How do I Remove Blank Lines with Regex?
I found a couple posts on the forum and followed the suggestions to no avail.
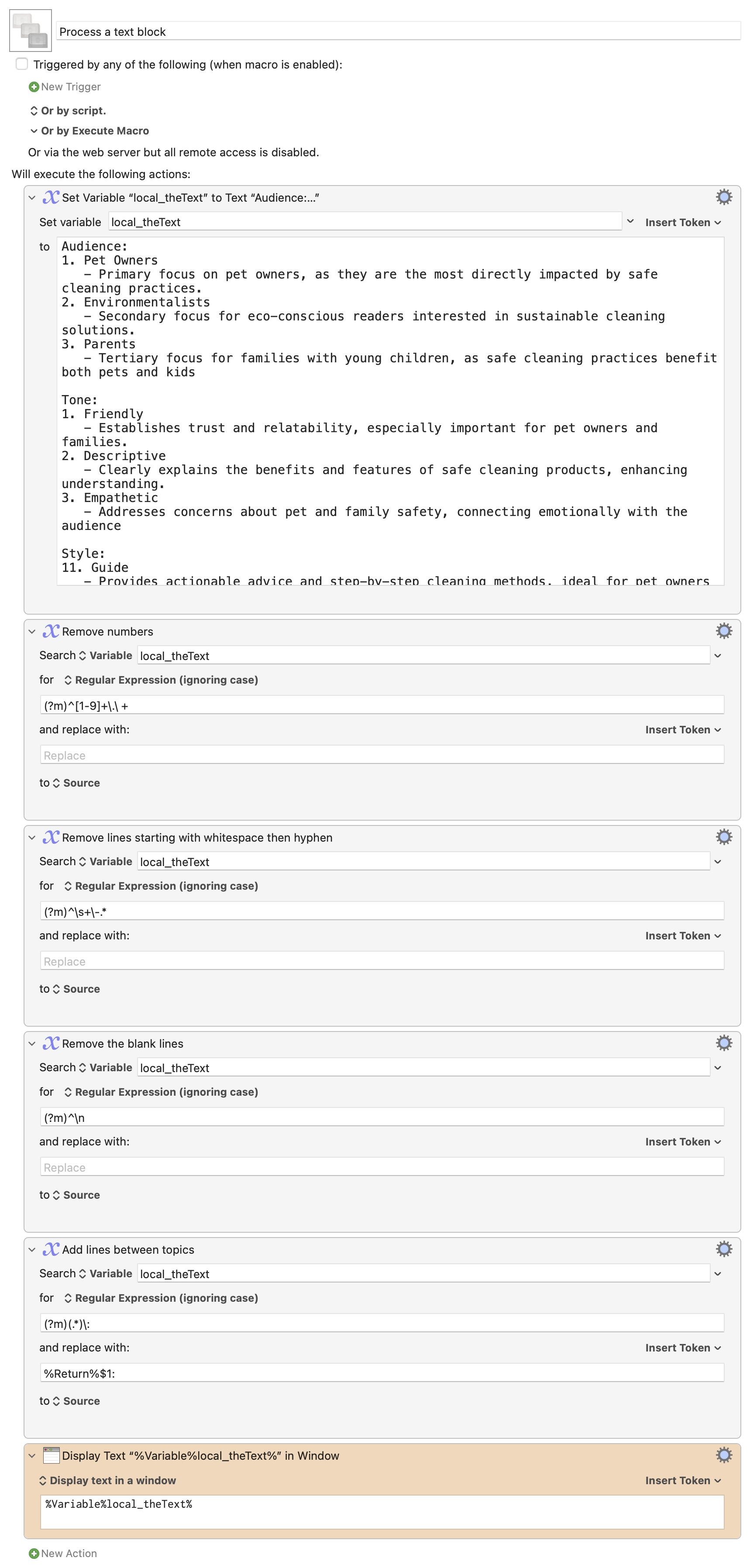
Ultimately while I'm at it, the 'numbered' lines could also start with "#1. " so I'd like to also remove the "#1. ", at the top of those lines leaving the rest of the text in those lines.
If I could at least get the "1. " and / or the "#1. " removed at the top of those lines and all the other lines removed completely that would be great.
If I can't get the space before "Tone:" or "Style:" that's fine, I can manually add 2 carriage returns.
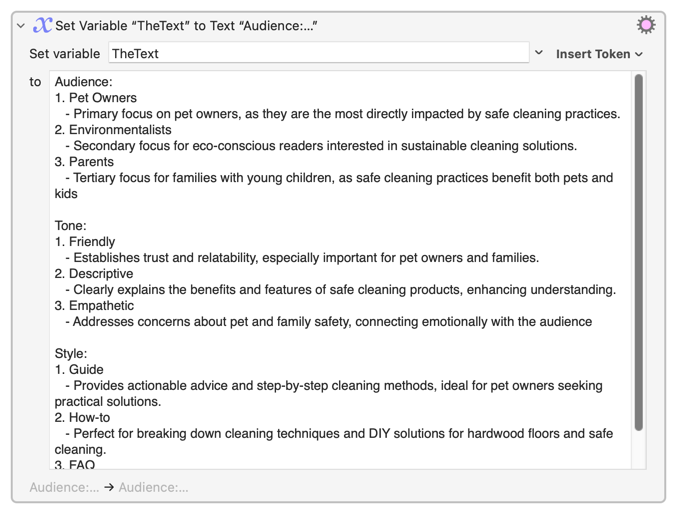
There will always be the words Audience, Tone and Style in the original block of text.
Audience:
1. Pet Owners
- Primary focus on pet owners, as they are the most directly impacted by safe cleaning practices.
2. Environmentalists
- Secondary focus for eco-conscious readers interested in sustainable cleaning solutions.
3. Parents
- Tertiary focus for families with young children, as safe cleaning practices benefit both pets and kids
Tone:
1. Friendly
- Establishes trust and relatability, especially important for pet owners and families.
2. Descriptive
- Clearly explains the benefits and features of safe cleaning products, enhancing understanding.
3. Empathetic
- Addresses concerns about pet and family safety, connecting emotionally with the audience
Style:
1. Guide
- Provides actionable advice and step-by-step cleaning methods, ideal for pet owners seeking practical solutions.
2. How-to
- Perfect for breaking down cleaning techniques and DIY solutions for hardwood floors and safe cleaning.
3. FAQ
- Addresses common questions about safe cleaning products, reinforcing the article's authority and utility.
I don't actually know why there's not a blank row at the top; I would have expected the final regex to add one, but it doesn't seem to do so. As noted, not elegant at all, and hard to scale as you add more conditions, but it does work.
(If you downloaded the macro as soon as I posted it, make sure you got the version where the first regex reads like this: (?m)^[1-9]+\.\ + ... I was missing a plus sign after the numbers, so double-digit line numbers were missed.)
I do this all the time, and I use this shell-based solution: (the "." is actually regex)
grep .
This solution has one additional side benefit - it adds a newline to the end of the last line if the last line ends with an end of file marker instead of a newline. This is extremely important to me as some shell commands will fail if the last line doesn't end with a newline.
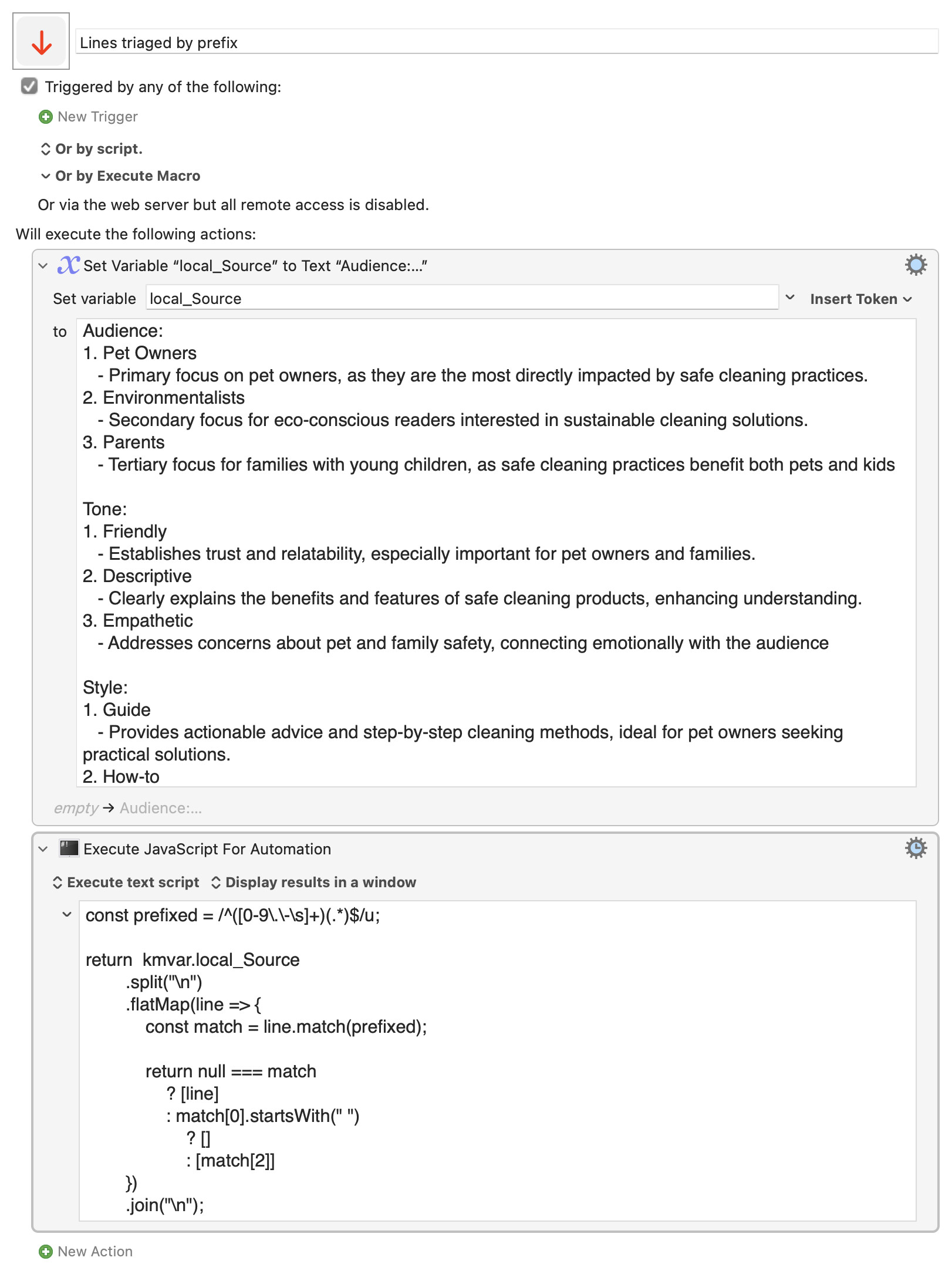
well yes, you are absolutely right....
I was off base by the fact that I was first able to remove the text from the 'bulleted'/hyphen lines, and then could not remove the blank lines.
With your correct assessment, you are correct:
bulleted lines filtered out
numbered lines de-numbered (if a "#1. " could also. be removed that's even better
blank lines left in place