I am trying to extend this to handle multiple sets of source data e.g.
Name: Text 1 for Name
Address: Text 2 for Address
EMail: Text 3 for EMail
Phone: Text 4 for Phone
Name: Text 5 for Name Text 5.1 for Name
Text 5.2 for Name
Text 5.3 for Name
Address: Text 6 for Address
EMail: Text 7 for EMail
Phone: Text 8 for Phone
And my data set is unpredictable e.g. the above has 2 records but there may be any number of records.
(Note – My “Text 5 for Name” is a paragraph of text with line breaks.)
I’m not sure of how to process this (Regex changes?) and not sure how to structure my Dictionaries (are there multiple?).
Also:
– How/where are your Variables deleted in your macro? They don’t seem to be visible in my KM Variables list?
– After running the macro, is there a list of my Dictionaries and their content in KM?
While KM does a good job of handling simple dictionaries, it is not well suited for complex array of dictionaries. JXA can do this much better, and much easier.
I'd suggest that you discuss the complete scope of your task/project, and then we can suggest some good choices for implementing it.
They are automatically deleted because they are "Local" Variables , and as a result are NOT in the KM Variables list.
Yes.
It is not as well structured as KM Variables, you can see them in your token: KM Editor menu Edit > Insert Tokens > Dictionary.
Anywhere you have an Action that accepts text/tokens, you can insert a Dictionary token to display the value for key.
I’m trying to read into KM a text file containing an unpredictable number of records with fields (structured similar to my source file above). Then I want to write out certain fields to an RTF file and format certain of its fields as Bold Text. (Similar to a very simple database report writer).
e.g. Scenario:
read in 4 address records from 1 text file (each record contains fields: Name, Address, Phone, Email, Notes)
write 4 text files each containing: Name (bolded) + Blank Line + Notes
I can think of 2 complicated ways to do this. e.g.
#1 – have KM split my source file using Regex (?) into 4 Source Files. For Each of the 4 source files, load up variables and write those to a target file then iterate.
#2 – create variables on the fly in KM by incrementing. e.g. creating Name1, Name2, Name3, etc variables on the fly based on how many records KM finds. When the entire source file has been processed and all variables have been created and loaded then write out to 4 target files.
Can you please provide a real-world example file of your source data, and the corresponding output files. Try to make the source data model the wide range of possible data and formats to cover all potential cases.
I would tend to go with #1, but reserve judgement until I've seen your real-world data. If it is easy to split into blocks of text corresponding to records, then a repeat loop to process each would be one approach.
After the task is done, after one execution of the Macro, do you need to retain any data for future use? If so, how will you use it?
Don’t need the data retaining for future use after KM has created the target files. (Would be nice but seems overkill – and more suited to a DBMS solution).
SAMPLE SOURCE TEXT FILE:
Slightly different from my description above but same in principal.
“Date” field’s data is optional
Could end each record with a specific field something like ### if necessary (to indicate “end of record”).
If “Level 2/3” is 2 then I will BOLD the “Place” data when I write it to the target file. If it is 3 then I will ITALICIZE the “Place”.
2 records in source file will result in 2 target files (RTF’s) being created. I won’t know the number of records in the source file prior to execution.
=====================
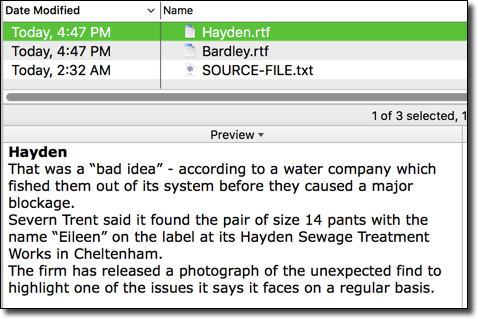
Place: Hayden
Level 2/3: 2
Notes: That was a “bad idea” - according to a water company which fished them out of its system before they caused a major blockage.
Severn Trent said it found the pair of size 14 pants with the name “Eileen” on the label at its Hayden Sewage Treatment Works in Cheltenham.
The firm has released a photograph of the unexpected find to highlight one of the issues it says it faces on a regular basis.
Category: 10_AAAA
Date: 18 April 2018
Thanks, but I was expecting an actual file.
Please create a zip file with:
A actual source file
sanitize if need be, but just replace characters
Be careful to not delete any lines or special characters (like TABs)
One RTF file for each target file you create from the source file.
That would be great!
We need a way of always knowing the START of each record, and the END of each record in the source file.
Is the Start ways with "Place:" at the beginning of a line?
Are there any lines before the first record, or after the last record that are unused?
MACRO: Extract Records/Fields from Text File & Output to RTF Files [Example]
#### DOWNLOAD:
<a class="attachment" href="/uploads/default/original/3X/8/4/844164aa7ed305f0a018a1709522338aa8d28c8c.kmmacros">Extract Records-Fields from Text File & Output to RTF Files [Example].kmmacros</a> (45 KB)
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---
### ReleaseNotes
Author.@JMichaelTX
**PURPOSE:**
* **Extract Blocks of Text from File as Records**
* and Output as RTF Files
**REQUIRES:**
1. **KM 8.2+**
* But it can be written in KM 7.3.1+
* It is KM8 specific just because some of the Actions have changed to make things simpler, but equivalent Actions are available in KM 7.3.1.
.
2. **macOS 10.11.6 (El Capitan)**
* KM 8 Requires Yosemite or later, so this macro will probably run on Yosemite, but I make no guarantees. :wink:
**NOTICE: This macro/script is just an _Example_**
* It has had very limited testing.
* You need to test further before using in a production environment.
* It does not have extensive error checking/handling.
* It may not be complete. It is provided as an example to show you one approach to solving a problem.
**How To Use**
1. Create Source Text File
* Each Record (text block) must:
* Start with "Place:"
* End with "###:"
2. Make sure Source and Output Folders are set in Macro
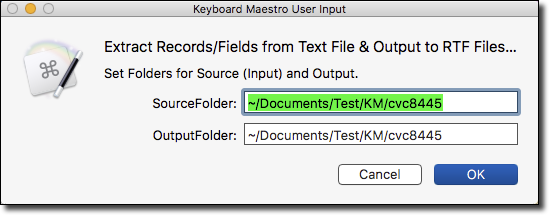
3. Trigger this macro.
* It will then ask for Source file
* Extract a Record and Fields
* Output a RTF File
* for each Record found in file
* Open Output folder in Finder
**MACRO SETUP**
* **Carefully review the Release Notes and the Macro Actions**
* Make sure you understand what the Macro will do.
* You are responsible for running the Macro, not me. ??
.
1. Assign a Trigger to this maro..
2. Move this macro to a Macro Group that is only Active when you need this Macro.
3. ENABLE this Macro.
.
* **REVIEW/CHANGE THE FOLLOWING MACRO ACTIONS:**
(all shown in the magenta color)
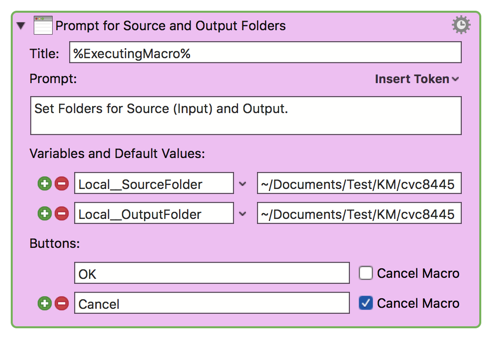
* Prompt for Source and Output Folders
TAGS: @RegEx @Extract @Records @Fields @RTF @Files @Example
USER SETTINGS:
* Any Action in _magenta color_ is designed to be changed by end-user
ACTION COLOR CODES
* To facilitate the reading, customizing, and maintenance of this macro,
key Actions are colored as follows:
* GREEN -- Key Comments designed to highlight main sections of macro
* MAGENTA -- Actions designed to be customized by user
* YELLOW -- Primary Actions (usually the main purpose of the macro)
* ORANGE -- Actions that permanently destroy Variables or Clipboards,
OR IF/THEN and PAUSE Actions
**USE AT YOUR OWN RISK**
* While I have given this limited testing, and to the best of my knowledge will do no harm, I cannot guarantee it.
* If you have any doubts or questions:
* **Ask first**
* Turn on the KM Debugger from the KM Status Menu, and step through the macro, making sure you understand what it is doing with each Action.
---

This is really excellent JMichaelTX. Works like a charm.
Has great error checking subroutines as well.
Regarding the 2 Regex’s. I have some Regex experience but find it very difficult. regex101.com and their IRC channel was helpful to me in the past but still not confident at all. Can you explain how you coded these? i.e. what process did you follow? have you memorised much of the syntax or do you use some “trick” to develop the Regex code?
Regarding the 2 RTF output files. If I wanted to have DOCX output files instead of RTF? And e.g. have “Hayden” not “bolded” but set to Style = Heading 1 inside the DOCX – does KM have the ability to write to DOCX and to set a DOCX Style? Thanks.
I have found RegEx to be the epitome of "use it or lose it". While I use RegEx often for my own personal use, much of it is in response to questions like yours. So I was able to create the RegEx patterns for this macro from memory.
I make great use of RegEx101.com. I do all of my RegEx development and testing there. And even for "simple" RegEx patterns, which I think I know, I always test them there first before using/publishing.
Pretty much everything there is very common RegEx. Perhaps less common is use of the s flag in (?ms). This makes the dot meta character match newlines as well.
One tip is that sometimes it is easier to use multiple passes of RegEx rather than trying to do everything in one large RegEx. In this case it really made sense to do a simple RegEx to extract the block of text (as "record"), then use another RegEx to extract the fields from that block.
If you have any specific questions, I'd be glad to try to answer.
I assume you mean MS Word ".docx" files, which are actually text XML files. That would be more challenging, and maybe even an entirely different approach. However, one simple workaround is to simple use a ".docx" extension when you save the file. Then when you open it in Word, Word will prompt to convert from RTF.
That is a lot more complex. KM can write any file, but you have to built the contents. So, one approach would be to build a Word .docx file, and then open it up in a text editor to find where the heading is applied. If you use a placeholder, like "[[PLACE]]", then you could use KM to replace the placeholder with the actual data, and then write that out to a file with a .docx extension.
That is all very much just an idea/theory, as I have not actually done any of that. And, it is, of course, left as an "exercise for the student".