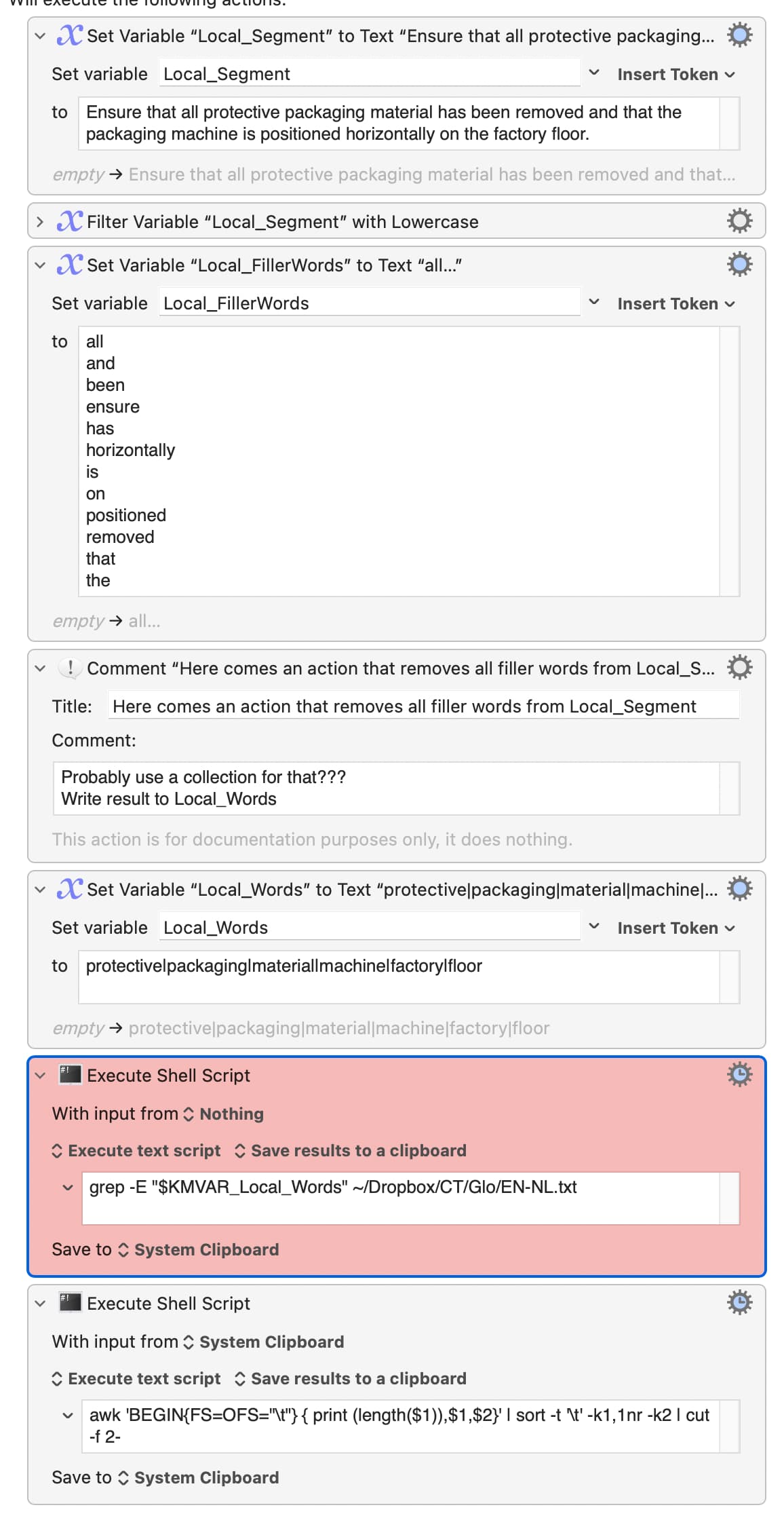
I am working on a macro that collects the "meaningful" nouns of a segment (translator speak for sentences, table cells, TOC entries etc.) and then collects all lines from a tab-delimited glossary with two columns that contain such a noun.
I have a few questions about this:
What is the smartest way (in terms of speed) to combine several nouns in one grep action?
How can I make sure that word boundaries are respected? (Adding "-wo" doesn't do the trick ;).
As a bonus question, is it possible to grep only from the left side of the glossary, i.e. before each tab?
Without seeing examples of input text and desired output, I am not sure about what precisely you are tryng to do, despite your description (maybe that's just me! ). However, I wonder if you have considered matching words using the grep sequence \w+
Here is an example of the glossary to filter for the words machine, packaging, etc.
And there is also the desired outcome of the filtering. However, word boundaries aren't respected yet, so results.txt also contains the plural of machine, etc. And it also contains lines where 'machine' is at the wrong side of the tab character. So the definitive, correct results file will be smaller ... Archive.zip (482.1 KB)
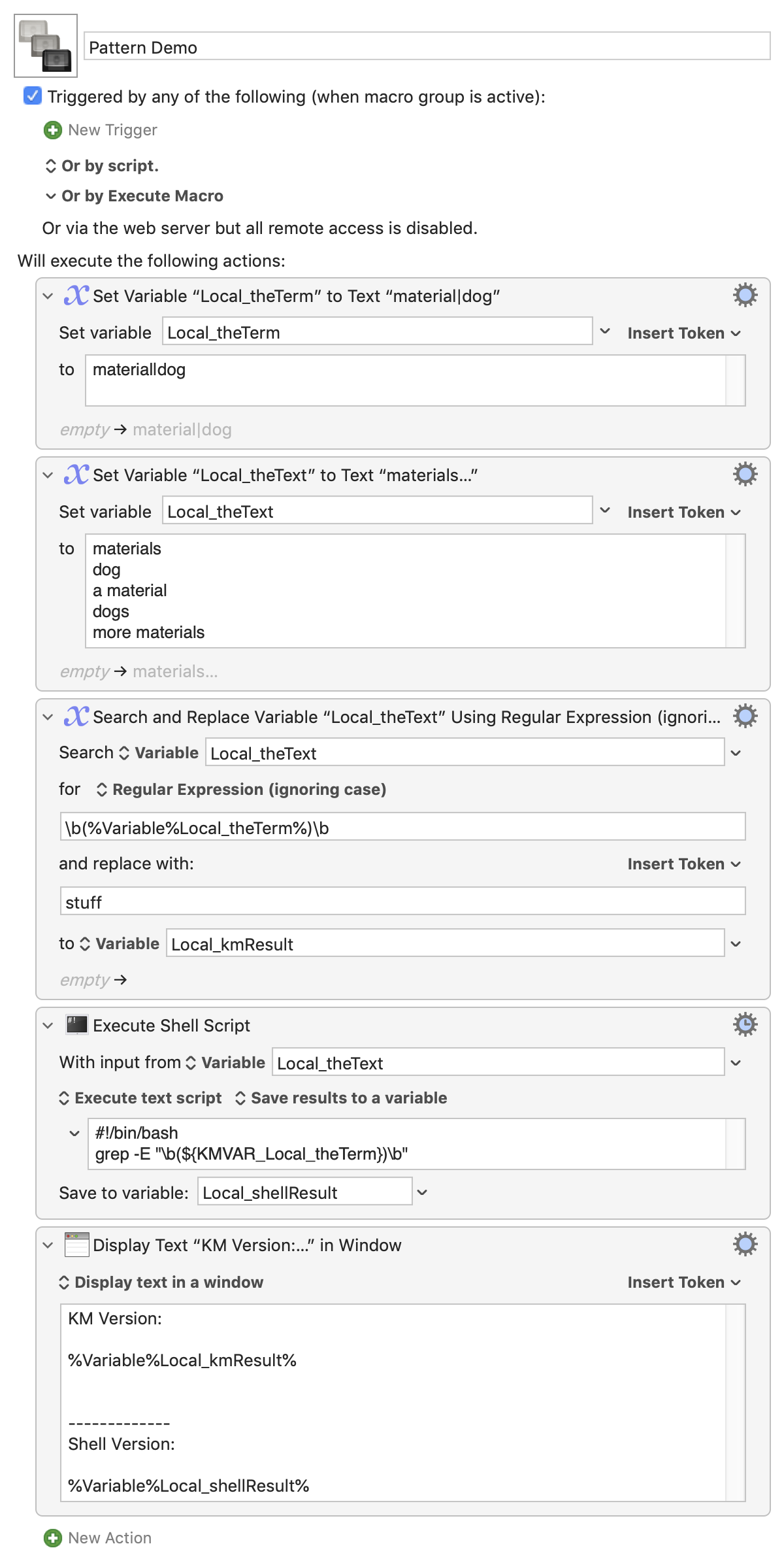
There's no "whole word" switch, AFAIK. Instead, include the word boundaries in your pattern. So, to match ward but not award, awards, or wards:
\bward\b
Use ( and ) to enclose your list, and | to separate the search terms. So to find whole-word cat, dog, or fish:
\b(cat|dog|fish)\b
Depends where/how you are doing this -- A KM action to delete everything from the first tab to the line end of each line, a "For Each" that takes everything up to the first tab and feeds it to your regex, shell script and cut -d " " -f 1, where there's a tab between the "s.
cut is a PITA when it comes to using the tab character as a delimiter -- use double-quotes around it and in KM Editor use the tab key, and in Terminal use ⌃V then the tab key.
This doesn't work. When I surround the $KMVAR with \b( and )\b, I get an output where the plural "materials" is listed.
When I surround Local_Words, I get an error:
2024-07-19 09:29:31 Action 16017439 failed: Task failed with status 1
2
About the third task: I was thinking: perhaps I should filter the result a second time, to remove lines where the local words aren't present before the tab. I'll have to think about how to do that :).
This is probably not an actual "error" as we normally know them -- grep is odd in that it returns a result code of 1 when no match is found, but almost every other *nix utility returns 1 on an actual error, so that's how KM interprets it.
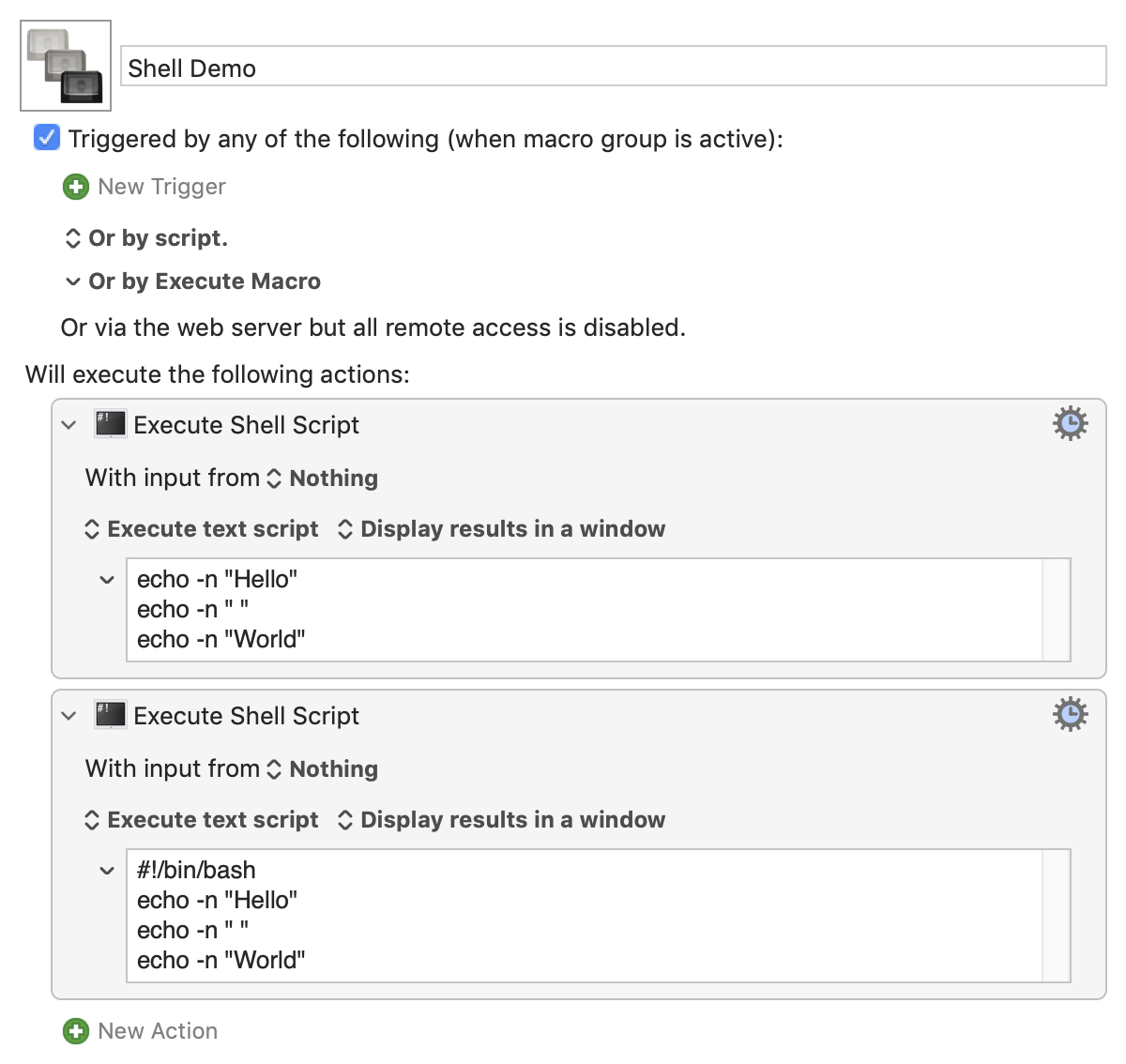
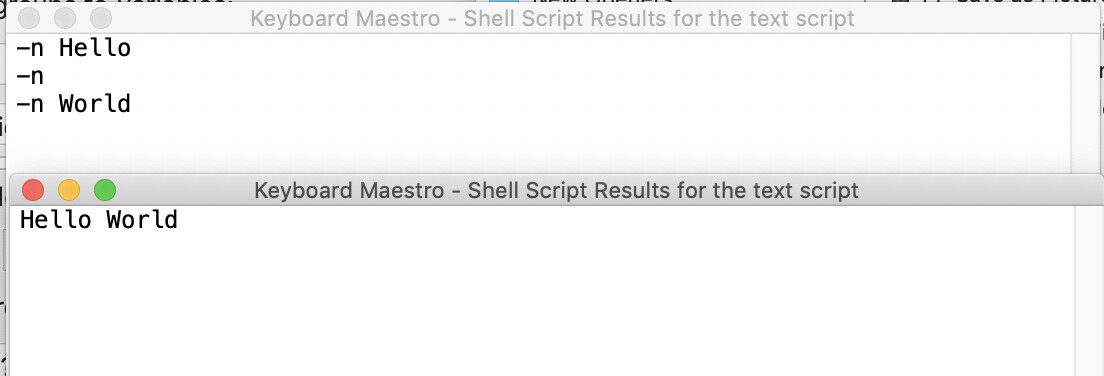
...because the sh buil-in echo doesn't accept the -n argument.
So it's good practice to specify the shell to use -- something I keep not doing, so I'm trying to do better... And yes, I probably shouldn't be assuming the user's $PATH is correct, and should be using /usr/bin/grep too!
(There's an argument that we should actually be starting with
#!/usr/bin/env bash
...which is "use the user's preferred version of bash, a first-line you'll often see in scripts you find on the web. I'm not so sure about that when it comes to a KM macro we're sharing -- there can be so many other differences in set-up to worry about that it perhaps makes sense to force the use of the OS-installed bash.)