web page, which is not something available to the Get URL action.
Perhaps @peternlewis or another expert could clarify what's going on.
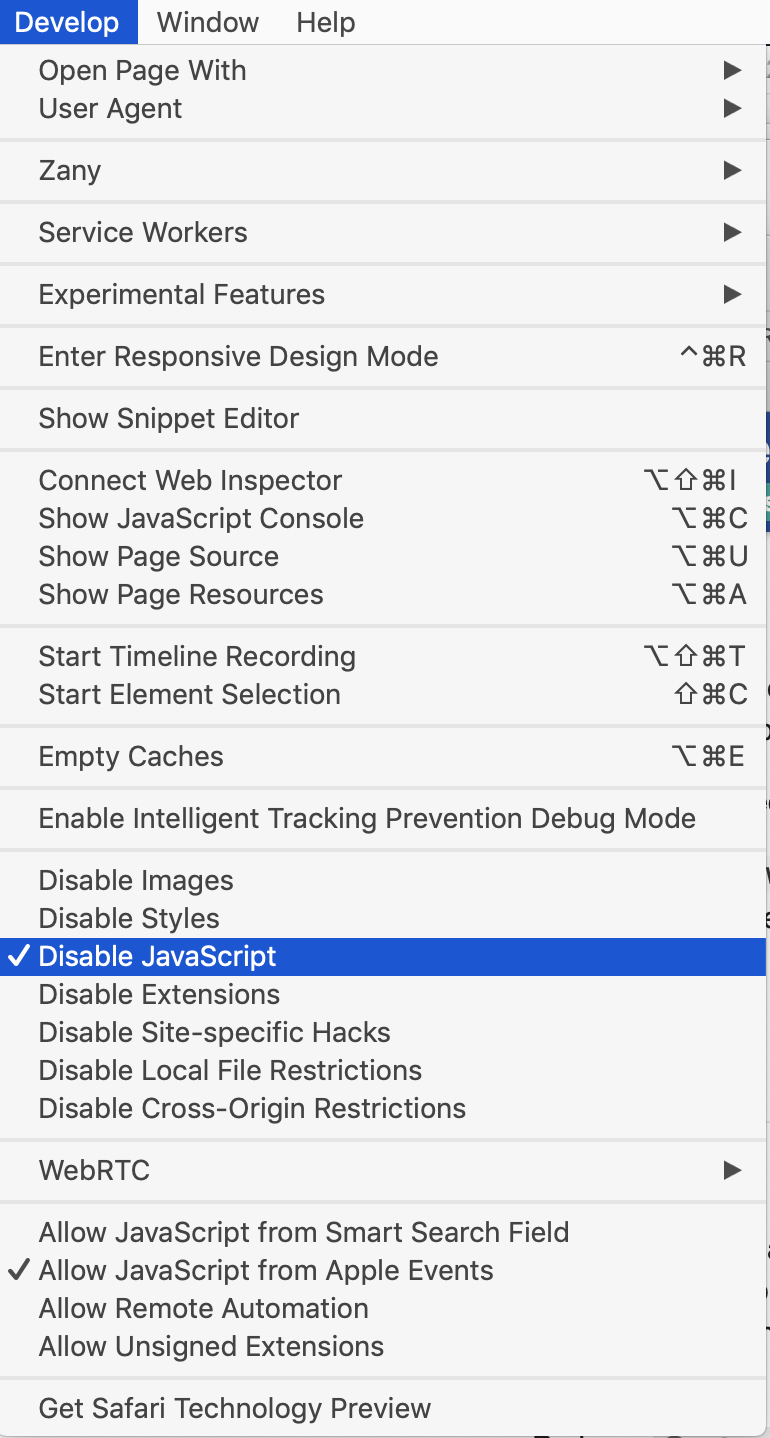
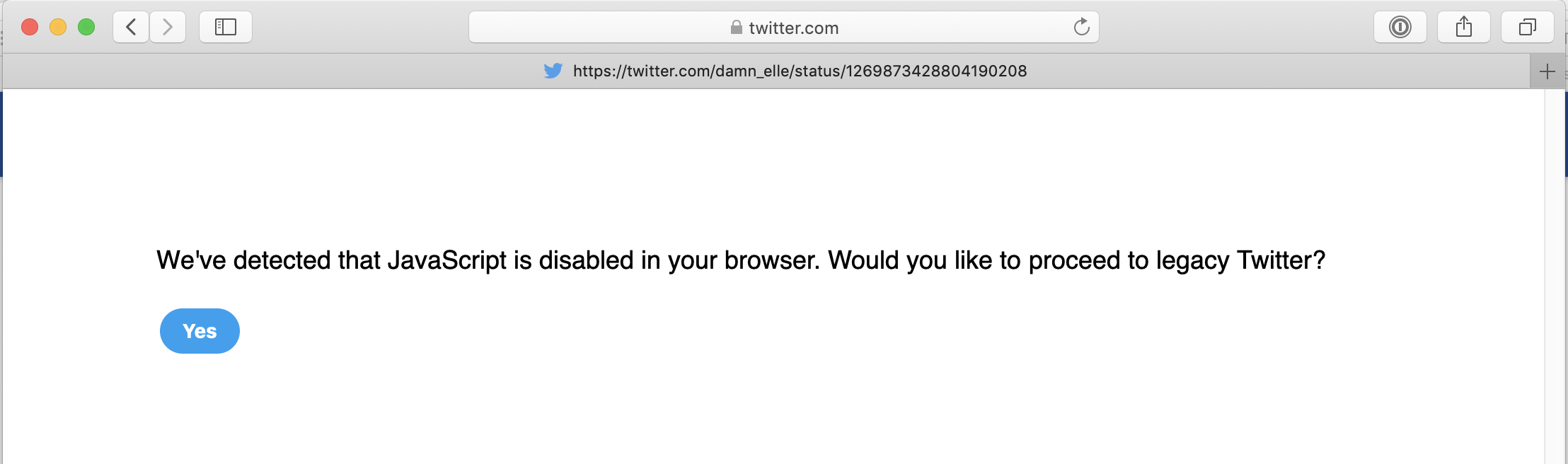
I checked this particular URL, and if you try to get it with Keyboard Maestro it detects the absence of JavaScript - you can try this in Safari if you disable JavaScript:
If you follow the link, you get to https://mobile.twitter.com/greg_doucette/status/1266886293562286086 and unfortunately for you, that does not set the title at all.
So it appears the title is set via JavaScript (which you can actually see if you visit the original link, it goes through several variants before it finishes with the final title).