demo1.txt.zip (738 Bytes)
I have received a database with terminology that I should use for my next job.
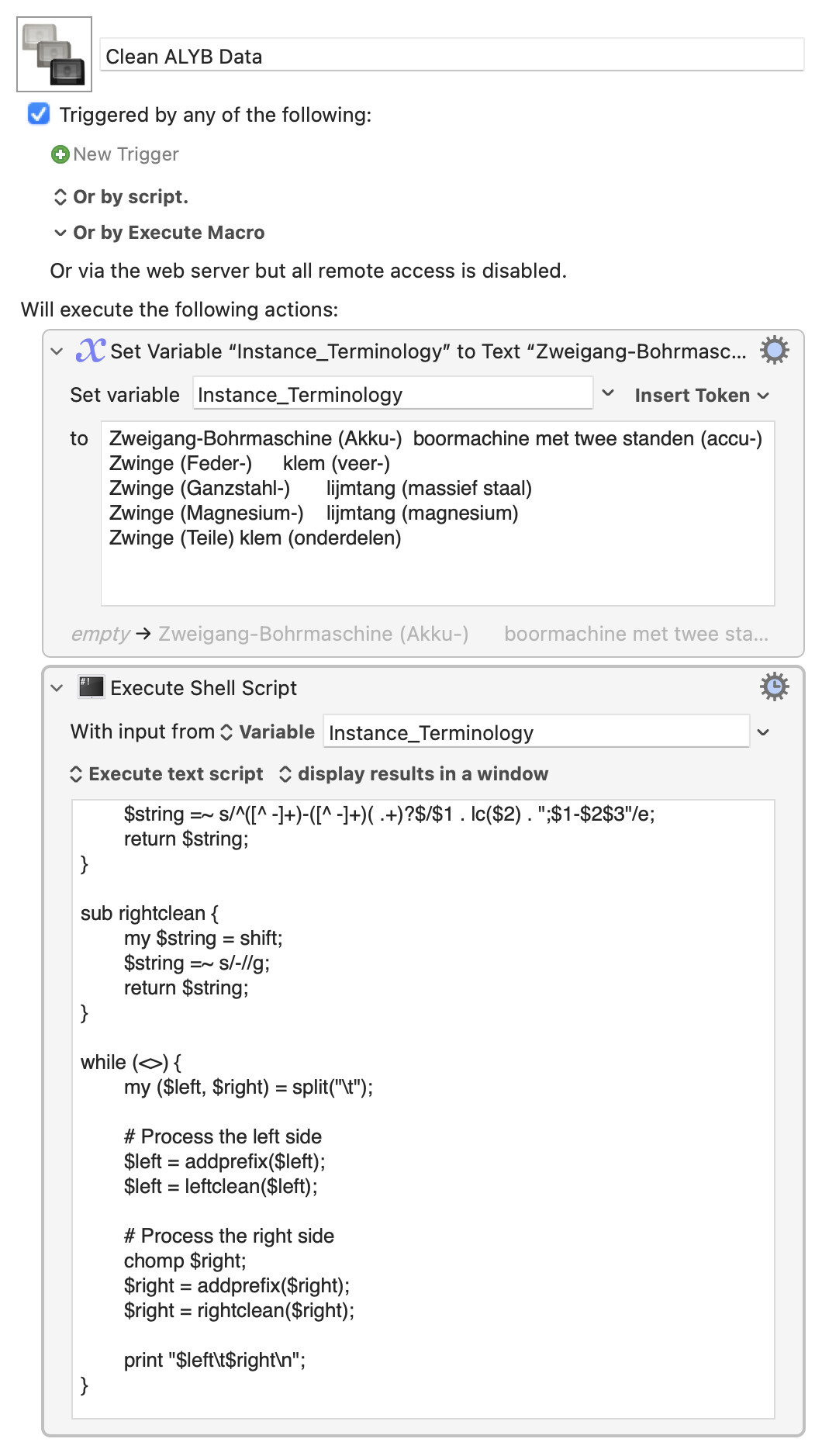
The export looks lik this:
#source\t#target
Zweigang-Bohrmaschine (Akku-)\tboormachine met twee standen (accu-)
Zwinge (Feder-)\tklem (veer-)
Zwinge (Ganzstahl-)\tlijmtang (massief staal)
Zwinge (Magnesium-)\tlijmtang (magnesium)
Zwinge (Teile)\tklem (onderdelen)
(I've used '\t' to indicate the tab character.)
I'd like to get this output:
Akku-Zweigang-Bohrmaschine\taccu-boormachine met twee standen
Feder-Zwinge\tveer-klem
Ganzstahl-Zwinge\tlijmtang (massief staal)
Magnesium-Zwinge\tlijmtang (magnesium)
Zwinge (Teile)\tklem (onderdelen)
Rules:
- If either side of the tab character (being source term and target term) contain a word between brackets that ends with a dash, this part between brackets should be moved to the position before the previous word: Zwinge (Feder-) > Feder-Zwinge.
An optional step would be further cleaning and enhancement:
Akku-Zweigang-Bohrmaschine\taccu-boormachine met twee standen
Federzwinge;Feder-Zwinge\tveerklem
Ganzstahlzwinge;Ganzstahl-Zwinge\tlijmtang (massief staal)
Magnesiumzwinge;Magnesium-Zwinge\tlijmtang (magnesium)
Zwinge (Teile)\tklem (onderdelen)
Rules:
- If the left-hand side of the glossary (the source) contains exactly one dash, a variant of the word (group) should be placed before the word (group), while the dash has been removed and the uppercase letter following the word has been converted to lowercase: Magnesium-Zwinge > Magnesiumzwinge;Magnesium-Zwinge.
- If the right-hand side of the glossary (the target) contains one or more dashes, this dash (these dashes) should be removed: veer-klem > veerklem.
How should I tackle this?