JS, AS, PY: I find I can code faster if everything has the same name in each scripting language, or if I can at least look up the details in each language by a single key : -)
JavaScript
https://github.com/RobTrew/prelude-jxa
// justifyLeft :: Int -> Char -> String -> String
const justifyLeft = n =>
// The string s, followed by enough padding (with
// the character c) to reach the string length n.
c => s => n > s.length ? (
s.padEnd(n, c)
) : s;
// justifyRight :: Int -> Char -> String -> String
const justifyRight = n =>
// The string s, preceded by enough padding (with
// the character c) to reach the string length n.
c => s => n > s.length ? (
s.padStart(n, c)
) : s;
AppleScript
https://github.com/RobTrew/prelude-applescript
-- justifyLeft :: Int -> Char -> String -> String
on justifyLeft(n, cFiller, strText)
if n > length of strText then
text 1 thru n of (strText & replicate(n, cFiller))
else
strText
end if
end justifyLeft
-- justifyRight :: Int -> Char -> String -> String
on justifyRight(n, cFiller, strText)
if n > length of strText then
text -n thru -1 of ((replicate(n, cFiller) as text) & strText)
else
strText
end if
end justifyRight
Python
(Mnemonic wrappers around .ljust, .rjust)
# justifyLeft :: Int -> Char -> String -> String
def justifyLeft(n):
'''A string padded at right to length n,
using the padding character c.
'''
return lambda c: lambda s: s.ljust(n, c)
# justifyRight :: Int -> Char -> String -> String
def justifyRight(n):
'''A string padded at left to length n,
using the padding character c.
'''
return lambda c: lambda s: s.rjust(n, c)
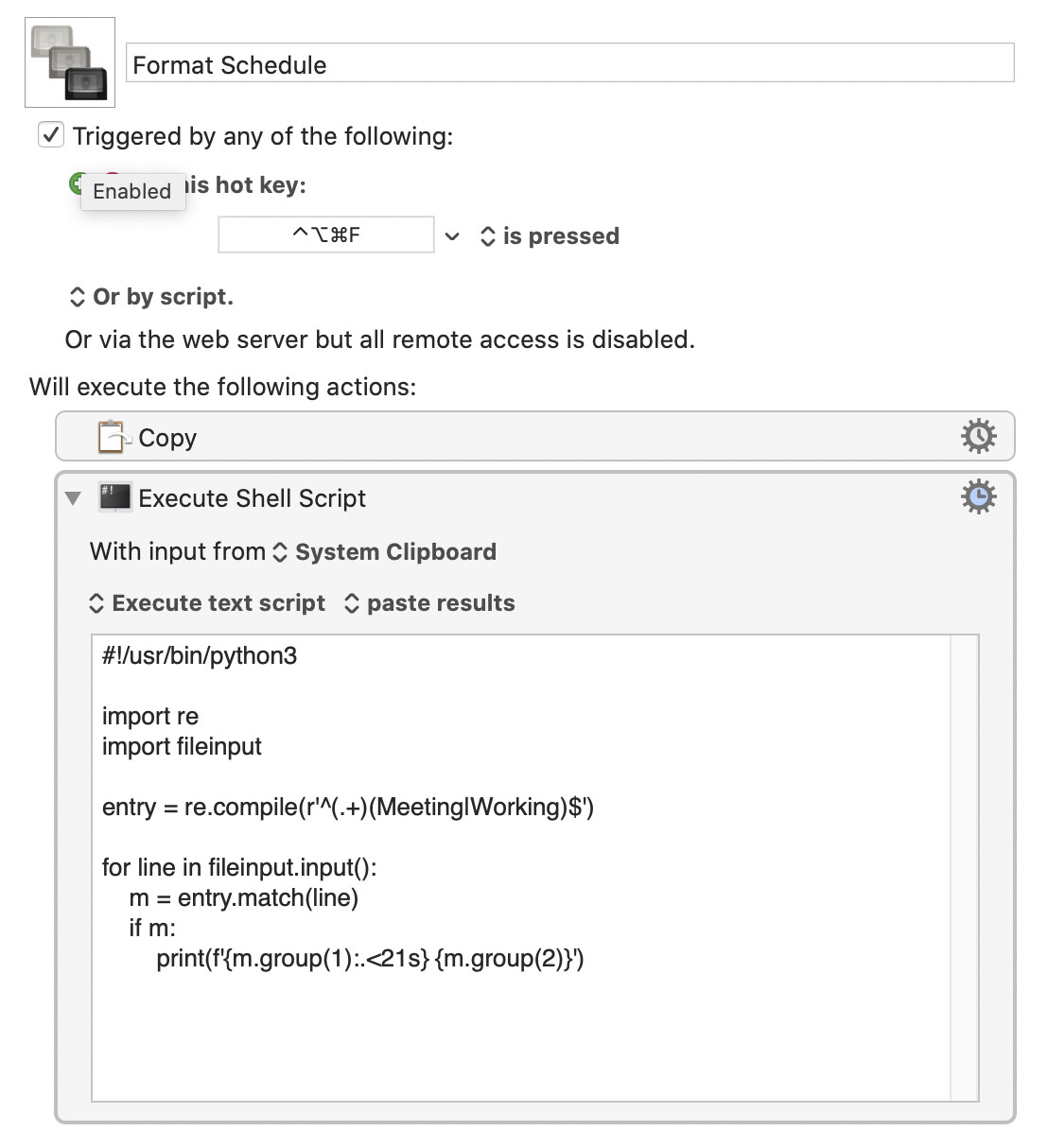
FWIW an AppleScript version
use AppleScript version "2.4"
use framework "Foundation"
use scripting additions
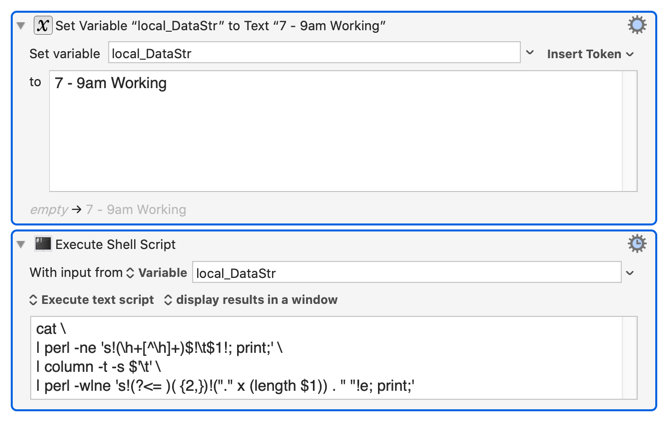
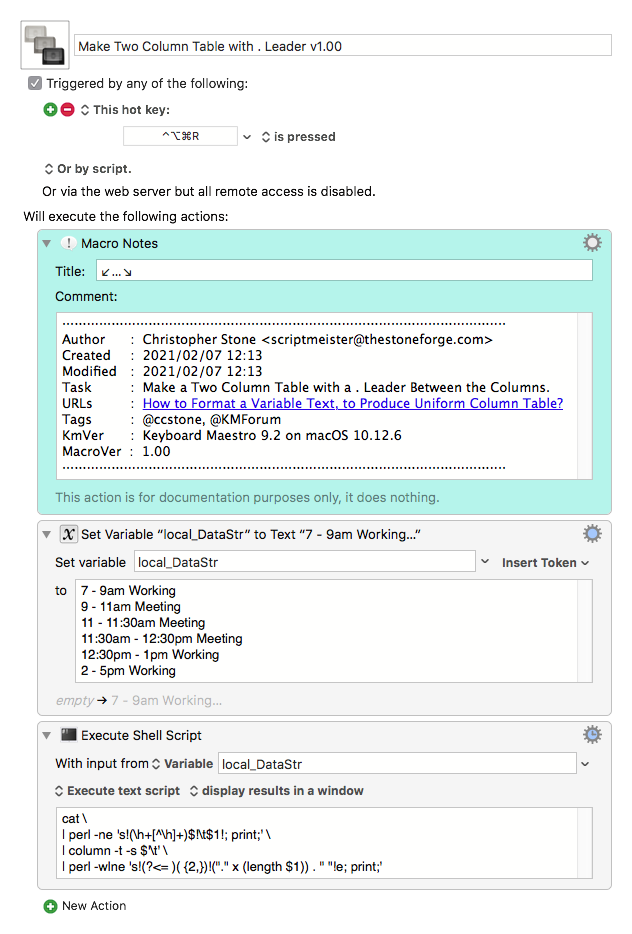
--------- LEFT JUSTIFY TIMES IN SCHEDULE WITH DOTS -------
on run
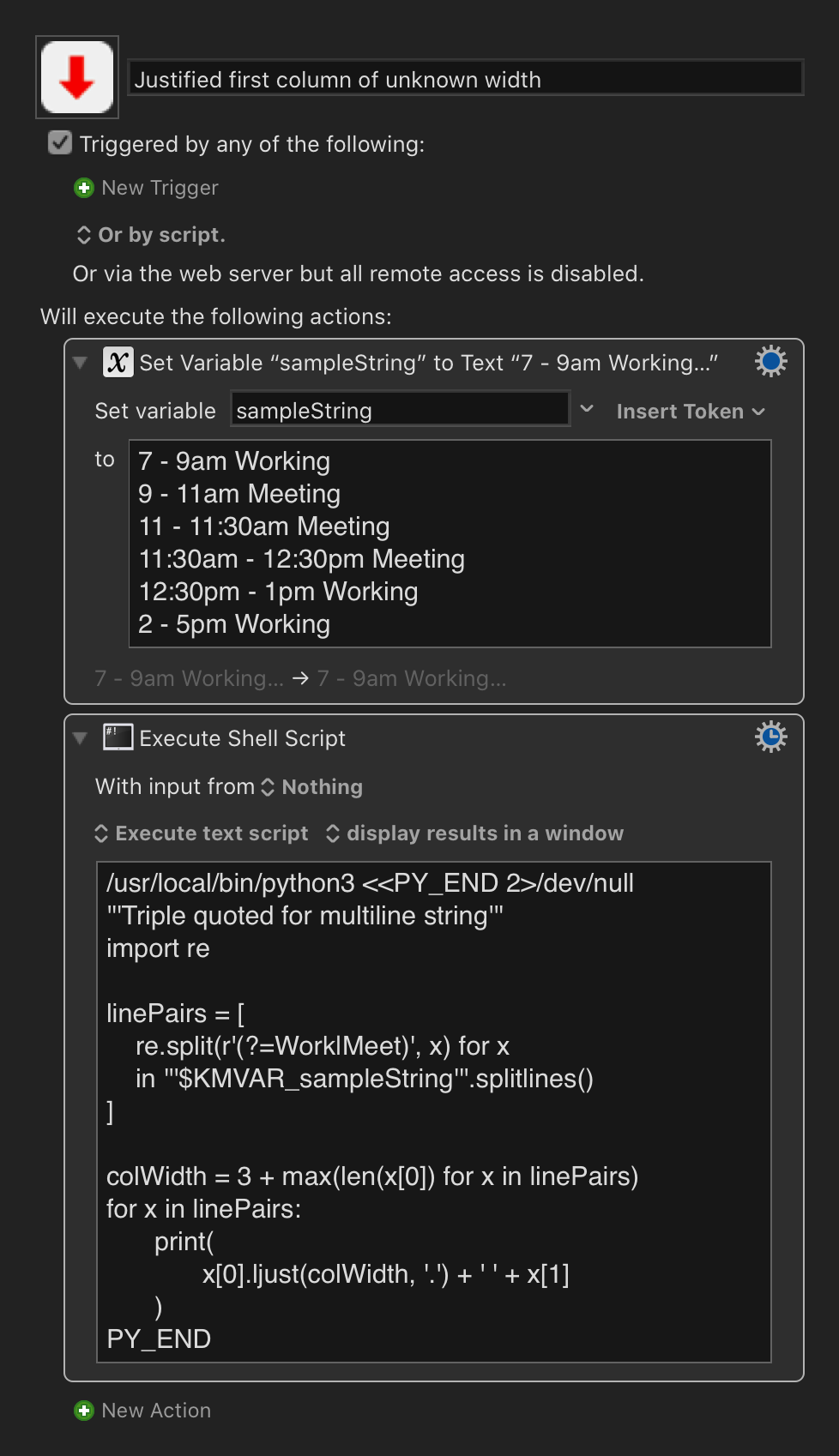
set schedule to " 7 - 9am Working\n 9 - 11am Meeting\n 11 - 11:30am Meeting\n 11:30am - 12:30pm Meeting\n 12:30pm - 1pm Working\n 2 - 5pm Working"
script split
on |λ|(s)
set i to 1 + (location of (item 1 of regexMatches(" (?=[MW])", s)))
{text 1 thru i of s, text i thru -1 of s}
end |λ|
end script
set linePairs to map(split, paragraphs of schedule)
set columnWidth to 3 + maximum(map(compose(|length|, fst), linePairs))
script format
on |λ|(x)
justifyLeft(columnWidth, ".", fst(x)) & snd(x)
end |λ|
end script
unlines(map(format, linePairs))
end run
----------- REUSABLE GENERICS PASTED FROM A MENU ---------
-- https://github.com/RobTrew/prelude-applescript
-- compose (<<<) :: (b -> c) -> (a -> b) -> a -> c
on compose(f, g)
script
property mf : mReturn(f)
property mg : mReturn(g)
on |λ|(x)
mf's |λ|(mg's |λ|(x))
end |λ|
end script
end compose
-- foldl :: (a -> b -> a) -> a -> [b] -> a
on foldl(f, startValue, xs)
tell mReturn(f)
set v to startValue
set lng to length of xs
repeat with i from 1 to lng
set v to |λ|(v, item i of xs, i, xs)
end repeat
return v
end tell
end foldl
-- fst :: (a, b) -> a
on fst(tpl)
if class of tpl is record then
|1| of tpl
else
item 1 of tpl
end if
end fst
-- justifyLeft :: Int -> Char -> String -> String
on justifyLeft(n, c, s)
-- The string s padded to width n with
-- replications of the character c.
if n > length of s then
text 1 thru n of (s & replicate(n, c))
else
s
end if
end justifyLeft
-- length :: [a] -> Int
on |length|(xs)
set c to class of xs
if list is c or string is c then
length of xs
else
(2 ^ 29 - 1) -- (maxInt - simple proxy for non-finite)
end if
end |length|
-- mReturn :: First-class m => (a -> b) -> m (a -> b)
on mReturn(f)
-- 2nd class handler function lifted into 1st class script wrapper.
if script is class of f then
f
else
script
property |λ| : f
end script
end if
end mReturn
-- map :: (a -> b) -> [a] -> [b]
on map(f, xs)
-- The list obtained by applying f
-- to each element of xs.
tell mReturn(f)
set lng to length of xs
set lst to {}
repeat with i from 1 to lng
set end of lst to |λ|(item i of xs, i, xs)
end repeat
return lst
end tell
end map
-- maximum :: Ord a => [a] -> a
on maximum(xs)
script
on |λ|(a, b)
if a is missing value or b > a then
b
else
a
end if
end |λ|
end script
foldl(result, missing value, xs)
end maximum
-- replicate :: Int -> String -> String
on replicate(n, s)
-- n replications of the string s.
set out to ""
if n < 1 then return out
set dbl to s
repeat while (n > 1)
if (n mod 2) > 0 then set out to out & dbl
set n to (n div 2)
set dbl to (dbl & dbl)
end repeat
return out & dbl
end replicate
-- snd :: (a, b) -> b
on snd(tpl)
if class of tpl is record then
|2| of tpl
else
item 2 of tpl
end if
end snd
-- regexMatches :: Regex String -> String -> [[String]]
on regexMatches(strRegex, strHay)
set ca to current application
-- NSNotFound handling and and High Sierra workaround due to @sl1974
set NSNotFound to a reference to 9.22337203685477E+18 + 5807
set oRgx to ca's NSRegularExpression's regularExpressionWithPattern:strRegex ¬
options:((ca's NSRegularExpressionAnchorsMatchLines as integer)) ¬
|error|:(missing value)
set oString to ca's NSString's stringWithString:strHay
script matchString
on |λ|(m)
script rangeMatched
on |λ|(i)
tell (m's rangeAtIndex:i)
set intFrom to its location
if NSNotFound ≠ intFrom then
text (intFrom + 1) thru (intFrom + (its |length|)) of strHay
else
missing value
end if
end tell
end |λ|
end script
end |λ|
end script
script asRange
on |λ|(x)
range() of x
end |λ|
end script
map(asRange, (oRgx's matchesInString:oString ¬
options:0 range:{location:0, |length|:oString's |length|()}) as list)
end regexMatches
-- splitRegex :: Regex -> String -> [String]
on splitRegex(strRegex, str)
set lstMatches to regexMatches(strRegex, str)
if length of lstMatches > 0 then
script preceding
on |λ|(a, x)
set iFrom to start of a
set iLocn to (location of x)
if iLocn > iFrom then
set strPart to text (iFrom + 1) thru iLocn of str
else
set strPart to ""
end if
{parts:parts of a & strPart, start:iLocn + (length of x) - 1}
end |λ|
end script
set recLast to foldl(preceding, {parts:[], start:0}, lstMatches)
set iFinal to start of recLast
if iFinal < length of str then
parts of recLast & text (iFinal + 1) thru -1 of str
else
parts of recLast & ""
end if
else
{str}
end if
end splitRegex
-- unlines :: [String] -> String
on unlines(xs)
-- A single string formed by the intercalation
-- of a list of strings with the newline character.
set {dlm, my text item delimiters} to ¬
{my text item delimiters, linefeed}
set s to xs as text
set my text item delimiters to dlm
s
end unlines
 operator (
operator (