I have no doubt you'll be able to help me. I want to be able to extract a specific phone number (it's a Teams conference call string) from a screenshot.
I managed to get the OCR to a variable, but don't know how to find the right set of characters inside this variable and extract that set of characters alone to clipboard.
The actual string of characters is always like this example: +353 1 264 1234,,123456789#
(although I don't know if the OCR is always going to be able to pick the spaces exactly like that - so far, it's been reliably reading it 100% correctly including the spaces)
The string is the entire OCRed screenshot that has a lot of stuff. I only want that string (from the + to the # both inclusive) - that string is only meant to appear once on the page and it's in that form.
You'll probably get away with a regex of "a + followed by 25 numbers, spaces, or commas, then a #". The OCR may not pick up the spaces, or the AI might kick in and decide "all commas have spaces after" and pop in an extra couple, so you could make the range 22-27. So: \+[\d ,]{22,27}#.
You could get fancier, but that's probably complex enough given that you're unlikely to have anything similar on screen!
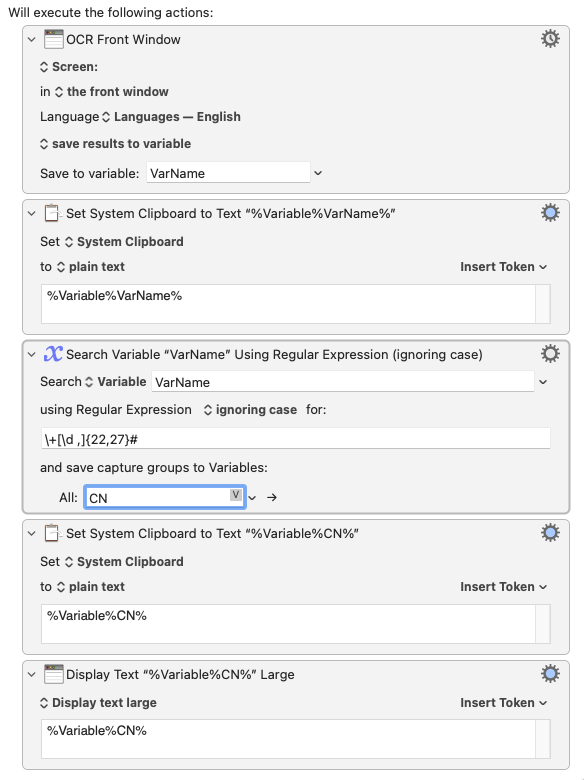
Somehow, I'm still failing at this and it makes no sense. This is what I have:
What happens:
The clipboard is loaded with the raw OCR data (which I can check, and it adequately should be loaded with the right string and your regex should pick it up - it does when I do it on an online regex website).
The clipboard doesn't get to be loaded with the regex sub-string, and nothing gets displayed.
I must be missing something quite basic, since it looks like the macro just stops midway...
That might just mean there's no regex match. Disable the last 3 actions so you are just OCRing the screen then putting the result on the clipboard. Paste into a text editor and set the font to something that clearly distinguishes between zero and capital O, and lowercase l/uppercase I/1, then manually check if the pattern still matches.
OCR has come on leaps and bounds over the years, mainly because more CPU cycles means more contextual analysis and so better word recognition -- but non-contextual strings like yours can still be a problem.