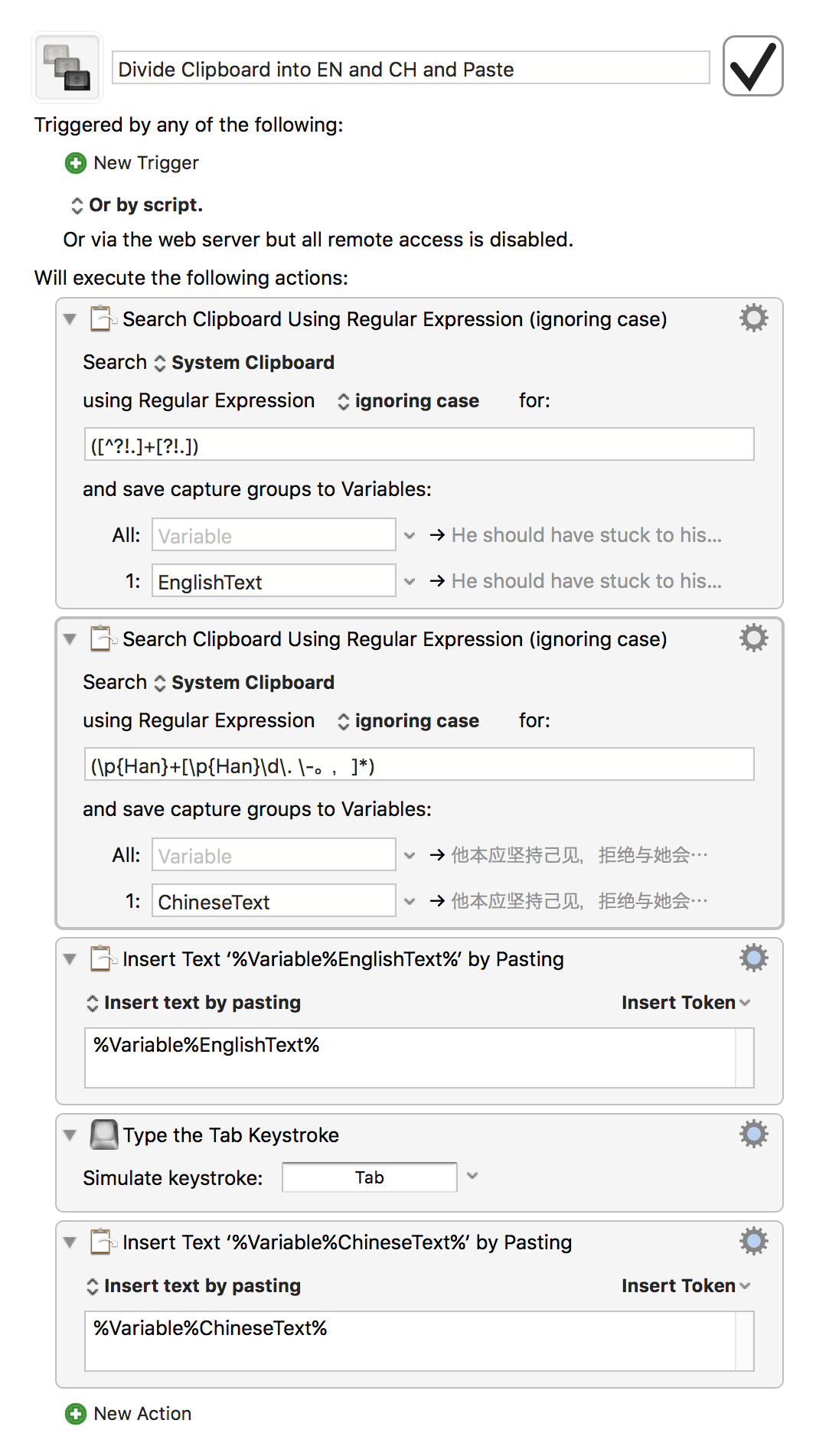
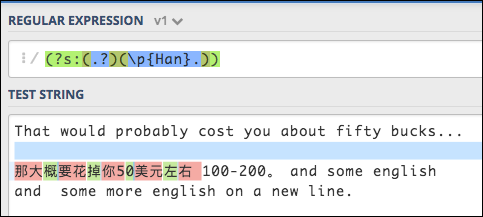
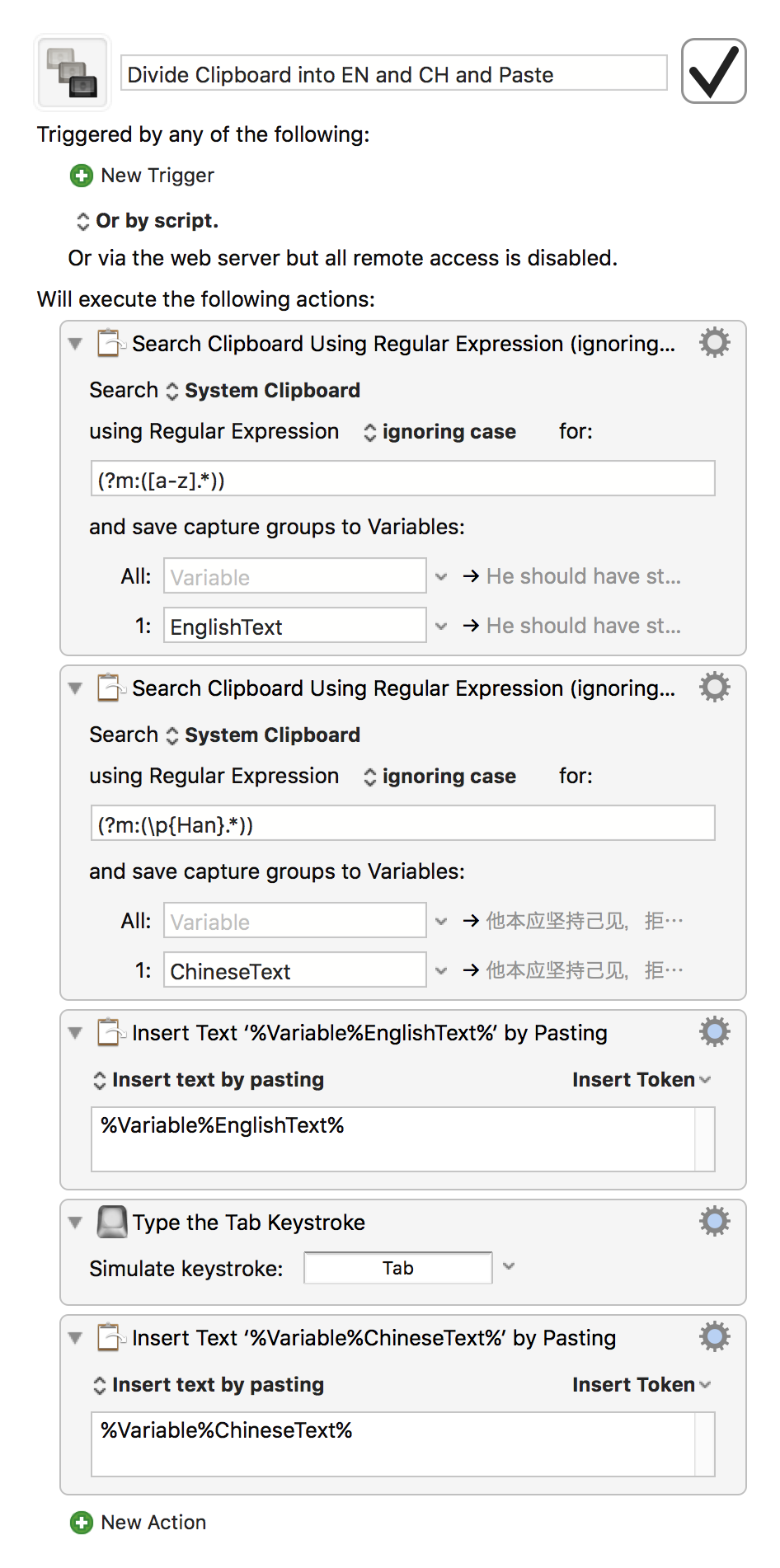
我想用JS就因该有办法吧
// isCJK :: String -> Bool
function isCJK(s) {
var c = s.charCodeAt(0);
return c >= 0x4E00 && c <= 0x9FFF;
};
( Full script for a KM Execute JavaScript for Automation action below )
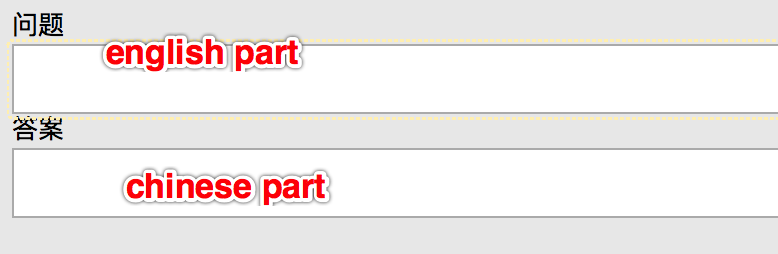
If we copy a string like:
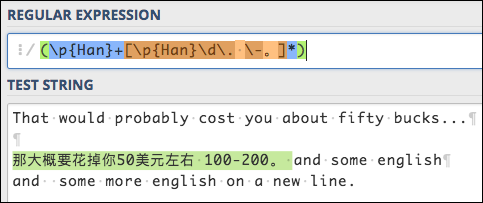
Thank you very much 三块肉给你妈吃
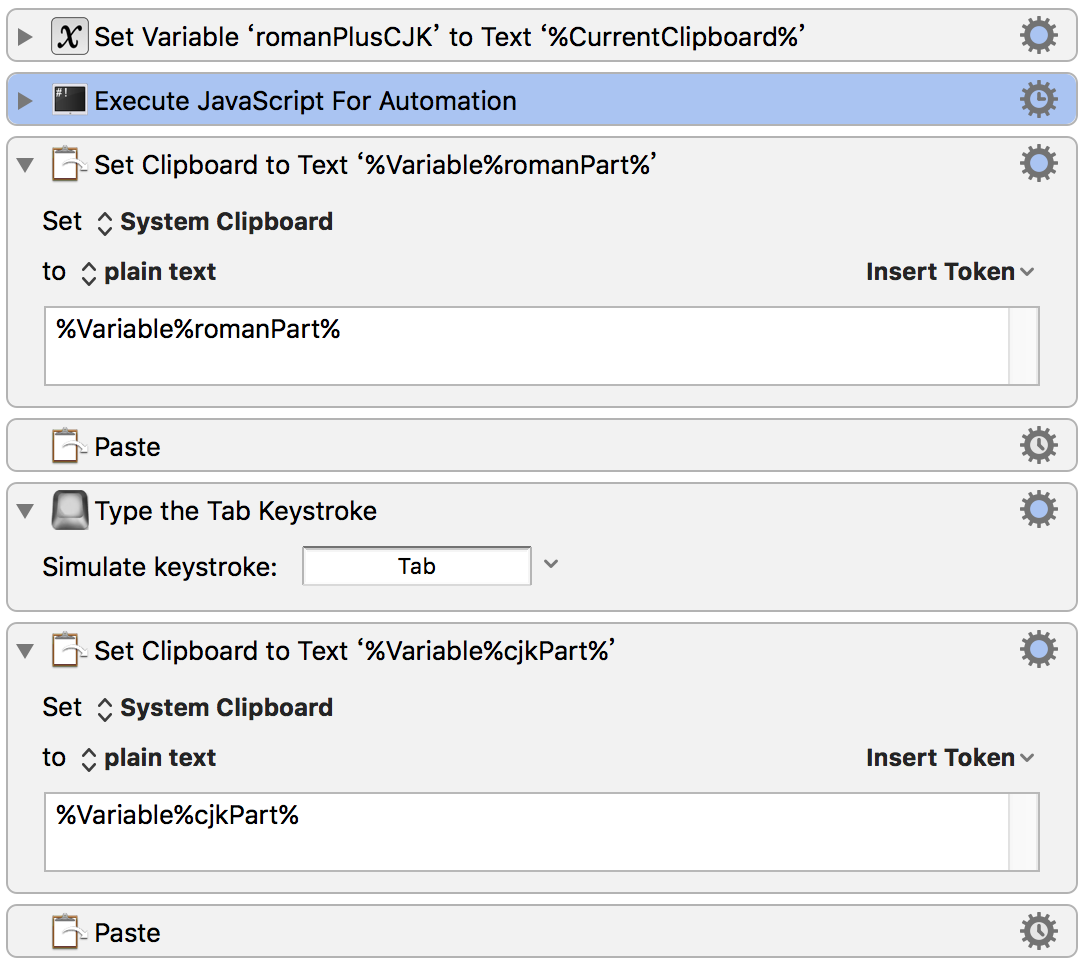
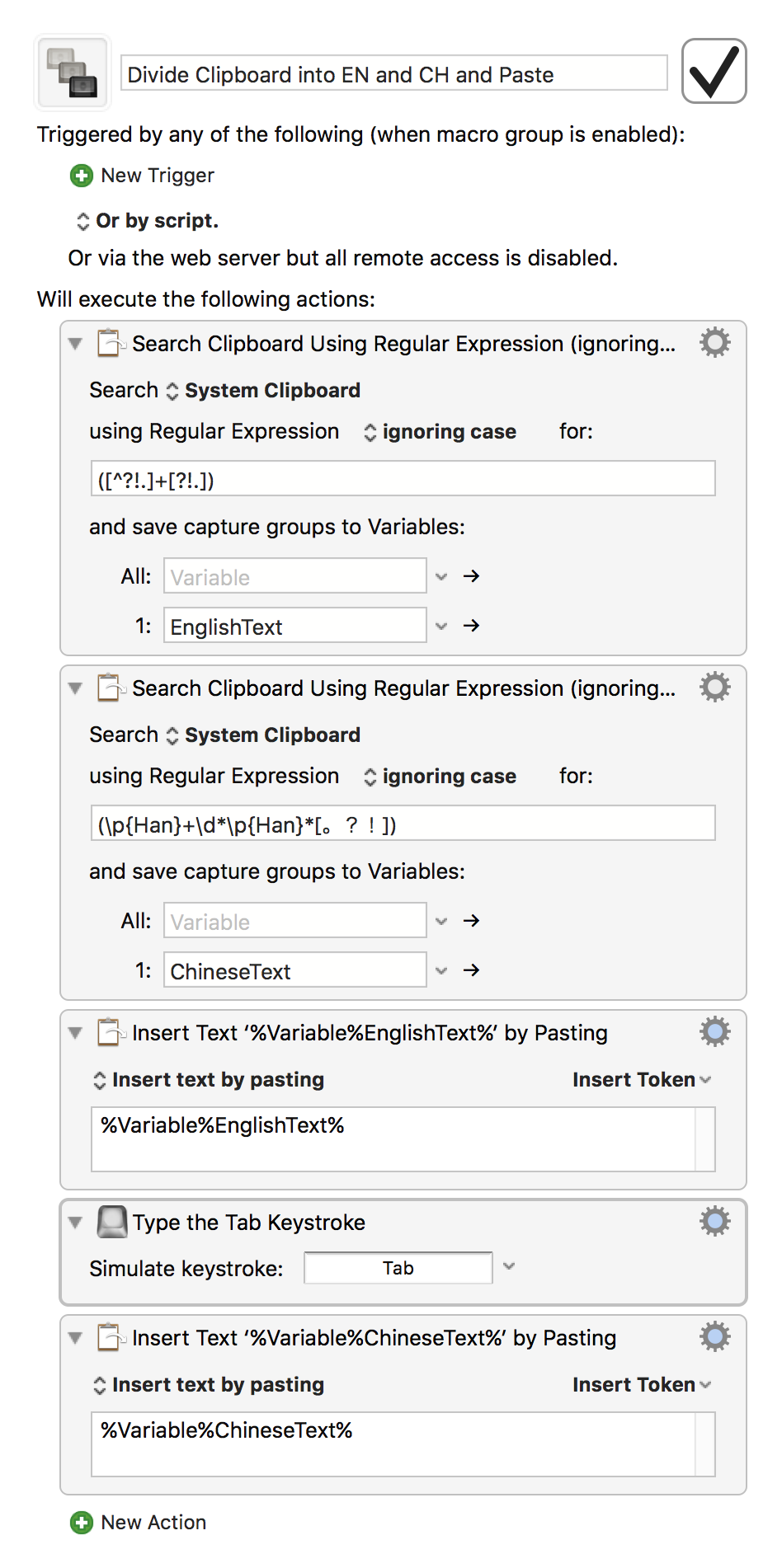
into the clipboard, we should be able to get the two parts into separate KM variables with something like this:
Split clipboard on boundary between Roman and Chinese.kmmacros (23.1 KB)
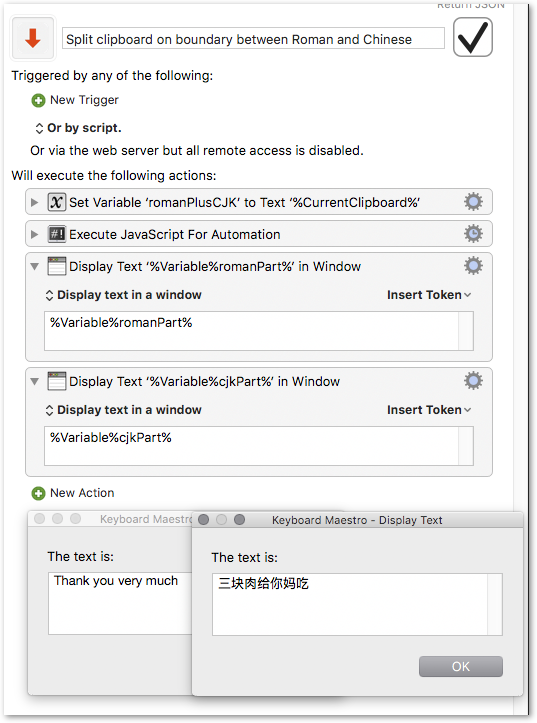
JS ES5 script for the Execute JavaScript for Automation action.
(Note that this version assumes that the English comes first, and is followed by the Chinese - the script would need to be adjusted for the reverse case)
'use strict';
var _slicedToArray = function () {
function sliceIterator(arr, i) {
var _arr = [];
var _n = true;
var _d = false;
var _e = undefined;
try {
for (var _i = arr[Symbol.iterator](), _s; !(_n = (_s = _i.next())
.done); _n = true) {
_arr.push(_s.value);
if (i && _arr.length === i) break;
}
} catch (err) {
_d = true;
_e = err;
} finally {
try {
if (!_n && _i["return"]) _i["return"]();
} finally {
if (_d) throw _e;
}
}
return _arr;
}
return function (arr, i) {
if (Array.isArray(arr)) {
return arr;
} else if (Symbol.iterator in Object(arr)) {
return sliceIterator(arr, i);
} else {
throw new TypeError("Invalid attempt to destructure non-iterable instance");
}
};
}();
(function () {
'use strict';
// SPLITTING ON BOUNDARY BETWEEN 罗马字 and 汉子 ---------------------------
// isCJK :: String -> Bool
function isCJK(s) {
var c = s.charCodeAt(0);
return c >= 0x4E00 && c <= 0x9FFF;
};
// romanHanSplit :: String -> [String]
var romanHanSplit = function romanHanSplit(s) {
return map(function (x) {
return x.join('');
}, splitBy(function (a, b) {
return !isCJK(a) && isCJK(b);
}, stringChars(s)));
};
// GENERIC FUNCTIONS ------------------------------------------------------
// head :: [a] -> a
var head = function head(xs) {
return xs.length ? xs[0] : undefined;
};
// map :: (a -> b) -> [a] -> [b]
var map = function map(f, xs) {
return xs.map(f);
};
// show :: a -> String
var show = function show(x) {
return JSON.stringify(x);
}; //, null, 2);
// Splitting not on a delimiter, but whenever the relationship between
// two consecutive items matches a supplied predicate function
// splitBy :: (a -> a -> Bool) -> [a] -> [[a]]
var splitBy = function splitBy(f, xs) {
if (xs.length < 2) return [xs];
var h = head(xs),
lstParts = xs.slice(1)
.reduce(function (_ref, x) {
var _ref2 = _slicedToArray(_ref, 3),
acc = _ref2[0],
active = _ref2[1],
prev = _ref2[2];
return f(prev, x) ? [acc.concat([active]), [x], x] : [acc, active.concat(x), x];
}, [
[],
[h], h
]);
return lstParts[0].concat([lstParts[1]]);
};
// stringChars :: String -> [Char]
var stringChars = function stringChars(s) {
return s.split('');
};
// TEST -------------------------------------------------------------------
var kme = Application("Keyboard Maestro Engine");
var lstParts = romanHanSplit(
kme.getvariable('romanPlusCJK')
);
kme.setvariable('romanPart', {
to: lstParts.length > 0 ? lstParts[0] : ''
});
kme.setvariable('cjkPart', {
to: lstParts.length > 1 ? lstParts[1] : ''
});
return show(lstParts);
})();