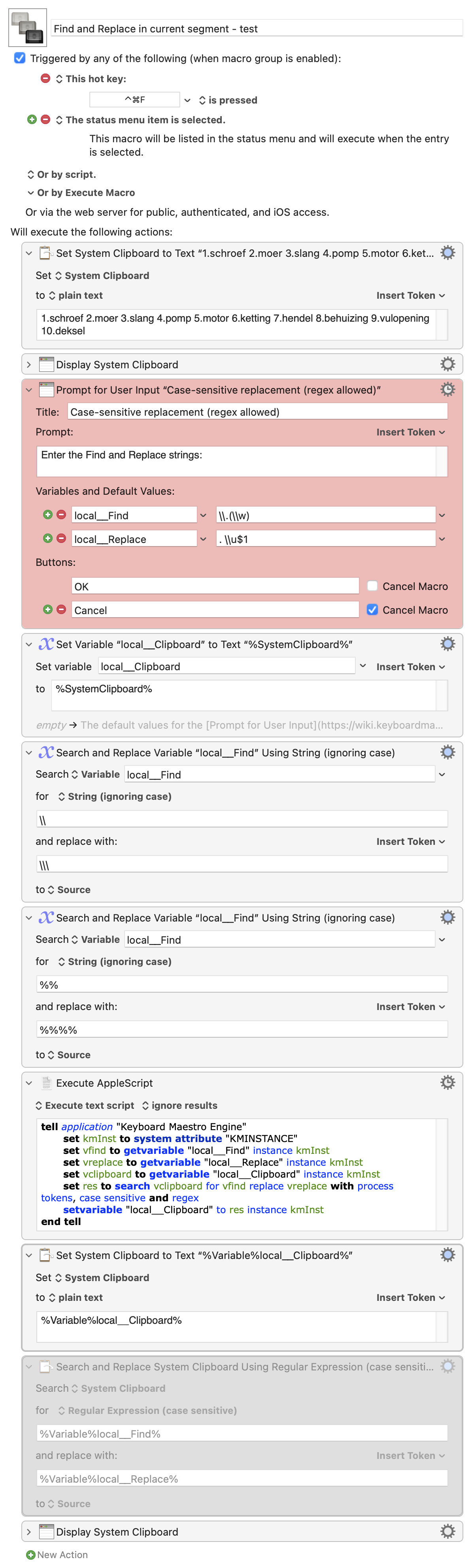
The problem isn't the regex, it's in how your expressions are getting parsed from the text variable into the action's regex fields. So hard-coding works as expected:
I think this method is somewhat simpler than most any other approach.
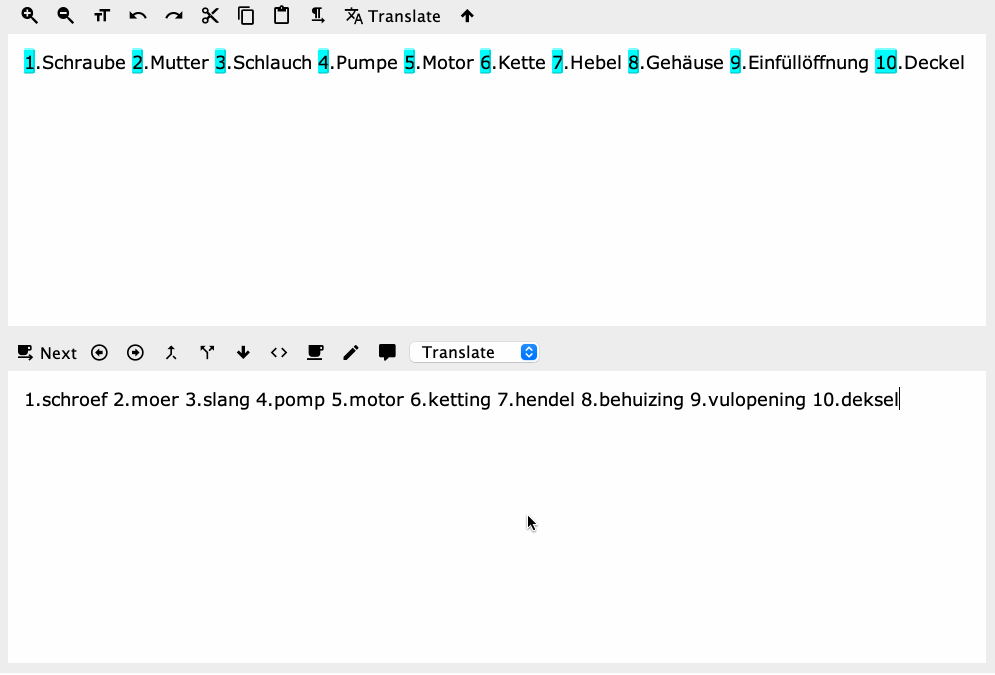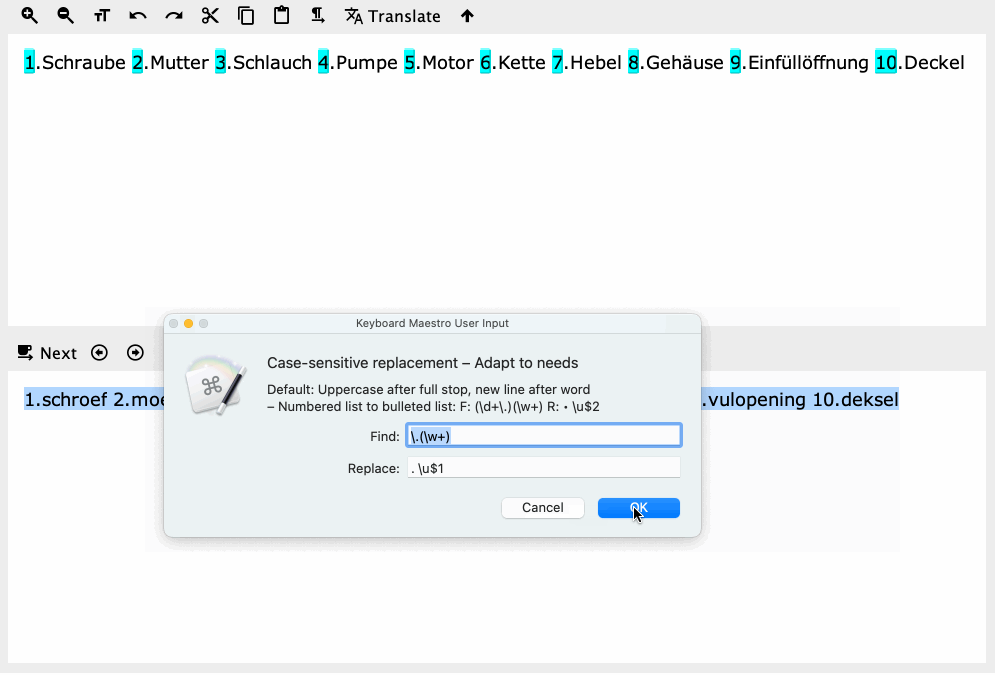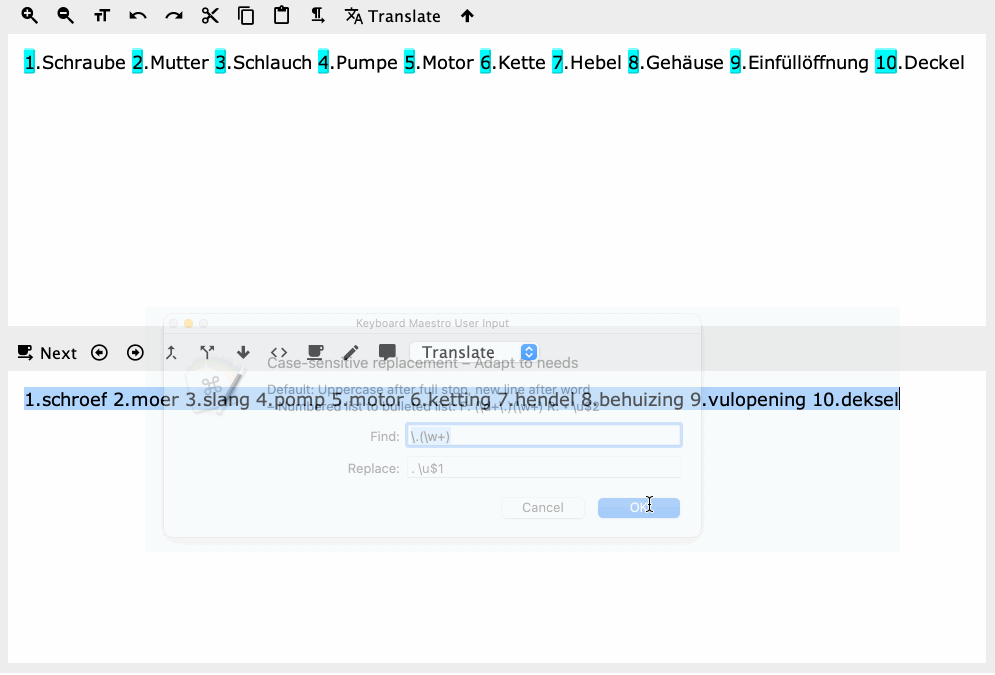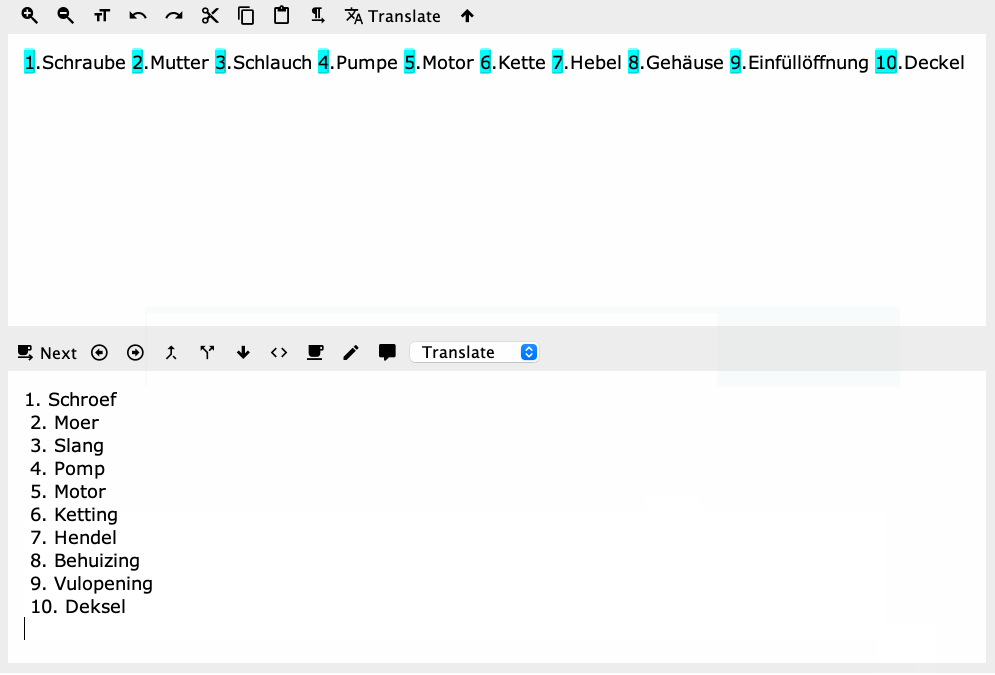
@peternlewis - is this a bug in the Prompt for User Input action?
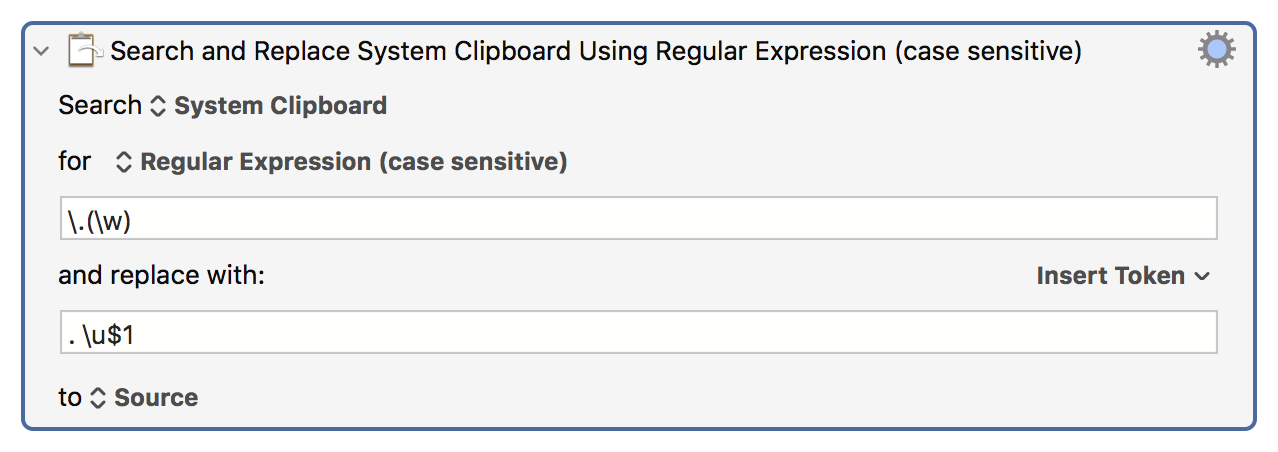
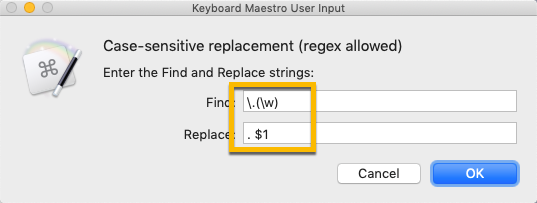
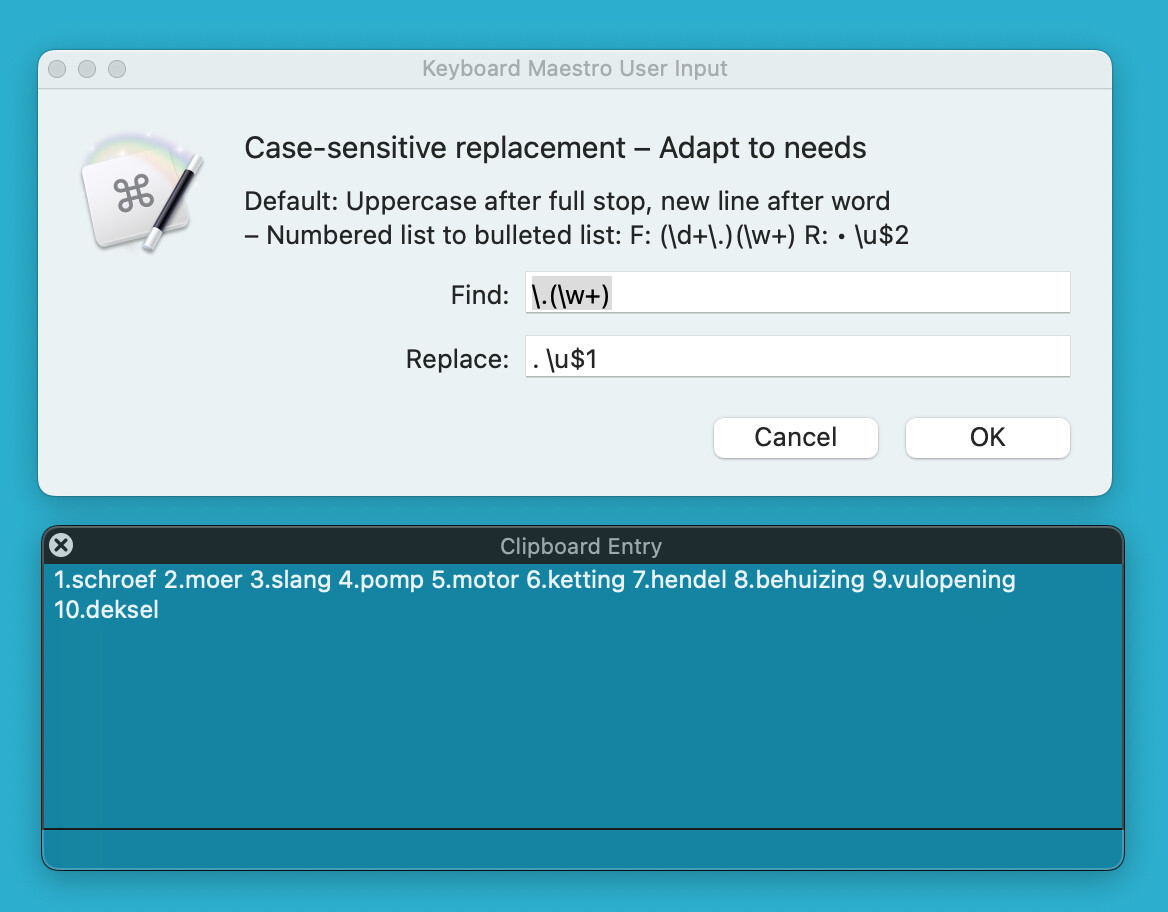
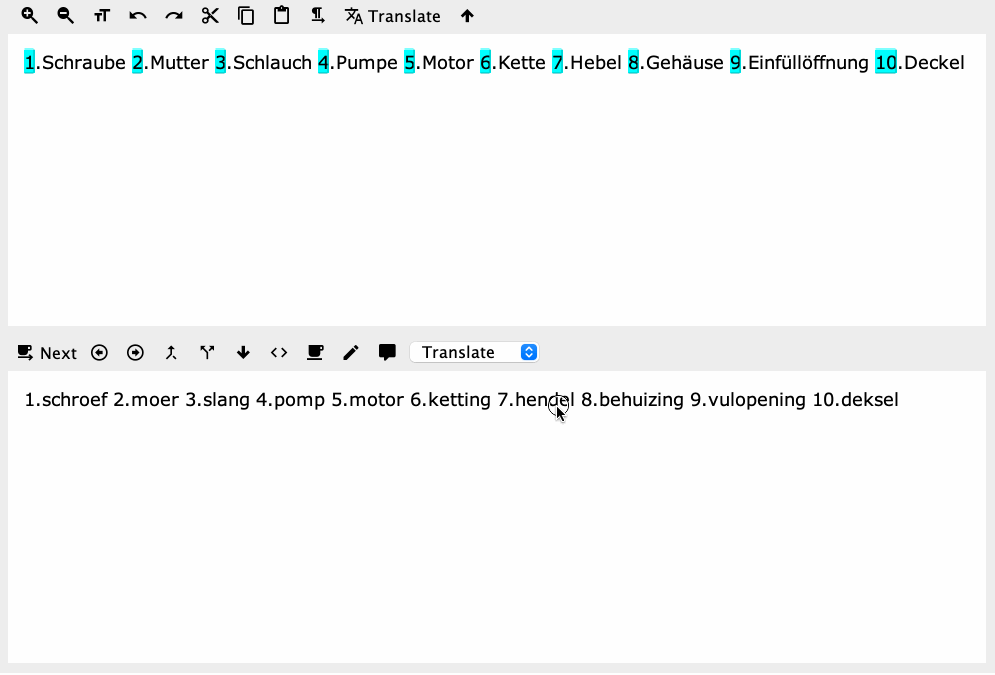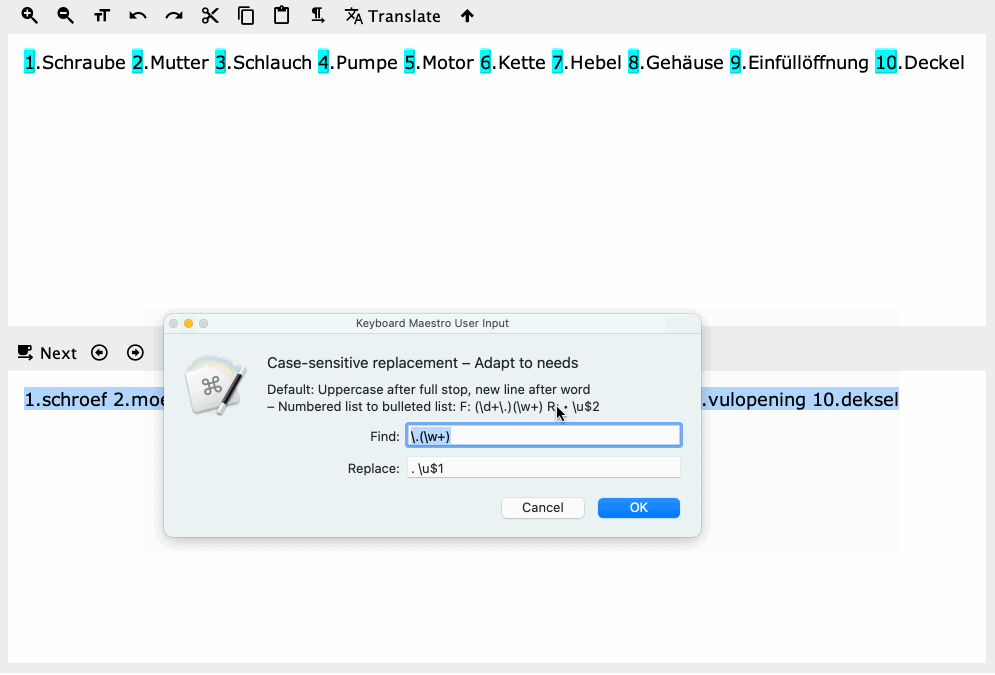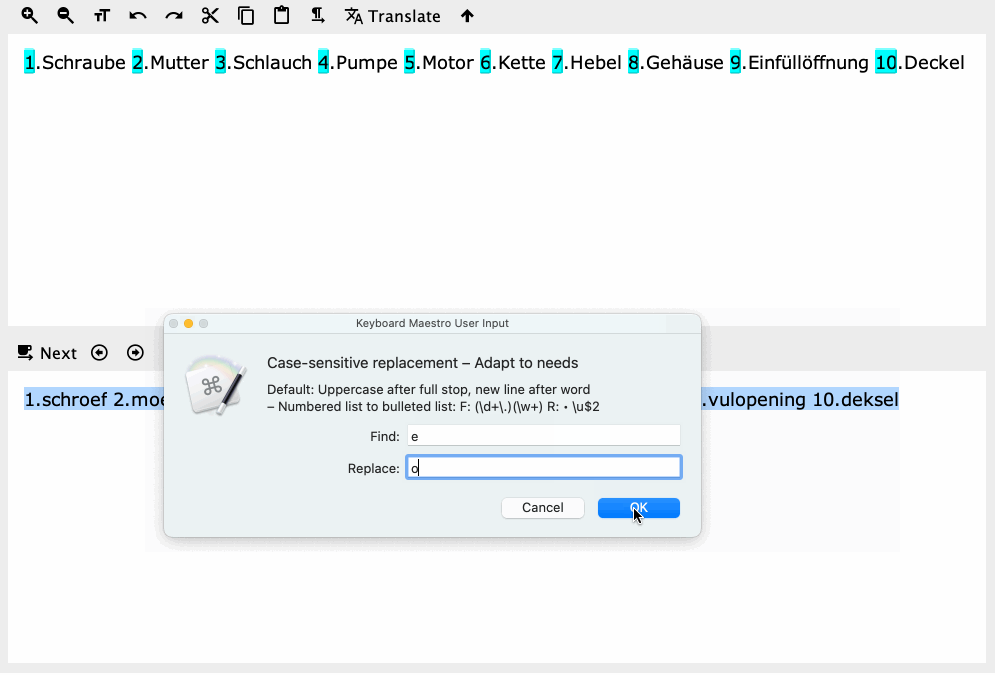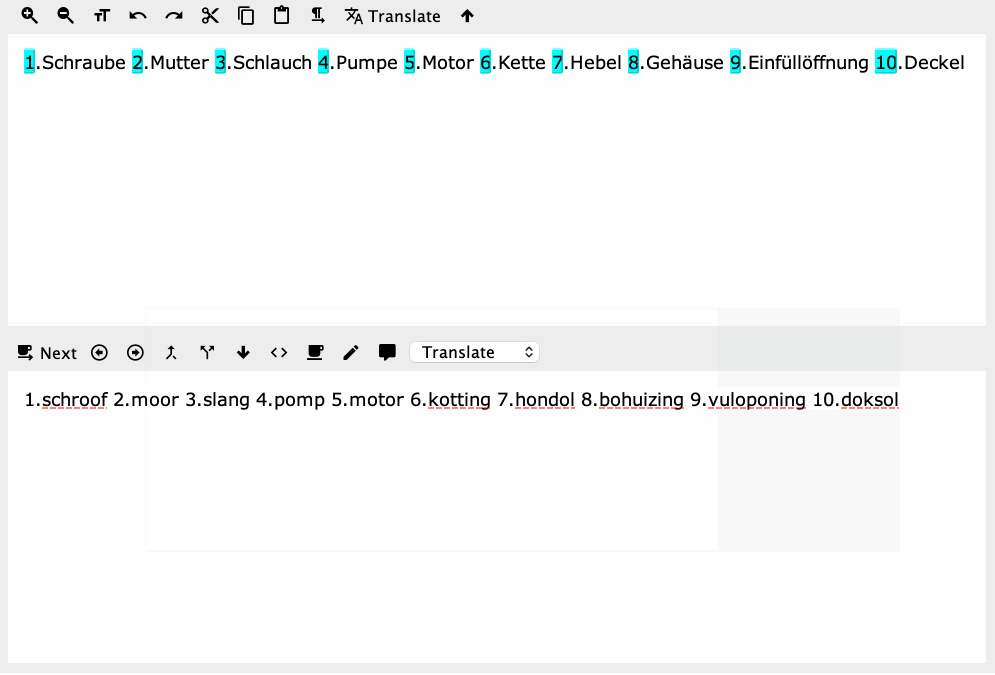
Typing ". \u$1" into a text field results in ". $1" being passed into the variable.
EDIT: Or is it because (as I've just read in the KM manual) that the text field by default is a "token text field" and so, since "\u" is a text token KM interprets it before passing it to the variable? If that's the reason, can a gear menu option be added to Process text Normally/Tokens Only/Nothing as in the Set Variable to Text action?
Or is it the \ characters, also special in KM text fields -- which IMO is why the search is failing, so $1 isn't populated...
There are just too many possible problems trying use special characters in a prompt to fill a variable to use in a regex. I think @ComplexPoint point's approach is better -- if you want a user-defined regex search and replace, hand it off.
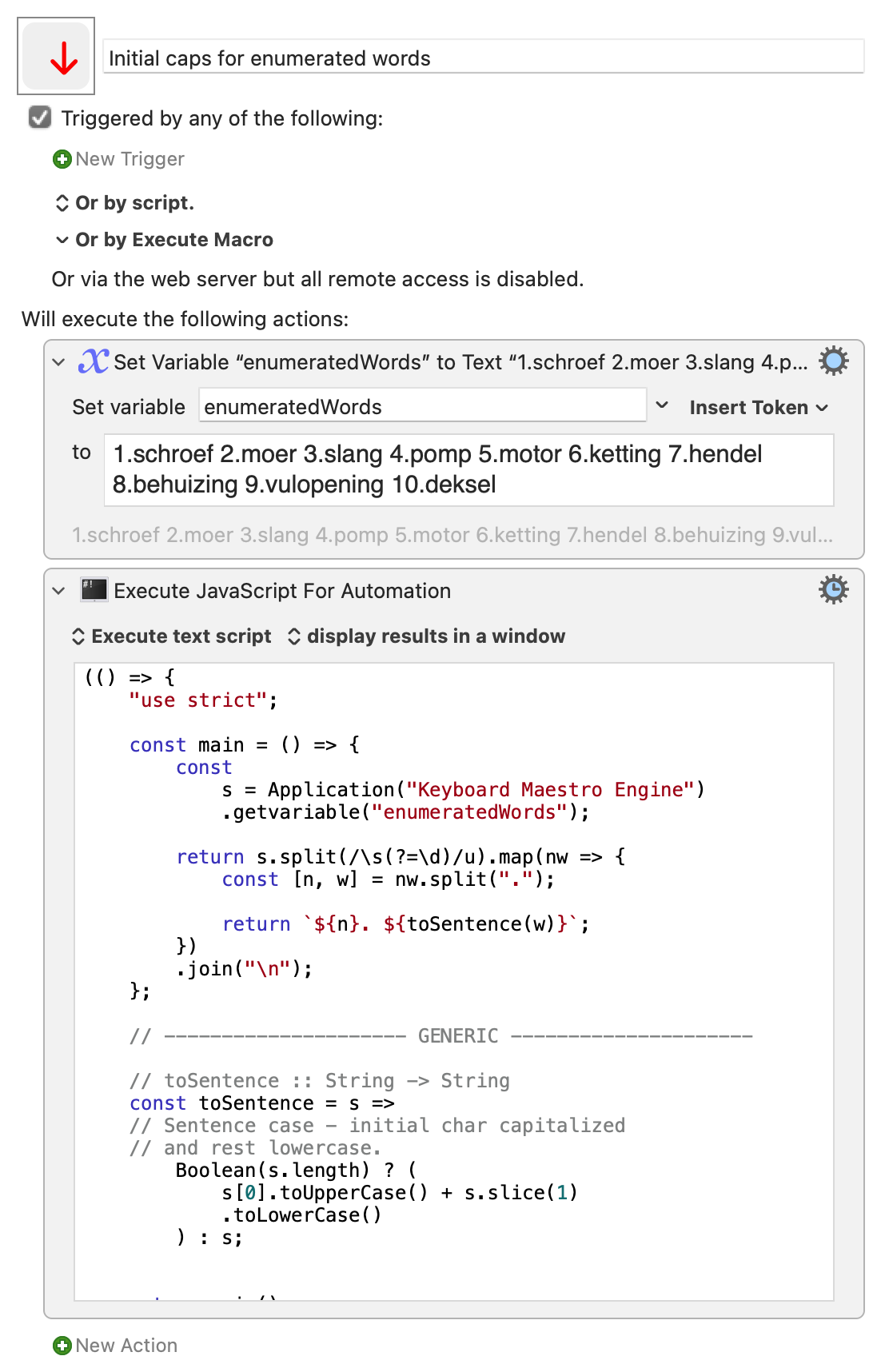
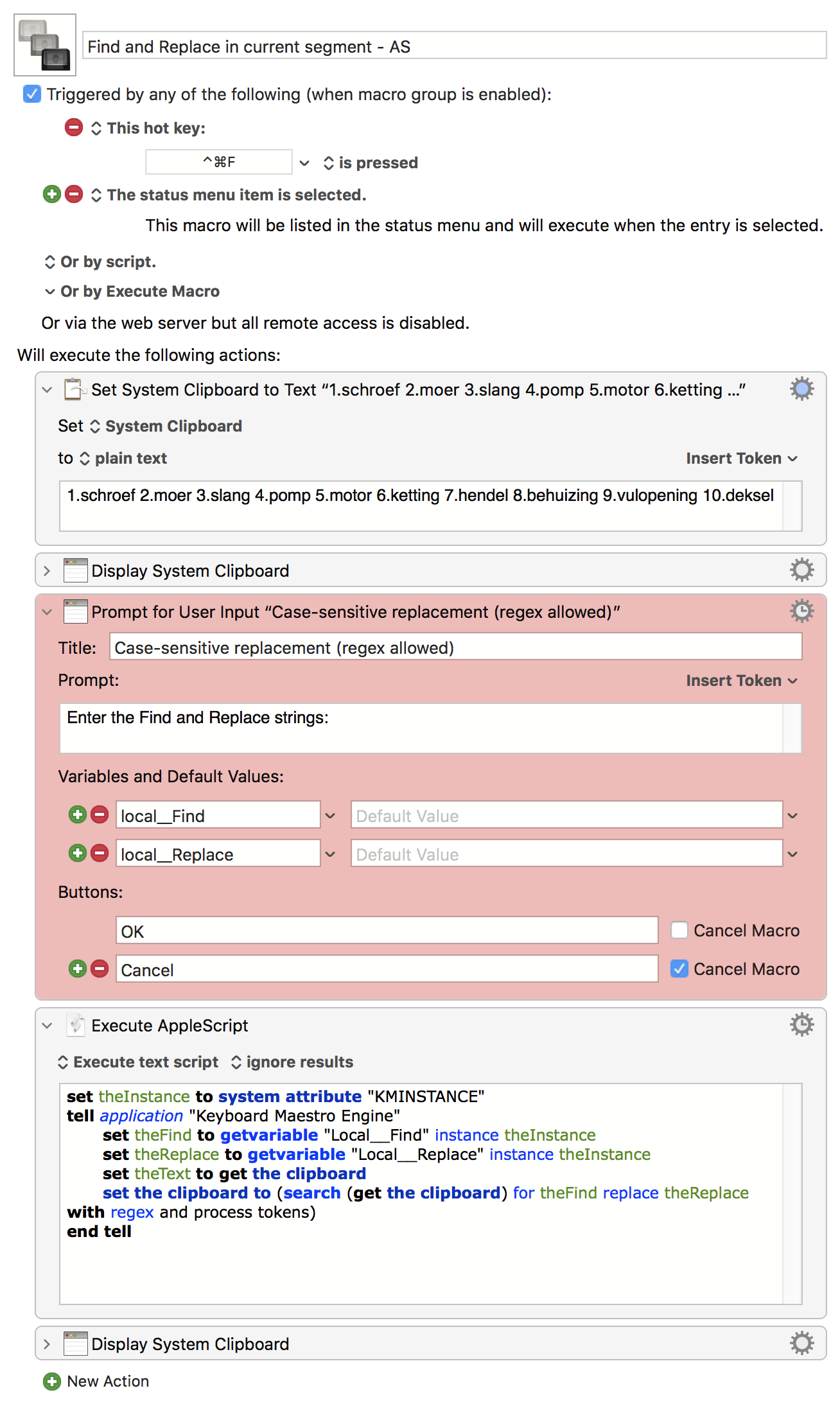
Since using AppleScript means we can leverage KME's regex engine, with all the goodies we know and love (and nothing to do with me knowing zero JavaScript!) -- here's my go at it:
KM is processing the text in the field as token text - as stated in the manual - but it's doing this prior to the display of the dialog. After the dialog is OK'd, for some reason what is then passed to the Search & Replace action,
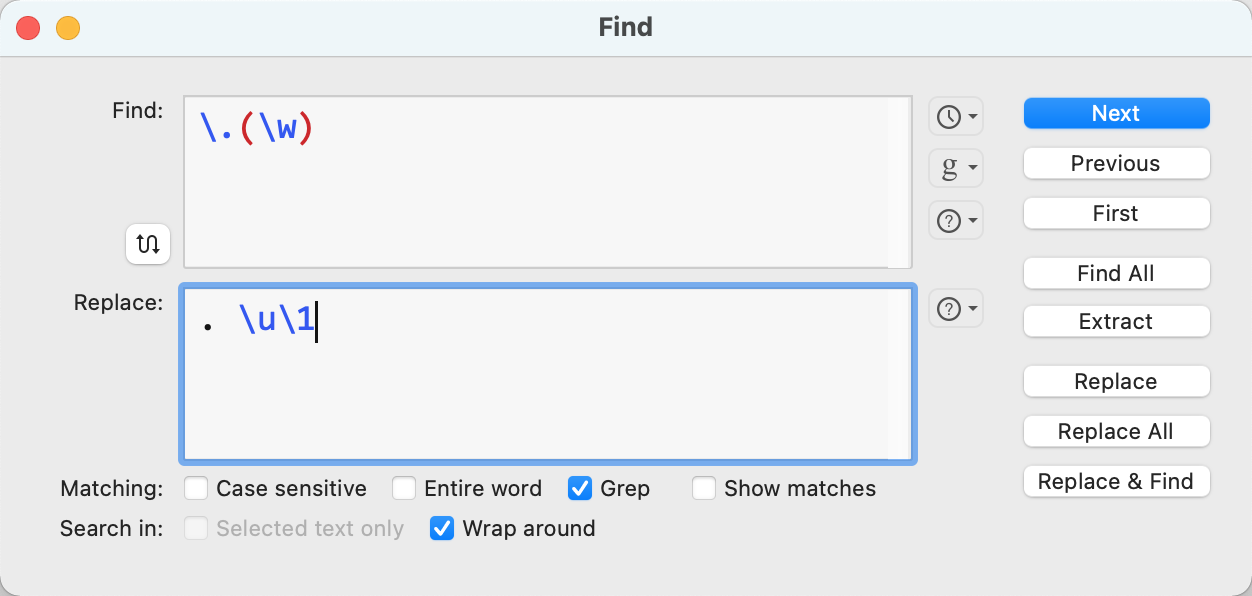
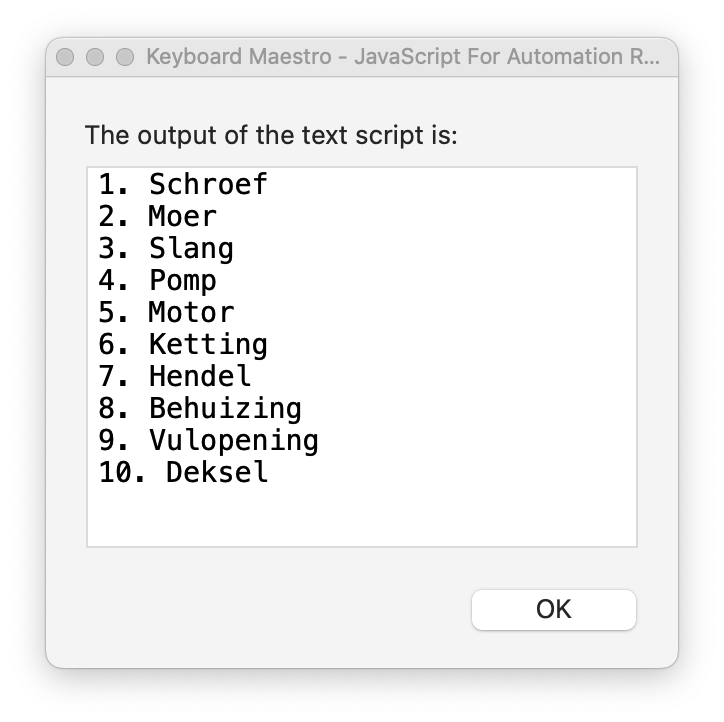
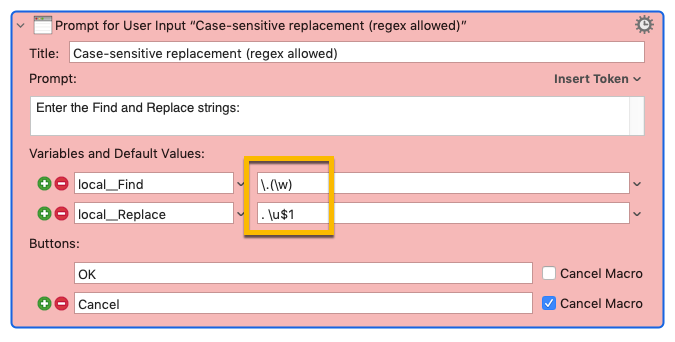
= local__Find =
\.(\w)
= local__Replace =
. \u$1
although correct from a regex viewpoint, is not recognised properly and so the search/replace doesn't work. So I still think I'd like @peternlewis's perspective on what's actually going on!
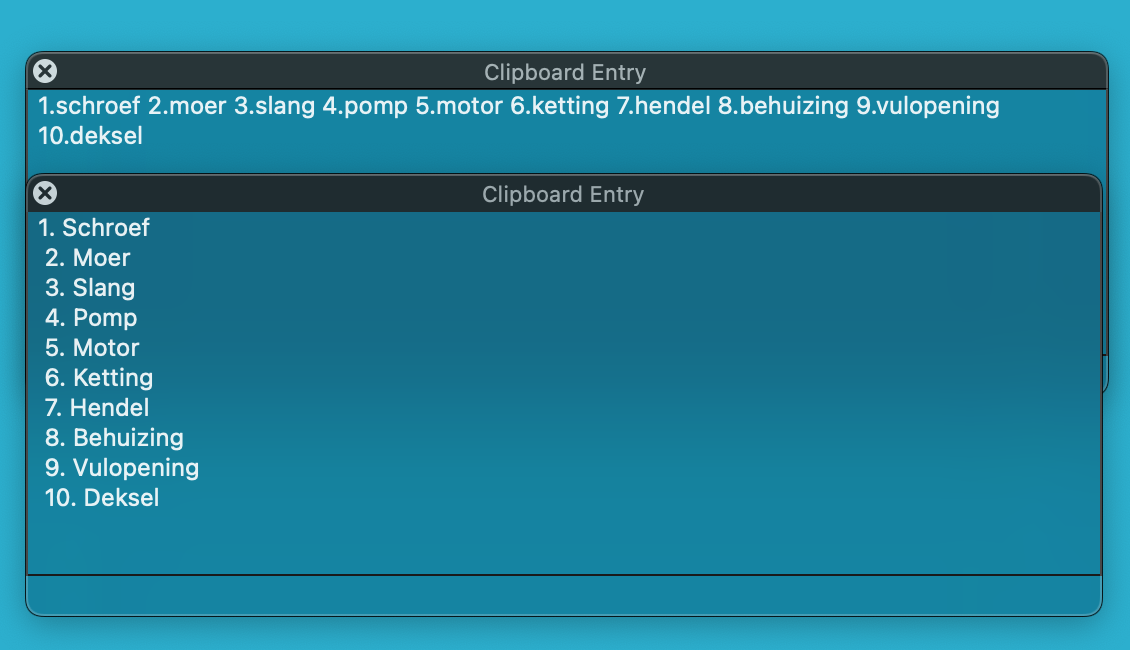
Yes, but you'll also notice the search didn't work properly -- the whole word after the full stop should be the first capture group, but it's actually find/replacing the period and the next character only.
I talk a load of rubbish sometimes. \w is a word character, not word. Right track, wrong reason...
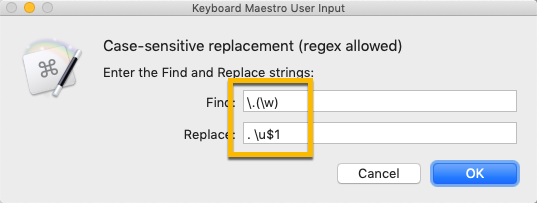
What I haven't got my head round is when/if backslashes are backslashes in the various fields involved, and my feeling is that this is at the heart of the problem. My knee-jerk was that "if we want to pass a literal \u to the Replace we should use \\u in a text field", but that didn't seem to work.
It's almost like text tokens aren't processed in the Search/Replace fields -- because hard-coding works literally -- unless they are inside a variable token...
At which point my brain exploded and I turned to the AppleScript workaround! What's weird is that's doing almost the same thing -- taking variables from KME then feeding them back to the KME regex engine -- but with an explicit process tokens argument.
The default values for the Prompt for User Input action are parsing the tokens. So the \u gets processed, because \u means something to Keyboard Maestro. The \. and \w do not mean anything so they are left alone. In all cases they would be better written with the \ doubled.
The search and replace fields are also processed for text tokens, so the variables are expanded in both fields.
However, the search engine then processes the first field, so things like . and \w mean something to the search engine.
The replacement field is also processed, and the variable is expanded, but after that the processing is complete. No further processing happens, so the . \u$1 does not mean anything. Just as if the variable contains the text %Variable%Whatever% or any other token, it would not be recursively expanded.
There isn't an easy way to get Keyboard Maestro to process the tokens twice in the Search and Replace action replacement string. One option is to use AppleScript to ask Keyboard Maestro to do the search and replace. However since the process tokens option applies to both the search and the replace field, and you don't really want the search field to be processed, it does mean you have to quote the search field (there should be a Filter for that, but there isn't, but it simply means doubling the % and \ characters so it is pretty straight forward (though again, not that you have to double the each of the characters in the Search & Replace so they are correctly processed.
Quoting it hard and understanding how and when the quoting and processing happens is important to really understanding what is happening.
And where the search and replace model tends to overload and inflate the complexity of regexes (and the escaping decisions which they entail),
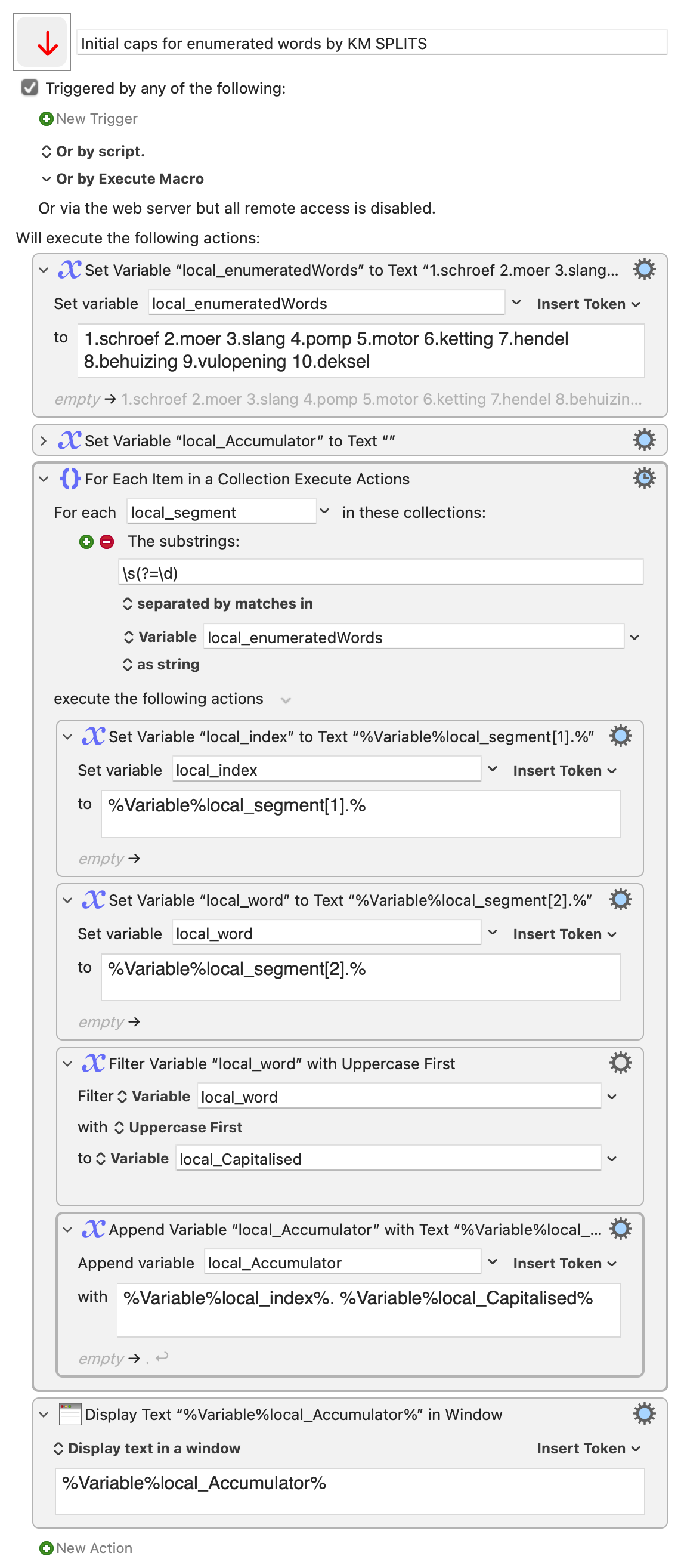
the split model eases the load on regular expressions, and lets them shrink and simplify.
Keyboard Maestro gives us:
single-character splits with indexed arrays and custom delimiters,
multi-character splits with For Each (substrings separated by matches),
and fully flexible splits through a scripting language.
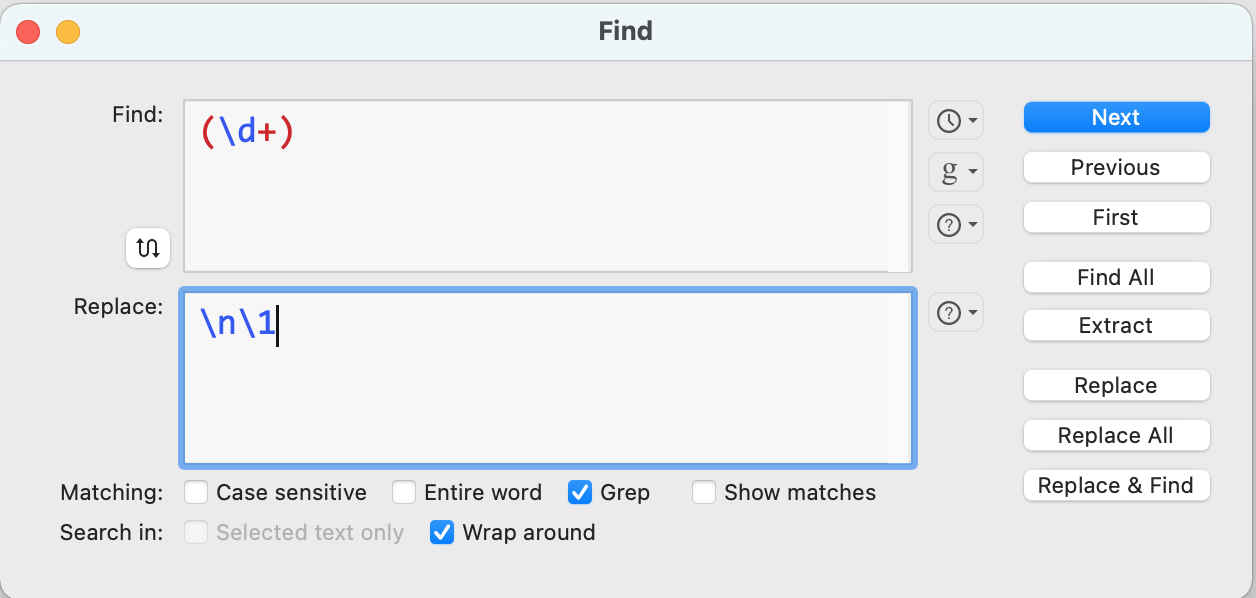
Do you mean "use an abbreviation in the dialog that is then expanded to a regex pattern"? Easiest way would be "Switch/Case" actions to determine what to -- if using the AS macro, what to set the Local__Find and Local__Replace variables to before executing the AppleScript. So if "n" was your abbreviation for "one or more numbers" and "w" was "one or more word characters":
Switch
Case -- Local__Find is "n"
Set variable Local__Find to "(\d)+"
Case -- Local__Find is "w"
Set variable Local__Find to "(\w)+"
Otherwise
Comment -- do nothing using the entered string as your Find pattern
End Switch