I'd like to rename my Documents by using Keyboard Maestro. I already got a big part of it but not all.
I would like to automatically read out a sequence of numbers that always remains the same. This character string XXXXXX/XX/X should also be considered in the first place in the document name. Can you help me to find the right command to read the character string?
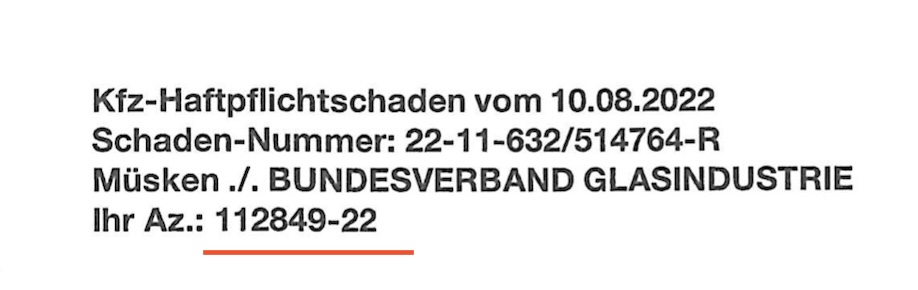
I want to read the code 112361/22/1 out of the document and want to name the PDF with that string - in different documents there are different numbers but the string is always like XXXXXX/XX/X.
Yes I“be already downloaded different scripts to install tesseract ORCmypdf and Poppler PDF to text. By using these programs I’ve managed to get the date and the topic of the pdf in the name of it - I uploaded these functions up here. These functions are working perfectly. But I can not get the string out of the pdf into the name of the PDF
I want to extract the part: 115500/23/0 which is part of the most documents. If this part is missing, I want the document to be named just with the following script by finding a concrete word. The last part is the Date of the document.
Currently the PDF is named: S220QXEZ6_Q65jhicl.pdf
while the word "Ermittlungsakte" got already found in the Document. This part of the script is already working. The Date function is working as well. Missing is the part of the string XXXXXX/XX/X in the document's name.
We don't want the PDF -- we want the text that your OCR steps are extracting from the PDF.
That's important because your OCR routines may behave differently from ours, especially if you've any language-specific training/dictionaries involved.
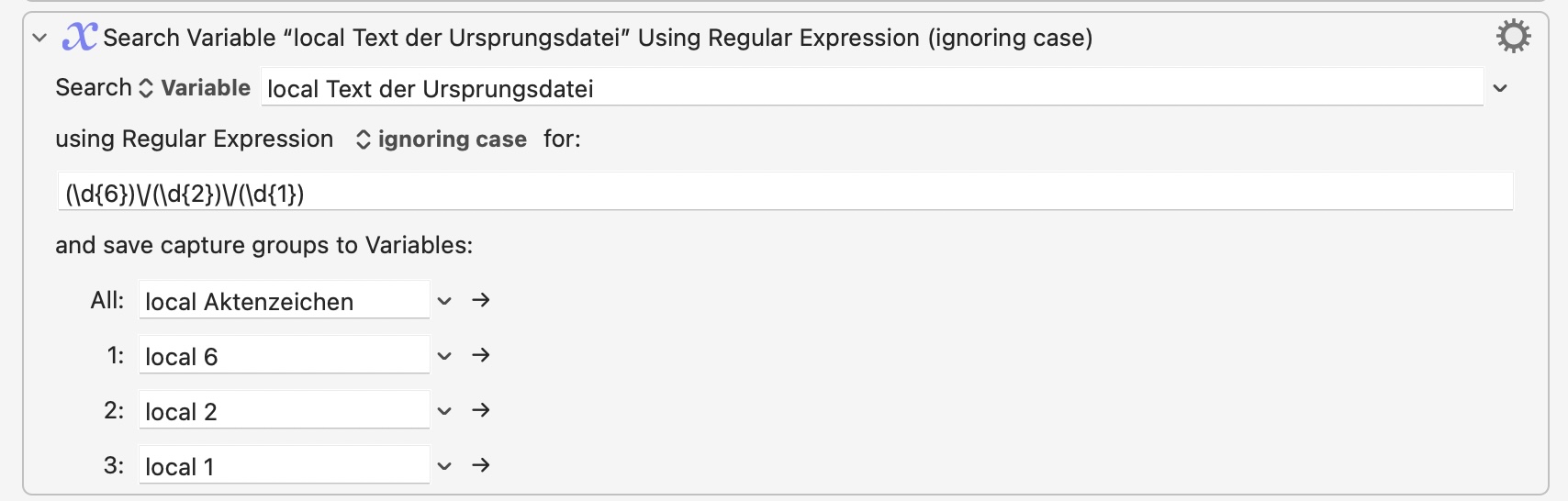
Try adding an action that puts the variable local Text der Ursprungsdatei (I think that's the right one!) onto the clipboard just before you do your regular expression search, then you can paste it into a TextEdit document or similar and upload that here so people can see it.
I routinely extract text from PDF's, but I don't involve OCR (and its errors). I use pdftotext (of Xpdf), then I process the resulting txt files with regex. All of this is via KM.
Is the string you are trying to get always proceeded with Ihr Zeichen: AZ: ?
If so this regex would find the string you are after and save to a variable.
Ihr Zeichen: AZ: (.+)
my approach was to open the pdf in AcrobatReader then select all then paste to clipboard then search the clipboard for the string
The macro did found out all of the strings in the documents but it also extracted random numbers out of the document when it did not find the exact string:
In that case the string was not completed by the writer of the document - so I like to have the macro to name it without any string by using the other parts of the macro. And when the macro neather found the string nor the scripted content, it want it to be named like "not found - please rename it manually.
Hi there, I struggle to make this work on Apple Silicon 13.4
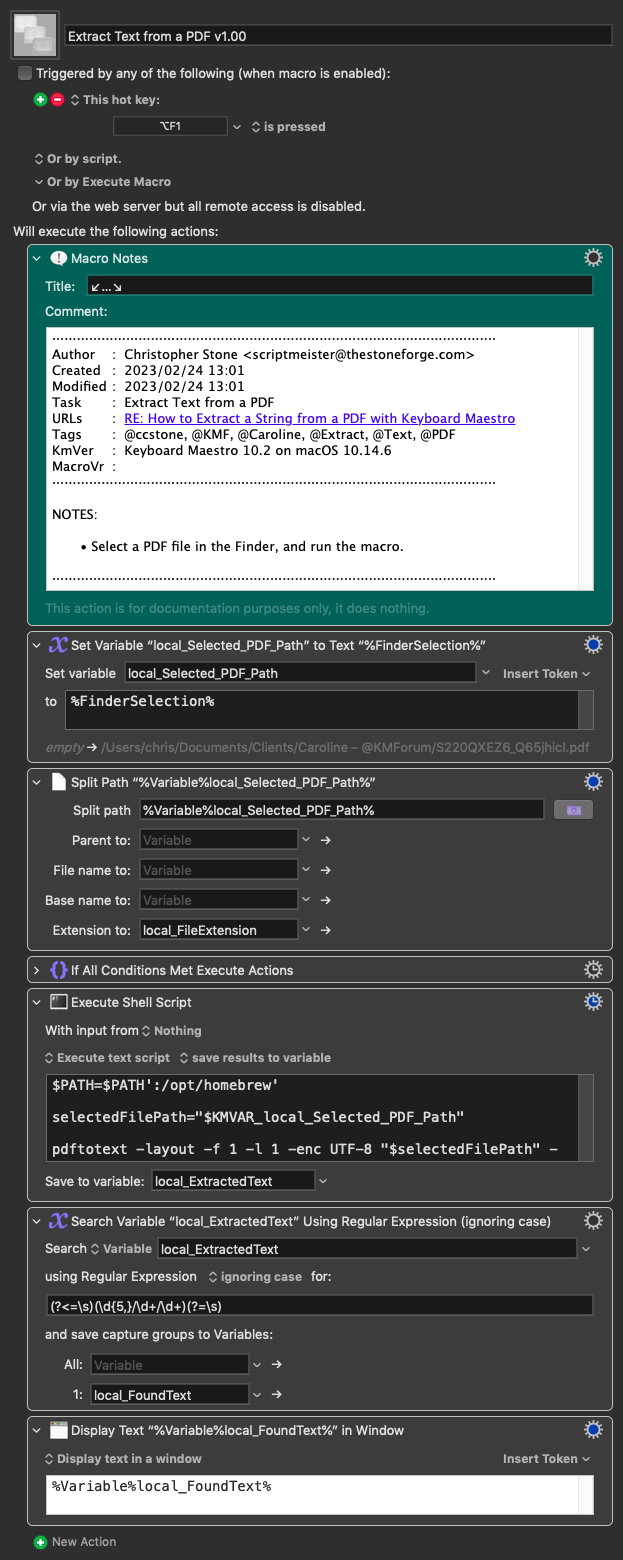
The macro stops at the shell script execution. If I run pdftotext command on terminal it works fine. Might be something to do with the homebrew $PATH?
Execute a Shell Script failed with script error: text-script: line 1: /usr/bin:/bin:/usr/sbin:/sbin=/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/homebrew: No such file or directory
text-script: line 5: pdftotext: command not found. Macro “Extract Text from a PDF v1.00” cancelled (while executing Execute Shell Script).
$PATH is irrelevant is you've specified the path to the application. It comes into play when you don't. But it doesn't hurt to confirm the location:
which pdftotext
Chris Stone wrote a nice macro to write your $PATH to a Keyboard Maestro ENV_PATH (or some such) which duplicates the environment for Keyboard Maestro shell scripts. I couldn't find it on a recent search, though. It's a once-and-done thing. You could also paste your $PATH into a variable of that name.