Near Term Search Macro (v11.0.2)
I'm struggling to get a Keyboard Maestro variable into a Python script. You can help. I think my problem is that the script requires a list type and Keyboard Maestro is supplying a test type.
Is there other information you might need to help?
I'm building a near term search tool that will ask the user for the search terms and the max distance the 2 or more of the terms can be apart.
The distance variable gets passed to the Python script with no problem. The list of searchTerm doesn't. Currently, I'm manually setting the searchTerms variable. The output of the Python Script is piped into a Custom HTML Prompt. This all works when I manually set the searchTerm.
Here is the macro.
Near Term Search.kmmacros (3.8 KB)
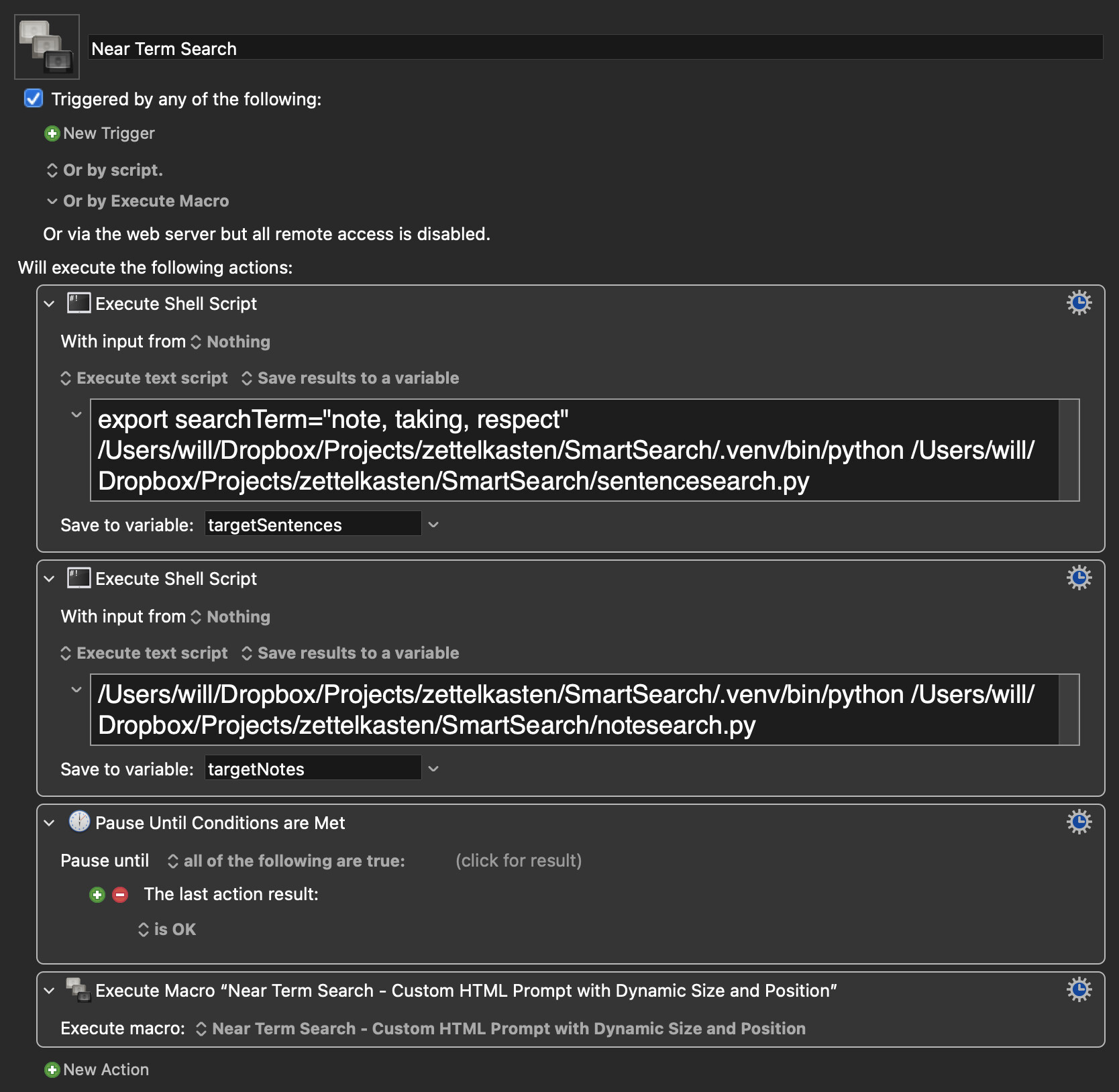
Here is the python
import os
import pathlib
import re
# import json
import pandas as pd
from archive_path import TheArchivePath
zettelkasten = pathlib.Path(TheArchivePath())
def find_matching_files(words, max_distance):
file_links = []
for root, dirs, files in os.walk(zettelkasten):
for file in files:
if file.endswith(".md"):
file_path = os.path.join(root, file)
with open(file_path, "r") as f:
content = f.read()
sentences = re.split(r"[.!?]", content)
for sentence in sentences:
sentence_words = sentence.split()
matching_words = [word for word in words if word in sentence_words]
if len(matching_words) >= 2:
distance = min([abs(sentence_words.index(matching_words[i]) - sentence_words.index(matching_words[i+1])) for i in range(len(matching_words)-1)])
if distance <= max_distance:
file_name = os.path.basename(file_path)
file_link = f"[[{file_name[-15:-3]}]]"
file_links.append((file_link, file_name[:-16], matching_words, distance))
# Sort file_links based on the number of matching words and the distance
file_links.sort(key=lambda x: (-len(x[2]), x[3]))
# Format the links after sorting
file_links = [f'<a href="thearchive://match/›{link}%20{"%20".join(words)}">{file_name} - {distance}</a>' for link, file_name, words, distance in file_links]
# file_links = [f"[{file_name} - {distance}](thearchive://match/›{link} {' '.join(words)})" for link, file_name, words, distance in file_links]
return file_links
if __name__ == "__main__":
search_terms = ["note","taking","respect"]
# search_terms = os.environ.get("searchTerm").split(",")
# search_terms = f'["{os.environ["KMVAR_searchTerm"]}"]'
# search_terms = [f'[{os.environ.get("KMVAR_searchTerm")}]']
# search_terms = json.loads(os.environ["KMVAR_searchTerm"])
# distance = 10
distance = int(os.environ["KMVAR_distance"])
file_links = find_matching_files(search_terms, distance)
# Remove duplicates while preserving order
seen = set()
file_links = [x for x in file_links if not (x in seen or seen.add(x))]
# Create a DataFrame from the file_links list
df = pd.DataFrame(file_links, columns=['File Links'])
# Convert the DataFrame to an HTML table
html_table = df.to_html(escape=False)
print(html_table)
This is what the output should look like
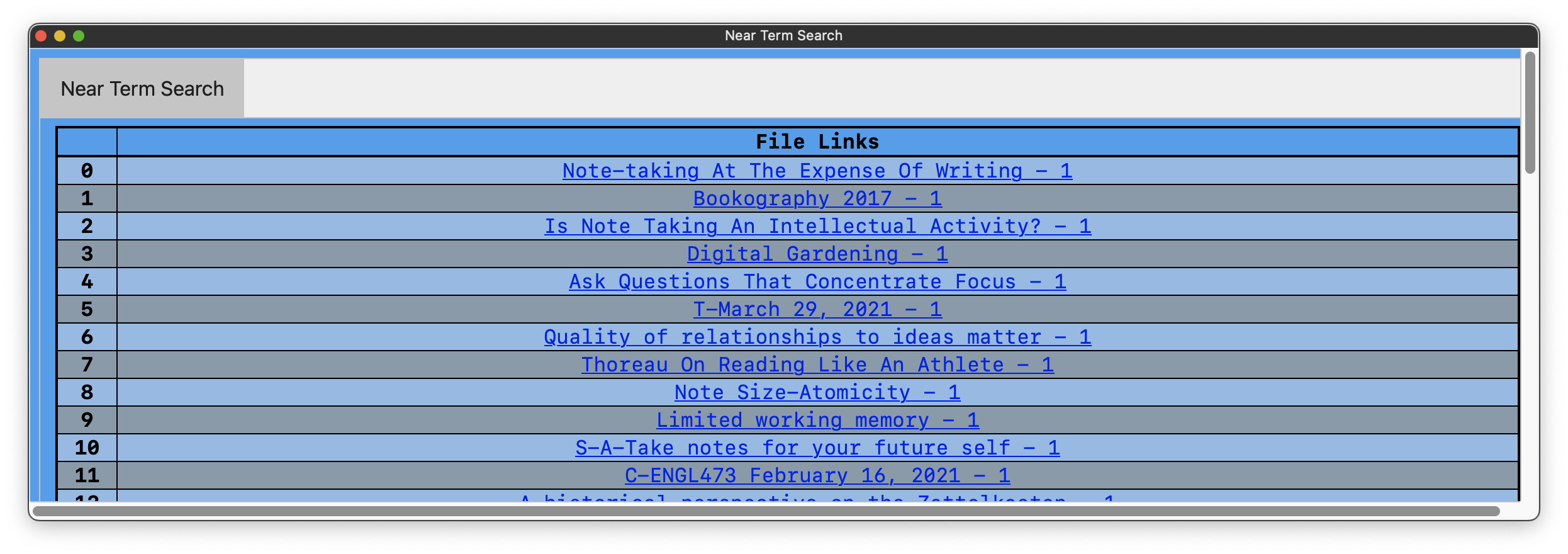
This is what the output looks like what when search_terms = os.environ.get("searchTerm").split(",")