Could you give us a couple of examples of (Source language, Target language) pairs ?
Ideally with one example where everything matches, and at least one where there is some mismatch ?
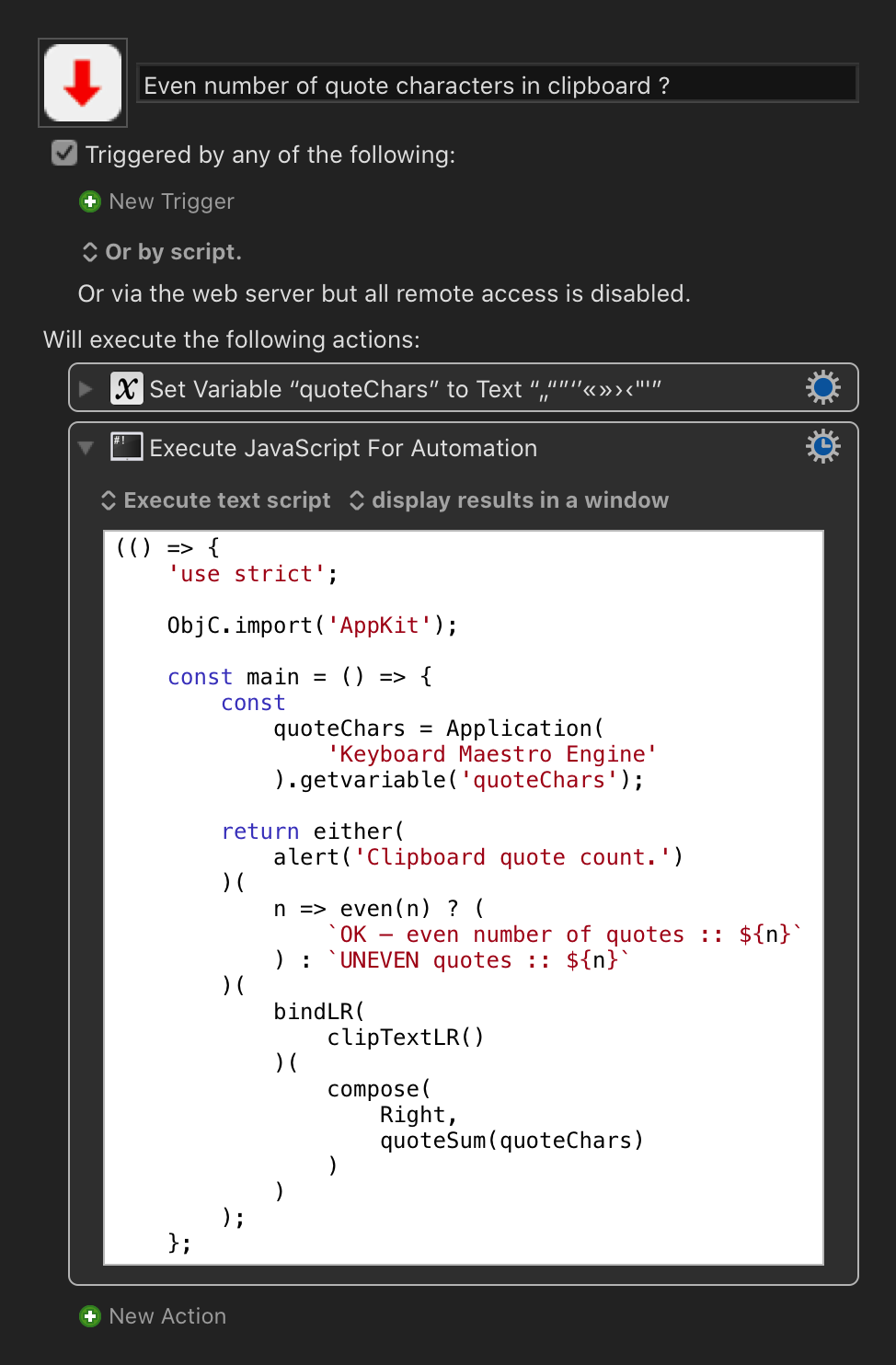
As @JakubMarian's useful map illustrates, to check the closing of a lower double quote, we might need to know which language we are looking at (NL vs DE for example), and how the quotes have been mapped across a particular language pair, so I guess that you are looking for a count as the first check ?
(() => {
'use strict';
ObjC.import('AppKit');
const main = () => {
const
quoteChars = Application(
'Keyboard Maestro Engine'
).getvariable('quoteChars');
return either(
alert('Clipboard quote count.')
)(
n => even(n) ? (
`OK – even number of quotes :: ${n}`
) : `UNEVEN quotes :: ${n}`
)(
bindLR(
clipTextLR()
)(
compose(
Right,
quoteSum(quoteChars)
)
)
);
};
// quoteSum :: String -> String -> Int
const quoteSum = quoteChars =>
s => [...s].reduce(
(a, c) => quoteChars.includes(c) ? (
1 + a
) : a,
0
);
// ----------------------- JXA -----------------------
// alert :: String => String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application('System Events'), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ['OK'],
defaultButton: 'OK'
}),
s
);
};
// clipTextLR :: () -> Either String String
const clipTextLR = () => (
v => Boolean(v) && 0 < v.length ? (
Right(v)
) : Left('No utf8-plain-text found in clipboard.')
)(
ObjC.unwrap($.NSPasteboard.generalPasteboard
.stringForType($.NSPasteboardTypeString))
);
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: 'Either',
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: 'Either',
Right: x
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => undefined !== m.Left ? (
m
) : mf(m.Right);
// compose (<<<) :: (b -> c) -> (a -> b) -> a -> c
const compose = (...fs) =>
// A function defined by the right-to-left
// composition of all the functions in fs.
fs.reduce(
(f, g) => x => f(g(x)),
x => x
);
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => 'Either' === e.type ? (
undefined !== e.Left ? (
fl(e.Left)
) : fr(e.Right)
) : undefined;
// even :: Int -> Bool
const even = n =>
// True if 2 is a factor of n.
0 === n % 2;
// MAIN ---
return main();
})();
Something more fine-grained (highlighting which quote pair was defective) might be possible (for quotation types where the open character differs from the closing character), but it would require specifying the particular pair of languages.
(so that we know which the opening and closing pairs are)
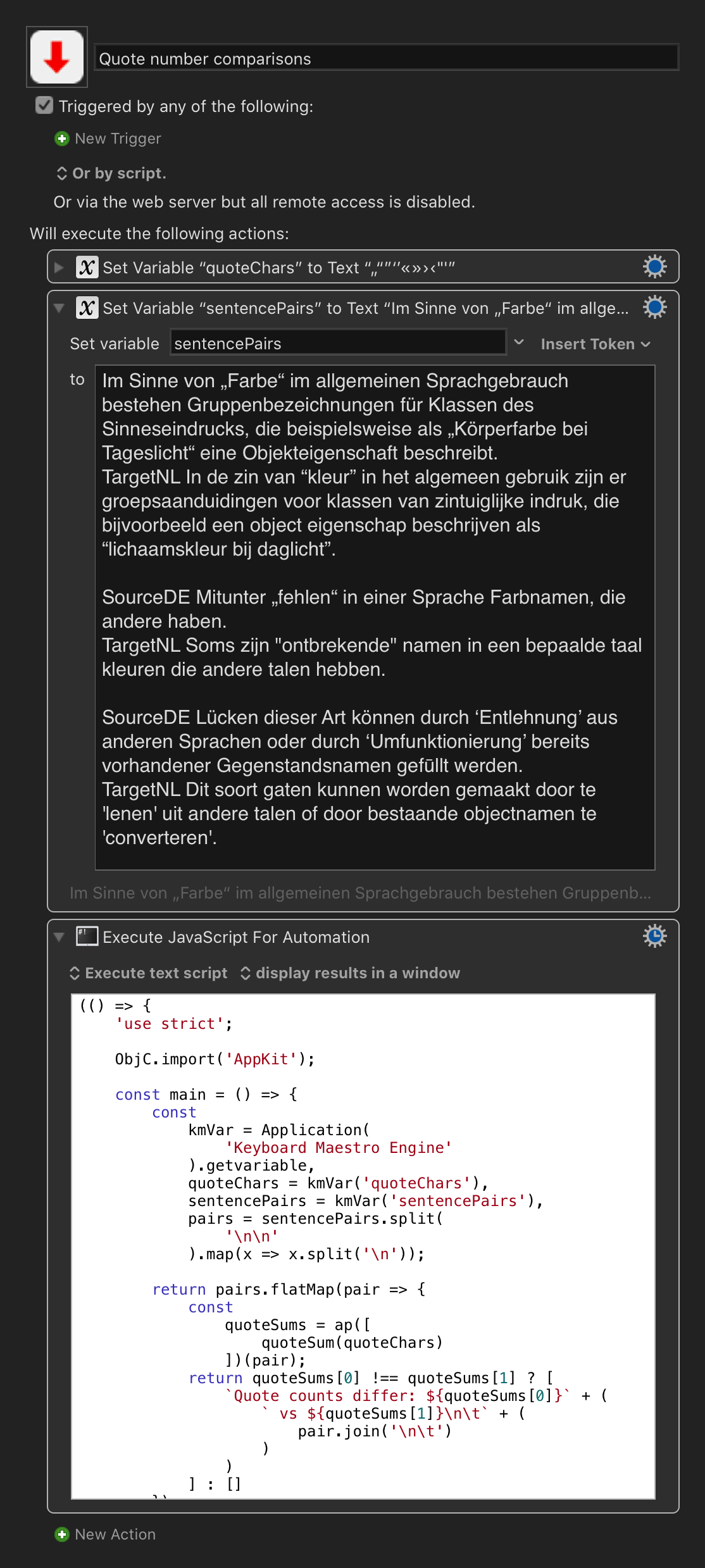
Im Sinne von „Farbe“ im allgemeinen Sprachgebrauch bestehen Gruppenbezeichnungen für Klassen des Sinneseindrucks, die beispielsweise als „Körperfarbe bei Tageslicht“ eine Objekteigenschaft beschreibt.
TargetNL In de zin van “kleur” in het algemeen gebruik zijn er groepsaanduidingen voor klassen van zintuiglijke indruk, die bijvoorbeeld een object eigenschap beschrijven als “lichaamskleur bij daglicht”.
SourceDE Mitunter „fehlen“ in einer Sprache Farbnamen, die andere haben.
TargetNL Soms zijn "ontbrekende" namen in een bepaalde taal kleuren die andere talen hebben.
SourceDE Lücken dieser Art können durch ‘Entlehnung’ aus anderen Sprachen oder durch ‘Umfunktionierung’ bereits vorhandener Gegenstandsnamen gefūllt werden.
TargetNL Dit soort gaten kunnen worden gemaakt door te 'lenen' uit andere talen of door bestaande objectnamen te 'converteren'.
SourceDE Die emotionale Wirkung von Farbnamen nutzt die Werbung für kommerzielle Produkte, da hier Verknüpfungen zu „ansprechenden“, allgemein bekannten Gegenständen oder Situationen nutzbar sind.
TargetNL Het emotionele effect van kleurnamen wordt gebruikt in reclame voor commerciële producten, omdat links naar ‘aansprekende’, algemeen bekende objecten of situaties kunnen worden gebruikt.
SourceDE Beispiele dafür sind das späte Auftreten von «Orange», «Rosa», «Türkis» oder «Magenta» im Deutschen.
TargetNL Voorbeelden hiervan zijn de late verschijning van "oranje", "roze, "turkoois" of "magenta" in het Duits.
The last TargetNL is missing one " at roze.
It's smarter to compare the number of quotes for each SourceDE with the number of quotes in the corresponding TargetNL than to check whether the number of quotes is even.
No need to make the macro more difficult: the quotes in the sourceDEs don't to be matched by specific types of quotes in the corresponding TargetNLs (« can be matched by ’ etc.). It's just the numbers of quotes that need to correspond.
The more you think about this problem, the more difficult it becomes. Assuming that a complete solution is possible—of which I’m not convinced—it may be far more complicated that it’s worth.
The checksum solution is probably the simplest. Even though it tests for consistency rather than correctness (both the source and translation can be wrong), it probably is correct in the great majority of cases. And @tiffle’s suggestion to use a negated character class is very good—much easier to understand and maintain. You should probably add the single straight quotation mark to it.
(By the way, it’s apostrophes that make me doubtful that a complete solution is possible. Apostrophes don’t come in pairs, and their rules are based more on sentence context and grammatical structure than on character position. This is why smart quotes algorithms sometimes fail.)


{kind=link}