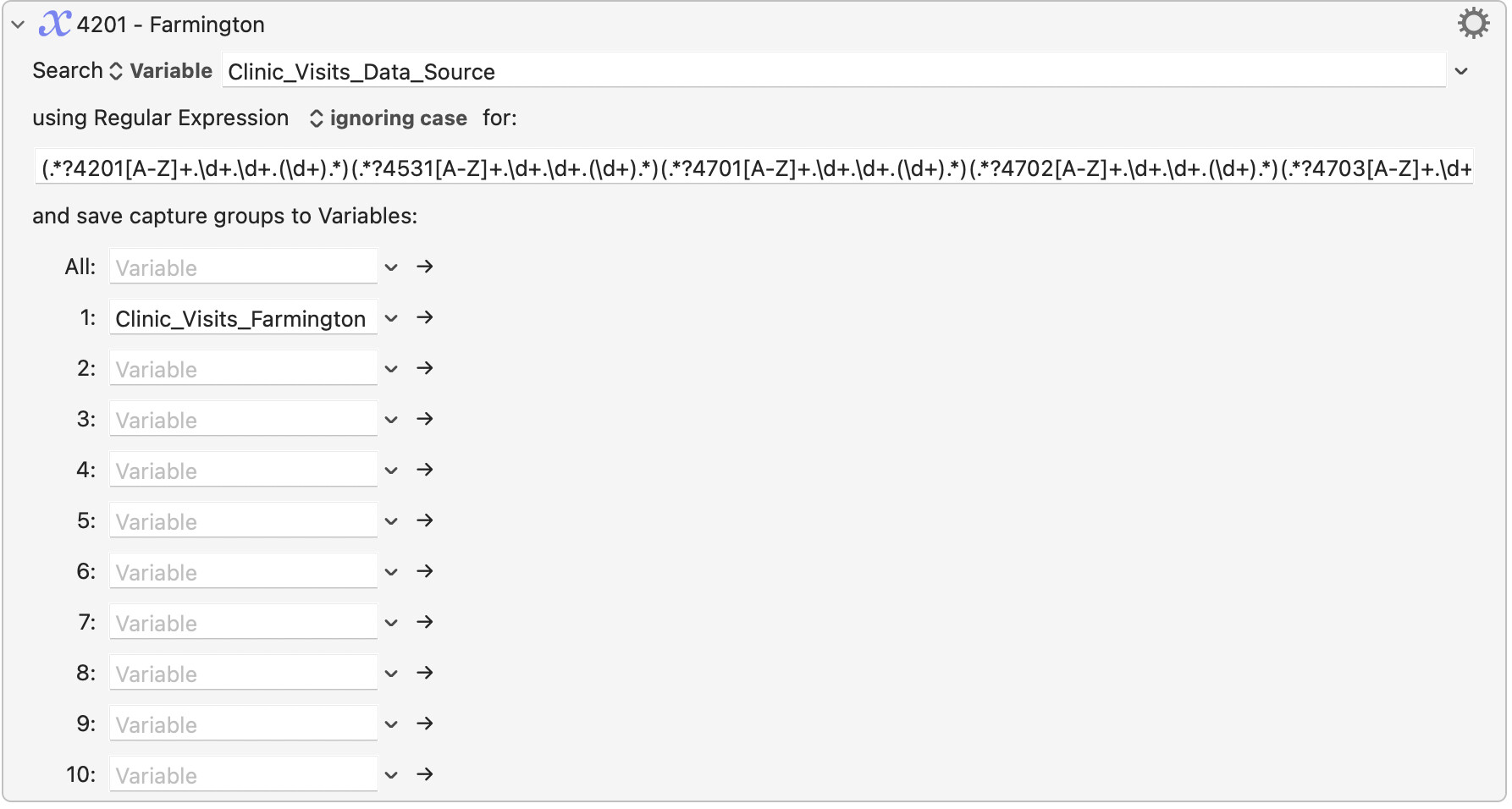
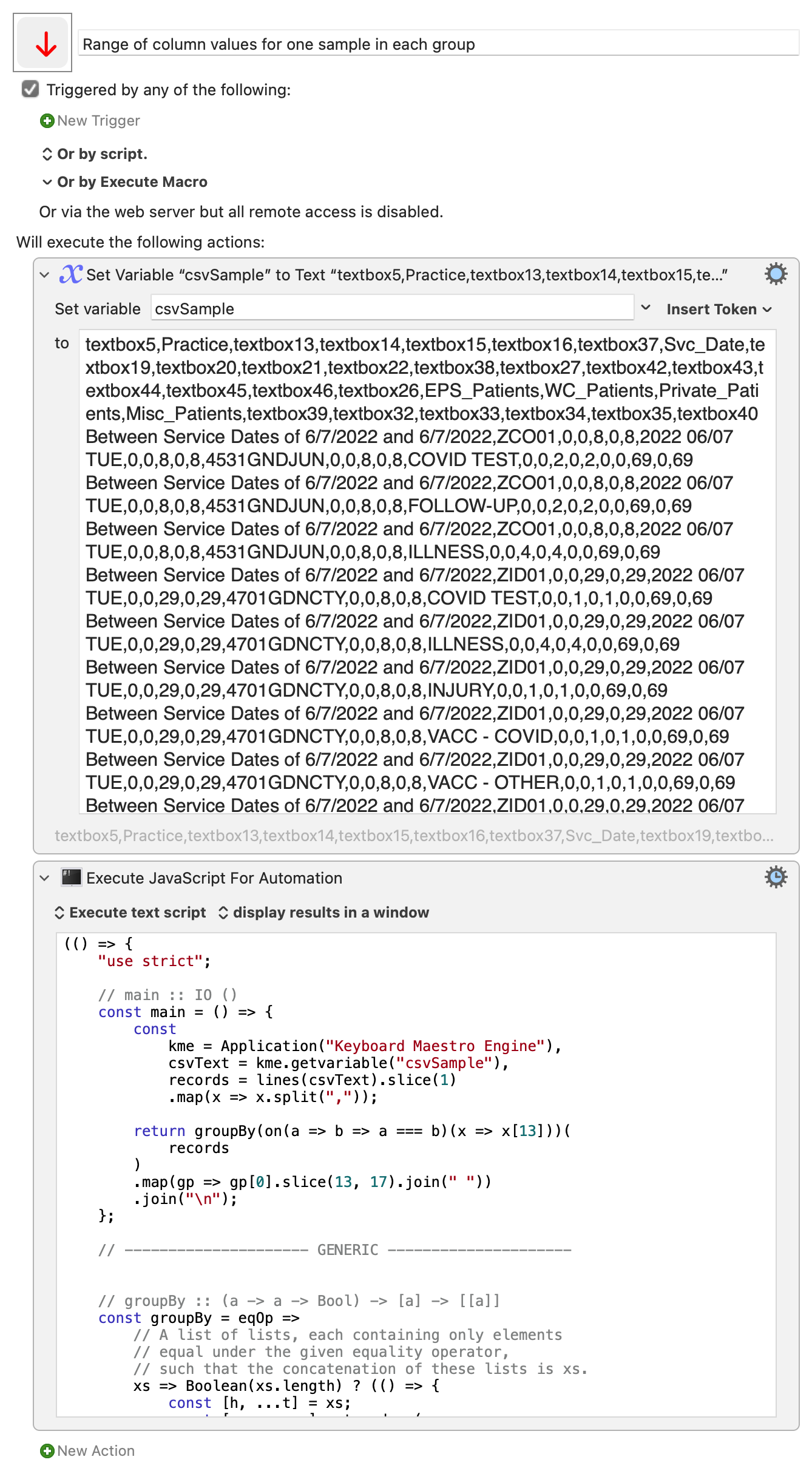
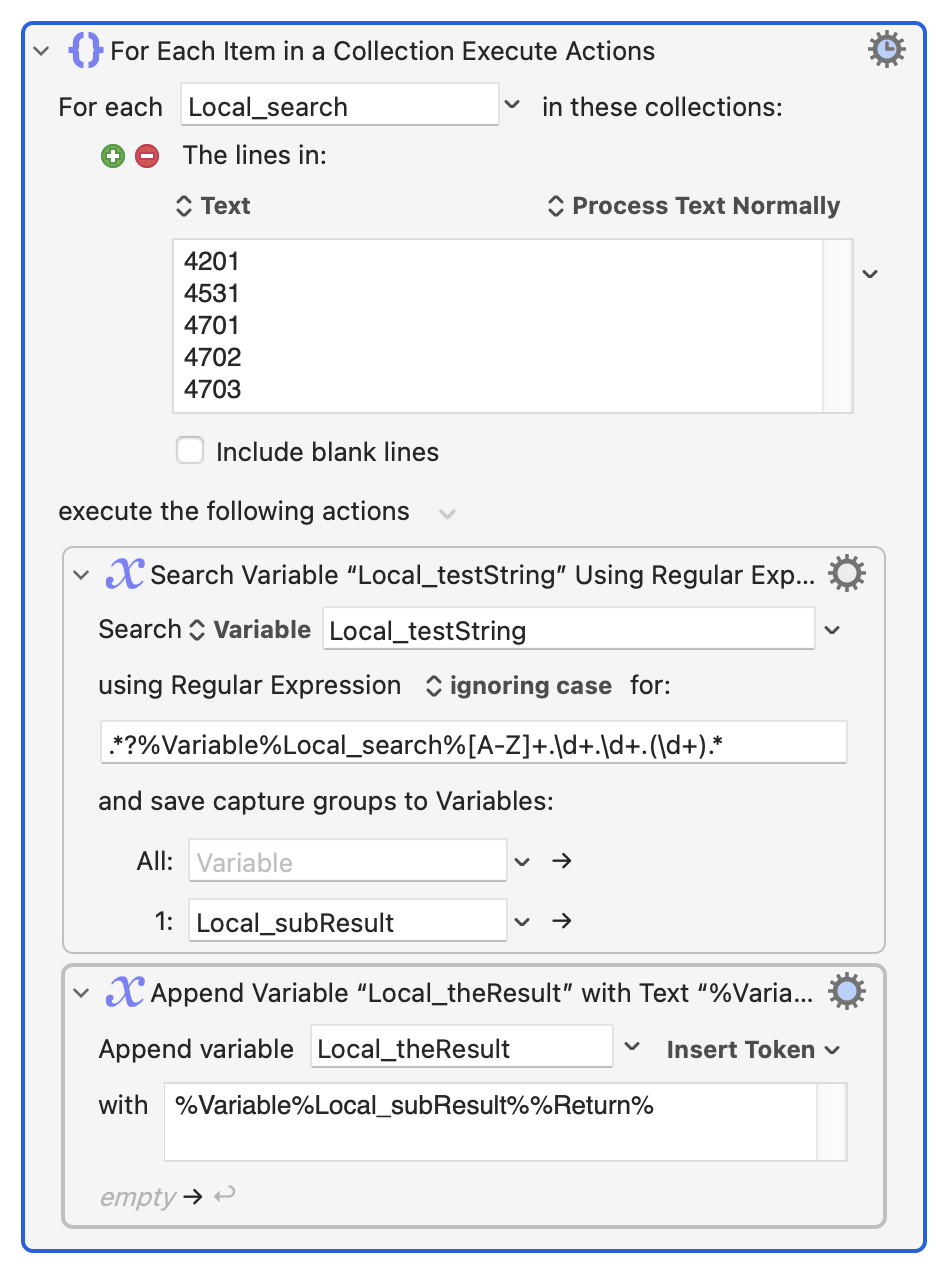
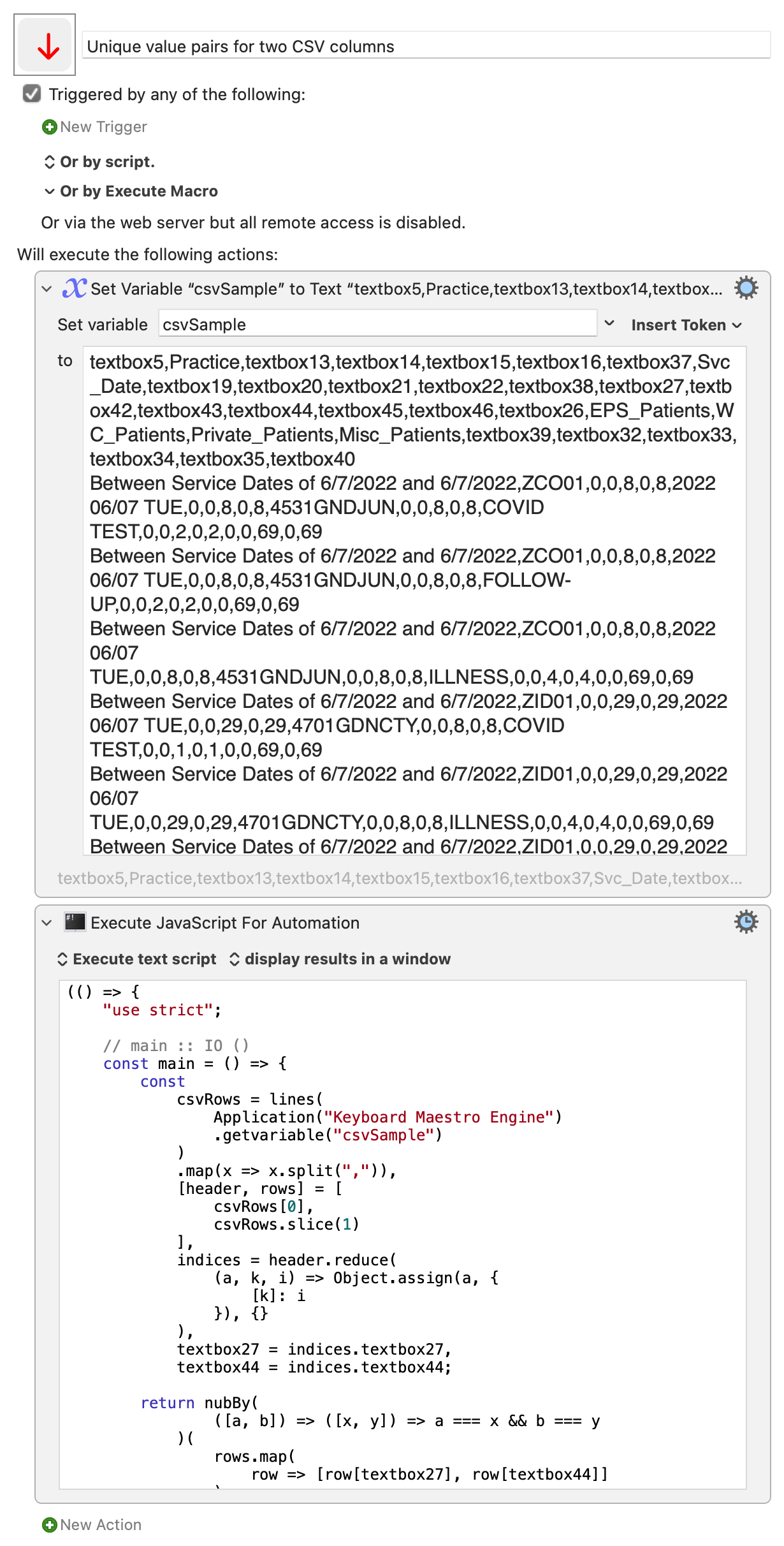
I am attempting to get one instance of each of the following pieces of information...
.?4201[A-Z]+.\d+.\d+.(\d+).
.?4531[A-Z]+.\d+.\d+.(\d+).
.?4701[A-Z]+.\d+.\d+.(\d+).
.?4702[A-Z]+.\d+.\d+.(\d+).
.?4703[A-Z]+.\d+.\d+.(\d+).
...from this text;
textbox5,Practice,textbox13,textbox14,textbox15,textbox16,textbox37,Svc_Date,textbox19,textbox20,textbox21,textbox22,textbox38,textbox27,textbox42,textbox43,textbox44,textbox45,textbox46,textbox26,EPS_Patients,WC_Patients,Private_Patients,Misc_Patients,textbox39,textbox32,textbox33,textbox34,textbox35,textbox40
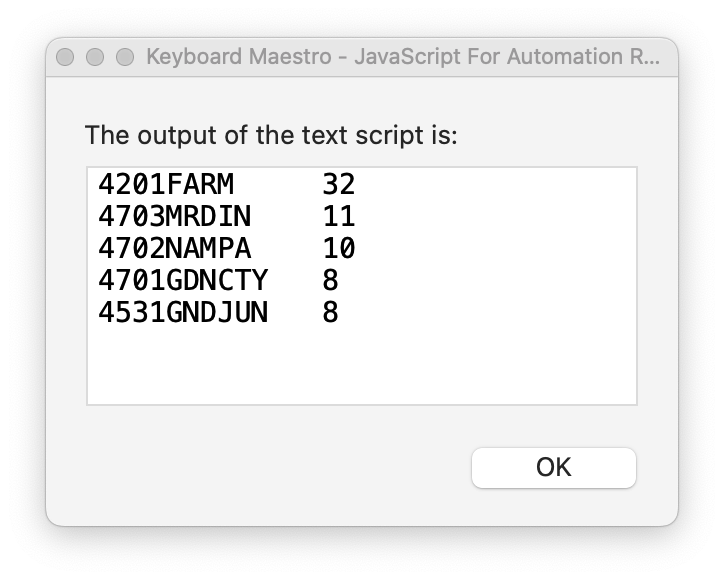
Between Service Dates of 6/7/2022 and 6/7/2022,ZCO01,0,0,8,0,8,2022 06/07 TUE,0,0,8,0,8,4531GNDJUN,0,0,8,0,8,COVID TEST,0,0,2,0,2,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZCO01,0,0,8,0,8,2022 06/07 TUE,0,0,8,0,8,4531GNDJUN,0,0,8,0,8,FOLLOW-UP,0,0,2,0,2,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZCO01,0,0,8,0,8,2022 06/07 TUE,0,0,8,0,8,4531GNDJUN,0,0,8,0,8,ILLNESS,0,0,4,0,4,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4701GDNCTY,0,0,8,0,8,COVID TEST,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4701GDNCTY,0,0,8,0,8,ILLNESS,0,0,4,0,4,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4701GDNCTY,0,0,8,0,8,INJURY,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4701GDNCTY,0,0,8,0,8,VACC - COVID,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4701GDNCTY,0,0,8,0,8,VACC - OTHER,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4702NAMPA,0,0,10,0,10,COVID TEST,0,0,3,0,3,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4702NAMPA,0,0,10,0,10,FOLLOW-UP,0,0,2,0,2,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4702NAMPA,0,0,10,0,10,ILLNESS,0,0,5,0,5,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4703MRDIN,0,0,11,0,11,COVID TEST,0,0,4,0,4,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4703MRDIN,0,0,11,0,11,ILLNESS,0,0,5,0,5,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4703MRDIN,0,0,11,0,11,OTHER,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZID01,0,0,29,0,29,2022 06/07 TUE,0,0,29,0,29,4703MRDIN,0,0,11,0,11,VACC - COVID,0,0,1,0,1,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZNM01,0,0,32,0,32,2022 06/07 TUE,0,0,32,0,32,4201FARM,0,0,32,0,32,(No Category),0,0,0,0,0,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZNM01,0,0,32,0,32,2022 06/07 TUE,0,0,32,0,32,4201FARM,0,0,32,0,32,COVID TEST,0,0,14,0,14,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZNM01,0,0,32,0,32,2022 06/07 TUE,0,0,32,0,32,4201FARM,0,0,32,0,32,ILLNESS,0,0,16,0,16,0,0,69,0,69
Between Service Dates of 6/7/2022 and 6/7/2022,ZNM01,0,0,32,0,32,2022 06/07 TUE,0,0,32,0,32,4201FARM,0,0,32,0,32,INJURY,0,0,2,0,2,0,0,69,0,69
I am doing it with 5 different actions like this...
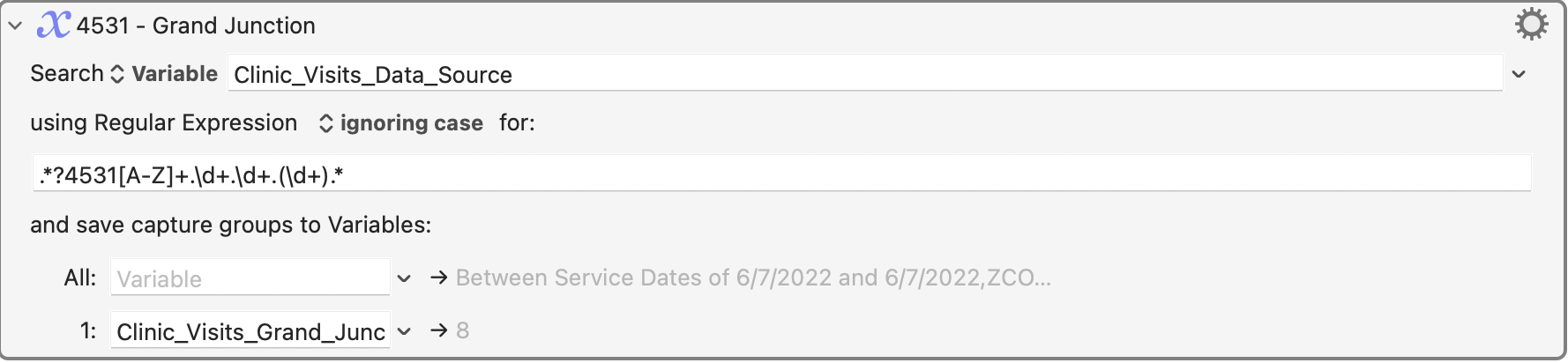
Can it be combined into one?