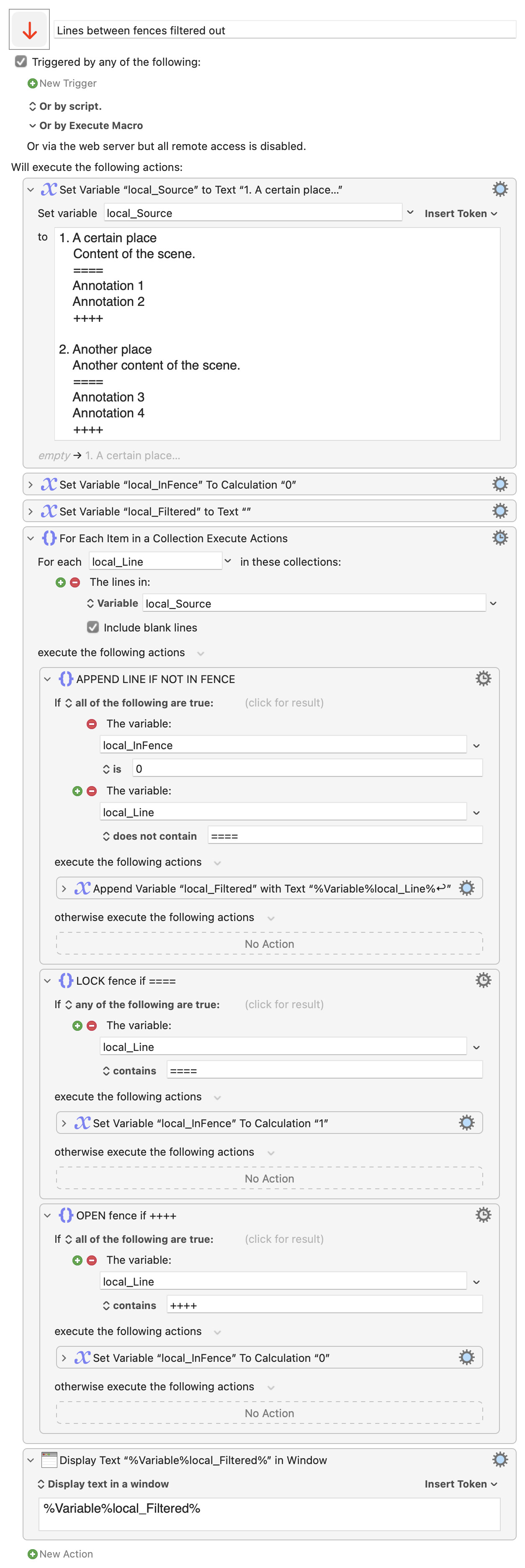
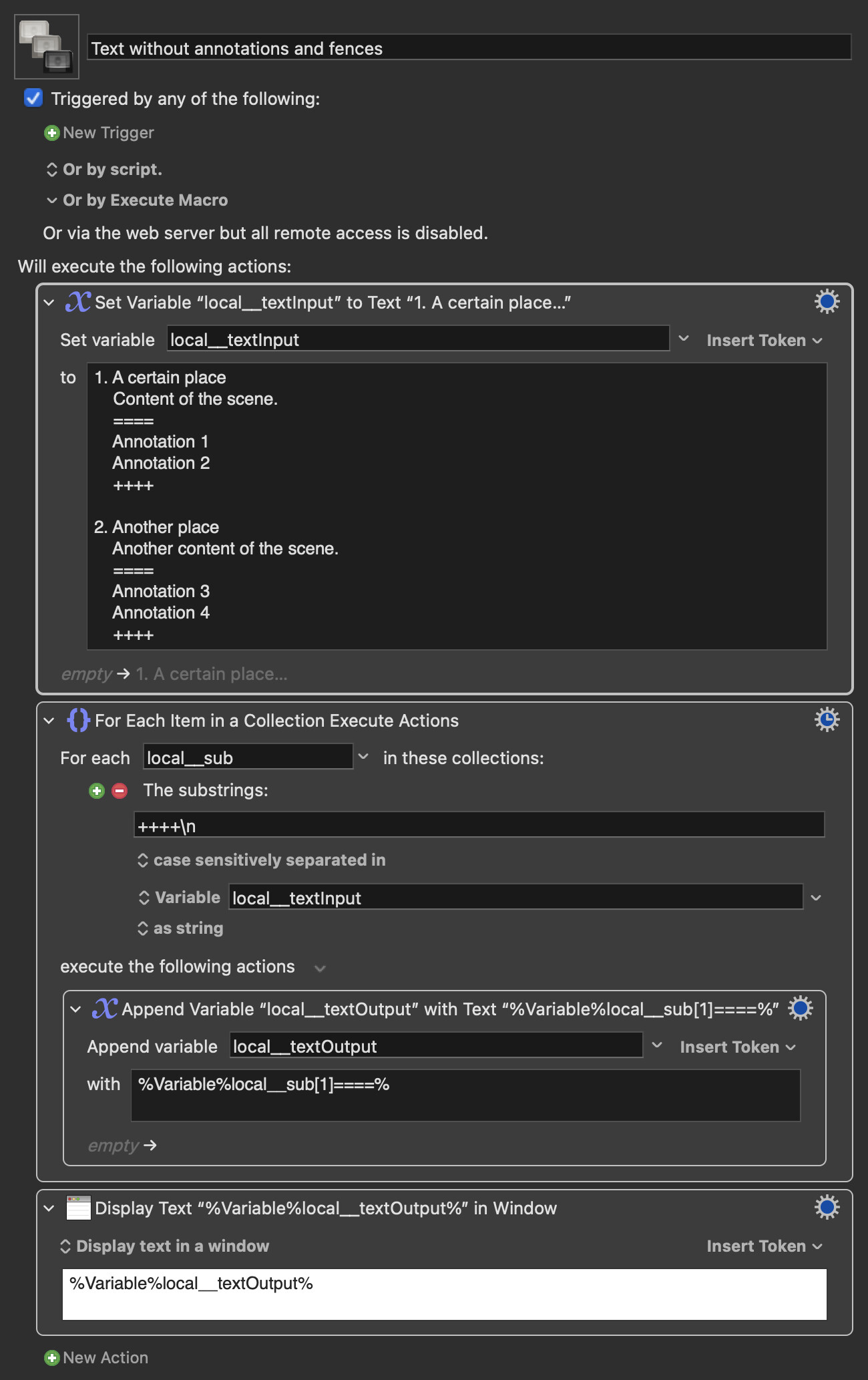
I have a very long movie script text file that includes annotations for each scene. The annotations are multi-line and are enclosed by ==== at the beginning and ++++ at the end.
I would appreciate it if you could tell me how to delete all the lines between ==== and ++++.
For example, it looks like this:
A certain place
Content of the scene.
====
Annotation 1
Annotation 2
++++
Another place
Another content of the scene.
====
Annotation 3
Annotation 4
++++
I must give you one small word of warning. If your final annotation also happens to be the last line of the file, without a newline after it, then this macro could fail to remove the last annotation. But I doubt that any normal script would have no newline after the last annotation. So I don't think you will ever see that happen.
You are welcome. Peter made a decent point about a minor error in my method, but considering that my method is one short action, it's pretty easy to understand.
Some days I prefer solutions that are all-KM actions only, but other days I'm favourable to solving problems using Execute Shell Script if the solution is quite simple there.
Nope. [^x] means every character except x. The s flag makes no difference.
Without the flag, . means any single character except any line terminating characters (\u000a, \u000b, \u000c, \u000d, \u0085, \u2028, \u2029).
With the flag, . means any single character, including the line terminating characters (\u000a, \u000b, \u000c, \u000d, \u0085, \u2028, \u2029) and also including the pair \u000d \u000a (so it could actually match two characters, which is not something I knew!).
This means you can frequently avoid the (?s) flag by using [^x] in place of . where you know x will never be present.
To be perfectly honest, I think I originally started my macro using a regex that contained a dot, and the truth is I just didn't bother to remove it, after switching to [^x], and wasn't sure if it was necessary to remove (?s). So I left it in. I should have conducted the tests that you did, but I was lazy.
is needed in the natural habitat of regular expressions (splits rather than the slightly dysfunctional search and replace association to which they were yoked by grep in the 60s)
I don't think that Keyboard Maestro provides a very native (non-script) route to splitting on multi-character strings or regexes (perhaps a For Each collection could be defined in those terms ?), but reaching, for the moment, for a script action, we can: