I think it's worthwhile to dig in and learn how to use RegEx. When I need it I often search and find code online. I want to move past merely copying into 'creating'.
Where's the best place to tackle this? I don't see any courses listed at the local college. There are thousands of online tutorials online. Anyone know of some good ones that helped them?
I'll wait for Chris (@ccstone) to jump here. He is the master, and has a great list of resources.
But I will say this: It is NOT easy, and it is a subject like learning a foreign language, that you have to stick with and use on a daily basis until you have grasped the fundamentals. Like math, only worse, if you don't use it, you lose it.
Speaking of which, hey Chris, how about providing a RegEx course for fee? We could all learn so much.
I think he’s got a good idea going. I have Text Wrangler so I dove right in. Next came reality. There is a steep learning curve on this stuff.
@ccstone, Good suggestion. I also went and picked up an O’Reilly book. Maybe I should have just renewed my Safari Books subscription but the book was cheaper.
Honestly, I think regular expressions look more difficult that they are. Partly this is because they are easier to write than to read, although that tends to make learning them tricky.
Regular expressions are a lot like Keyboard Maestro - the basics are easy to learn, and then each new concept adds to all the rest.
Just like macros are made up of a sequence of actions, regular expressions are a sequence of tokens, and just like there are lots of different kinds of actions, there are lots of different kinds of regular expression tokens. These are all referenced via the Keyboard Maestro Help menu to the ICU Regular Expression documentation.
The simplest token is just a character like a letter or number which just matches itself (possibly case sensitively, possibly not).
Common other ones are ^ (matches the start of the line or text), $ (matches the end) and “.” which matches any character. Another common token is the [pattern] (eg [a-zA-Z0-9] matches any letter or number). You can also use brackets to group together a sequence of tokens into a single token.
After a token you can have an an operator like * which means “zero or more of the preceding thing” or + which means “one or more of the preceding thing”.
So for example:
^(abc)+$
matches text that is one or more sequences of abc ant nothing else (like abcabcabcabc).
Now sure, there are lots of tokens, lots of operators, lots of expressions, and then there are flags which let you change some behaviour (like case sensitivity), but still, the basic concepts are pretty straight forward and you can learn more as you go, and get a lot of value knowing only a few of them.
Heh! I am waiting for that “Oh THAT’S all it is?” moment to hit me. I shall continue reading the cheatsheet TextWrangler has and see if the “Aah HA!” light switches on. Onward through the fog!
Yes. I see what you mean. Trying to decode expressions does seem a lot more difficult then breaking out a cheat sheet and attempting to type code. I think I just need to wrap my head around the rules. e.g. "A "+" sign applies to the preceding token", or "letters between brackets don't need spaces thus placing small z next to A is ok as in: a-zA-Z"
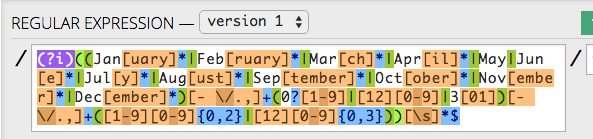
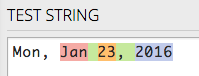
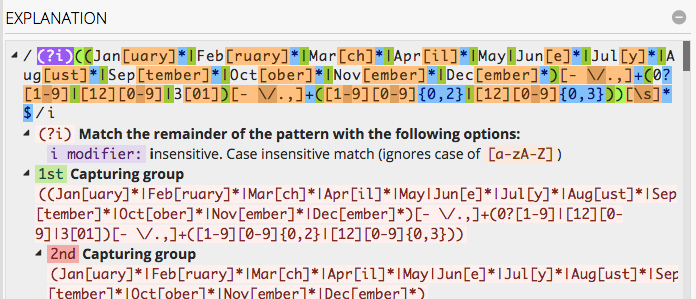
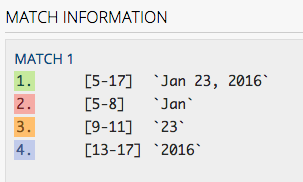
Get a tool like RegexMatch or the like that lets you test out regular expressions with clear results of the matches and groups. That way you can quickly see what the difference between different patterns is.
It is very fast to respond to changes in both the RegEx pattern, and in your test string.
It has great color coding and provides lots of details to help:
Pretty slick tool JMichael. Wish they had that in an app you could download to your computer. I wonder what the risks would be if I am working on stuff that includes personal info, account IDs, and such?
Probably little, but I would never put such stuff in a web page. What you might be able to do is convert all letters to "a" and all numbers to "2" which would generally not change the regex you are going to use, but would remove all confidential information.
Search and Replace [a-zA-Z] with "a" and [0-9] with "2".
Depending on exactly what kind of information and what regex you are testing, this might anonymize it. And it may also help you think of the problem in a more general way if the details are removed.
Just use dummy data to develop/test the RegEx.
Then you could use other tools, like TextWrangler, to test on real data.
OR, just download the app Peter recommended.
TextWrangler is really a great app, and it is FREE! I use it all the time, The Find and Replace is awesome, both for normal search and RegEx search/replace.
Chris I have been away for a bit so I am just seeing these now. I will definitely put these on the wish list. I am finally able to get my head wrapped around RegEx a bit. I also took on learning Swift. (Well looking into it at least). Day by day I get better.
StackOverflow.com is also a great place for answers. You often get quick response to questions you post.
As for learning RegEx, I’ve found that immersion is the only way I could learn it. If the times I used it were too far between, I just couldn’t remember what was going on. But the more I use regex, the more useful it becomes, so I use it more, etc.
To that end, I recommend using regexes on a regular basis with your favorite text editor that supports them. Any time you have to find something that requires any sort of searching other than straight “contains”, figure out how to do it in the text editor. This includes even simple things that you could eyeball a normal search’s results to get your answer - the more you use it, the more you learn. Start small and work your way up.
Even tools like “A Better Finder Rename” support regexes. http://www.publicspace.net/ABetterFinderRename/. So if you need to rename a group of files, this is another place to keep learning.
Tools like that are invaluable, not just for beginners but for anyone trying to construct expressions that are just a little beyond their current competence or to debug expressions that aren't working right.
Other online tools have come and gone. None of the ones I used to use are still up. But a [web search for interactive "regular expression" will get you other interactive tools and some teaching sites. For example, Build Regex - A Simple RegEx GU looks interesting.