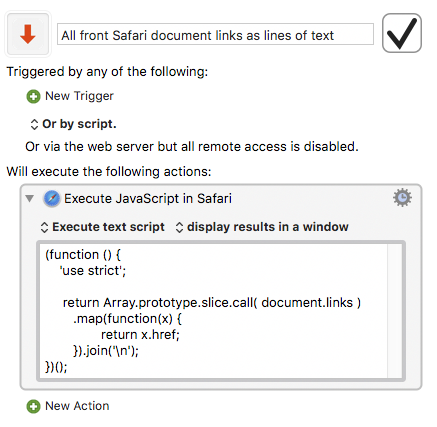
I want to collect all links on the current browser page that match a regular expression (or just all the links — I can handle the regular expression). Ideally I could choose between text, HTML, RTF, and Markup, but would be content with putting RTF on the clipboard.
Really, I just need the URLs of the links themselves, but better would be the title and URL, and any kind of simple text format would be fine.
Working with any one browser is fine (preferably Safari, as standard), but Safari, Chrome, and Firefox ideal. (I know that Firefox cannot be driven from KM nor scripted from AS.)
I have read a number of pages related to this, many with very long discussions and proposed macros, and I'm sure there are lots more. The ones I read include:
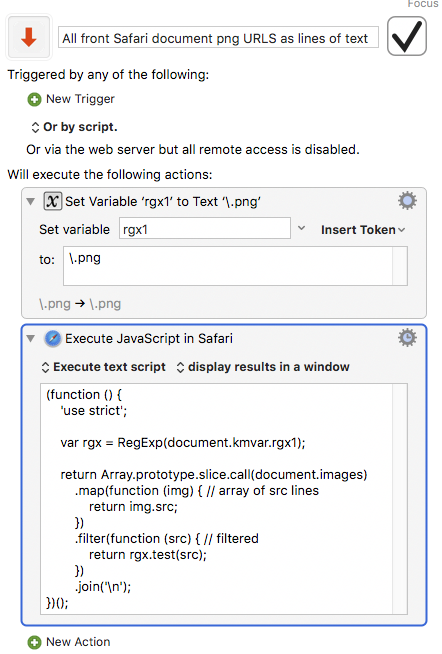
(or, of course, reverse the composition of filter and map, which seems likely to reduce space but increase time – a little more traffic in the repeated fetching across img.src)
(function () {
'use strict';
var rgx = RegExp(document.kmvar.rgx1);
return Array.prototype.slice.call(document.images)
.filter(function (img) { // shorter array of image objects
return rgx.test(img.src);
})
.map(function (img) { // translated to their texts
return img.src;
})
.join('\n');
})();
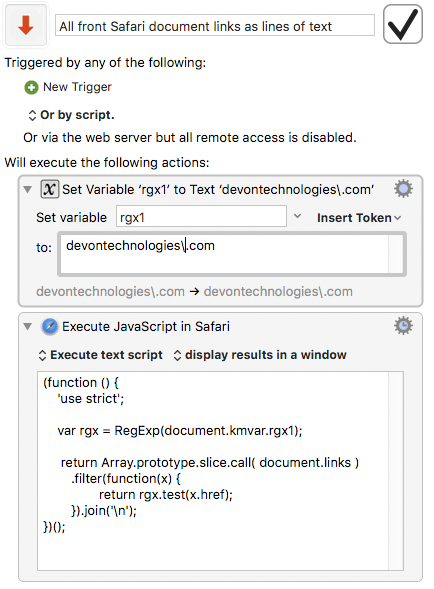
Yes, thanks, that works. I have to study this some more, though, especially the slice.call part of it. As it turns out in your original code you can omit the .href, which I don’t understand at all but probably illuminates why my .src doesn’t get me the image’s link.
It finds it, of course, for the purpose of the filtering decision, but functions which are arguments to .filter are interpreted simply as predicates - whatever they return is just evaluated as a boolean – on which inclusion or exclusion turns.
(and Regex.test() is in any case a predicate function - it just returns a boolean expressing the presence or absence of a match)
Fixed a couple minor problems with more modern versions of Safari.
Hey Mitchell,
Rob's code is nice and compact.
Here's what I've used for nearly a decade:
--------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2016/11/13 17:45
# dMod: 2019/07/07 11:16
# Appl: Safari
# Task: Extract Links from the front Safari document with optional RegEx filter.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Safari, @Extract, @Links, @Front, @Document
--------------------------------------------------------
# PROTOTYPE:
# safari_links(regexStr, tagName, tagAttribute)
# HREF:
set linkList to safari_links(".*", "a", "href")
# SRC:
set linkList to safari_links(".*", "img", "src") of me
# FILTERED SRC:
set linkList to safari_links("\\.(bmp|jpe?g|png|gif)", "img", "src") of me
--------------------------------------------------------
--» HANDLERS
--------------------------------------------------------
-- dMod: 2010/12/30 01:00
-- dMod: 2016/11/13 17:51 – Cleaned up the code just a little.
-- Task: Get Links from Safari Using Javascript and a Regular Expression
--------------------------------------------------------
on safari_links(regexStr, tagName, tagAttribute)
set javascriptCMD to "
(function () {
function in_array (array, item) {
for (var i=0; i < array.length; i++) {
if ( array[i] == item ) {
return true;}}
return false;}
var a_tags = document.getElementsByTagName('" & tagName & "');
var href_array = new Array();
var reg = new RegExp(/" & regexStr & "/i);
for (var i=0; i < a_tags.length; i++) {
var href = a_tags[i]." & tagAttribute & ";
if ( reg.test(href)) {
if ( !in_array(href_array, href)) {
href_array.push(href);}}}
// Filter-out empty items from the link list.
var jsOutput = href_array.join('\\n');
jsOutput = jsOutput.replace(/\\s+/g, '\\n').split('\\n');
return jsOutput;
})();
"
try
tell application "Safari" to set linkList to do JavaScript javascriptCMD in document 1
if linkList = missing value then set linkList to {}
on error
set linkList to {}
end try
return linkList
end safari_links
--------------------------------------------------------
I have the handler in a library, so all I have to do is emplace one line of code with a Typinator abbreviation:
This is wonderful — concise, flexible, and already debugged.
One suggestion: puzzling out what tagType means tripped me up briefly. Your IMG examples make it pretty clear what it is, but I made sure by looking at the code. I think a more appropriate name would be tagAttribute, although that leaves a bit of ambiguity: does it mean the attribute‘s name or its value, so technically it should be tagAttributeName, or perhaps the slightly shorter attributeName.