NOTE: This code only works with KM version 10 (and above)
This JXA code retrieves the XML for a specified Macro UUID, converts it into a "Plist" object, and displays some properties.
This also includes some examples of how to use VSCode's support for Intellisense based on JSDoc, which I think is pretty cool.
NOTE:
I am well aware that this code could be written more concisely. The point of this example is to be semi-self-documenting, and be more likely to be understood by non-professionals. I beg y'all to not let this devolve into discussions/arguments about programming styles - if you feel you must make those kinds of comments, please start another topic.
This example uses the UUID for a KMFAM macro, so if you use KMFAM, this will run as is in VSCode. Otherwise, change the UUID.
(function() {
'use strict';
ObjC.import('AppKit');
const _kmEditor = Application("Keyboard Maestro");
const _kmEngine = Application("Keyboard Maestro Engine");
// #region ======== Plist Stuff =============================
// These are to work around a bug in VS Code's JSDoc.
// The can be deleted with no adverse affect.
class Plist {}
class nsErrorObject {}
/**
* Returns an error message for an ObjC "nsError" object.
* @param {nsErrorObject} nsError The nsError object.
* @param {string} message Message about the context of the error.
* @returns {string} "message" if nsError can't be decoded, otherwise "{message}. Error: " followed by the decoded error text.
*/
function getErrorMessage(nsError, message) {
try {
return `${message}. Error: ${ObjC.unwrap(nsError.localizedDescription)}`;
} catch (e) {
return message;
}
}
/**
* Returns a plist from an XML string.
* @param {string} xml An XML string to create the plist object from.
* @returns {Plist} The plist object.
* @throws An Error object if the XML can't be converted.
*/
function createPlistFromXml(xml) {
var nsError = $();
var result = ObjC.deepUnwrap(
$.NSPropertyListSerialization.propertyListWithDataOptionsFormatError(
$(xml).dataUsingEncoding($.NSUTF8StringEncoding), 0, 0, nsError));
if (!result)
throw Error(getErrorMessage(nsError, "Could not convert xml string to plist. xml:\n${xml}"));
return result;
}
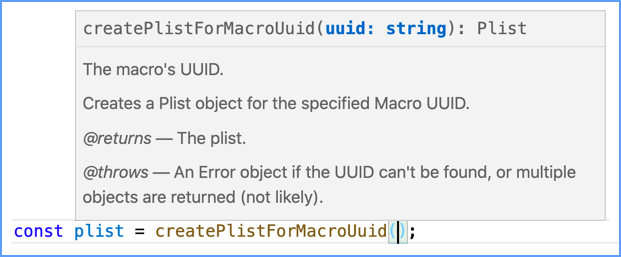
/**
* Creates a Plist object for the specified Macro UUID.
* @param {string} uuid The macro's UUID.
* @returns {Plist} The plist.
* @throws An Error object if the UUID can't be found, or multiple objects are returned (not likely).
*/
function createPlistForMacroUuid(uuid) {
try {
const xml = _kmEditor.macros.whose({id: {"=": uuid}}).xml();
if (xml.length == 0)
throw new Error("Not found")
if (xml.length > 1)
throw new Error(`Expected 1 result, found ${xml.length}`)
return createPlistFromXml(xml[0]);
} catch (error) {
const macroName = _kmEngine.processTokens(`%MacroNameForUUID%${uuid}%`);
throw new Error(`Error trying to create a plist for macro UUID ${uuid} (${macroName}):\n${error.message}`);
}
}
// #endregion
// #region ======== Usage ===================================
const plist = createPlistForMacroUuid("C9E7EDDB-F0D2-4F45-8DCC-A403B74EF347");
console.log(`Created plist for macro "${plist.Name}" (${plist.UID}).`);
console.log(`Number of top-level actions: ${plist.Actions.length}.`);
if (plist.Actions.length > 0) {
const action = plist.Actions[0];
const name = action.ActionName || action.Title || "not defined";
console.log(`First action: MacroActionType: ${action.MacroActionType}; name: "${name}".`);
}
console.log(`\nExamine this JSON to see what the plist property names are:`);
console.log(JSON.stringify(plist, null, 2));
// #endregion
})();
 )
)