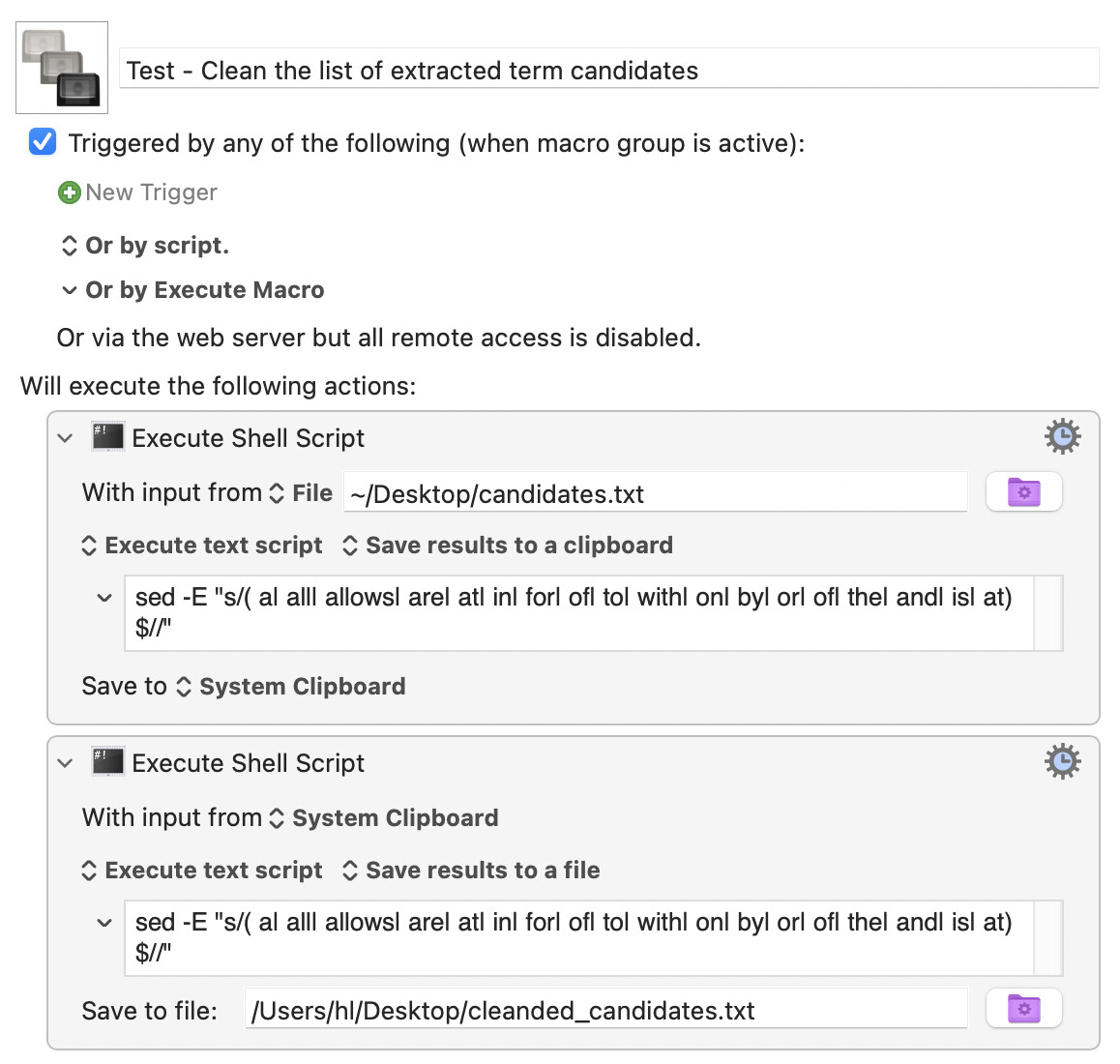
I'm not good with negative lookahead. What's wrong with this solution? I solved it myself, then I asked ChatGPT to solve it, and it came up with the same solution.
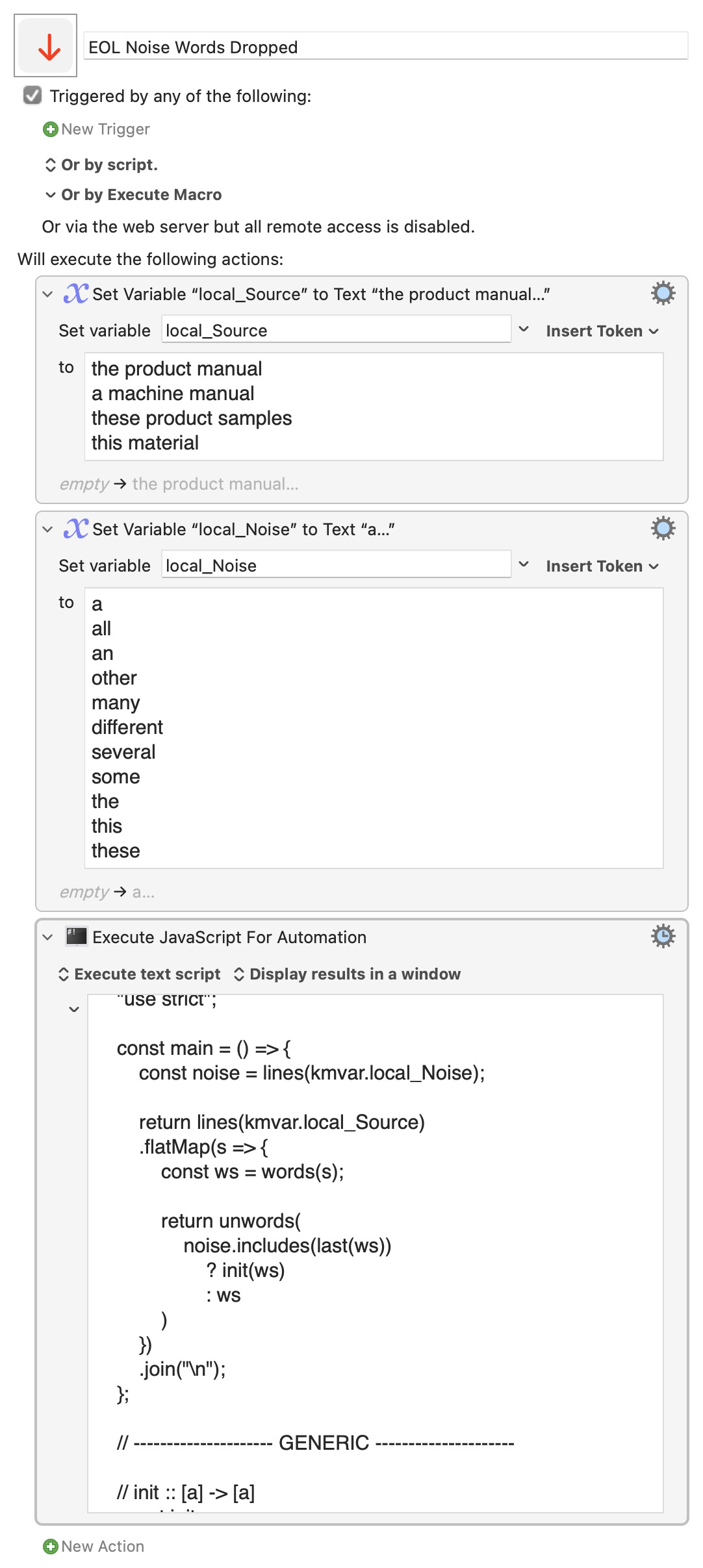
Your suggestion works fine. (I just had to add a space before every noise word, to set the word boundary.)
Do you happen to know how long this command line can be? If it is limited, it would be better if it would get its input from a file with noise words :).
return (() => {
"use strict";
const main = () => {
const noise = lines(kmvar.local_Noise);
return lines(kmvar.local_Source)
.flatMap(s => {
const ws = words(s);
return unwords(
noise.includes(last(ws))
? init(ws)
: ws
)
})
.join("\n");
};
// --------------------- GENERIC ---------------------
// init :: [a] -> [a]
const init = xs =>
// All elements of a list except the last.
0 < xs.length
? xs.slice(0, -1)
: null;
// last :: [a] -> a
const last = xs => {
// The last item of a list.
const n = xs.length;
return 0 < n
? xs[n - 1]
: null;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// unwords :: [String] -> String
const unwords = xs =>
// A space-separated string derived
// from a list of words.
xs.join(" ");
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
// Leading and trailling space ignored.
s.split(/\s+/u).filter(Boolean);
// MAIN ---
return main();
})();
I think the limit is very large, (200k?) so you don't need to worry about it.
Even if you put it in a file, the lines of the file would be subject to the same limitation, so I don't see what you would be gaining. You can't break up the command I gave you into separate commands. Well, you could put them in a loop, but that would be MUCH slower, and I don't think you are anywhere near the 200k command line limit.