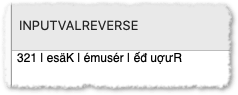On my machine, it isn’t.
It works correctly with the “simple” kind of strings like résumé, but fails with the Rượu đế test string from above. (The diacritics ́̂ and ̛̣ get detached from the letters they belong to.)
(The AppleScriptObjC method works correctly with all.)
For ease of testing, here a macro with all posted solutions so far:
[test] Ways to Reverse String.kmmacros (18.5 KB)
- Open the macro in KM Editor.
- Use “Try Action” from the contextual menu on the first action to set the variable.
- Open KM Editor > Preferences > Variables and select the “INPUTVALREVERSE” variable. Leave that window open and visible on screen.
- Now apply “Try Action” on a script action you want to test and watch the output in the variables window.
As said, for display I’m using the variables window, because the font (Menlo) used in the KM Shell Script Results window cannot handle all characters correctly.
The colors of the actions reflect the grade of Unicode compliance of the script:
- red: fails completely
- orange: OK with
résumé | Käse, fails withRượu đế - green: OK with all
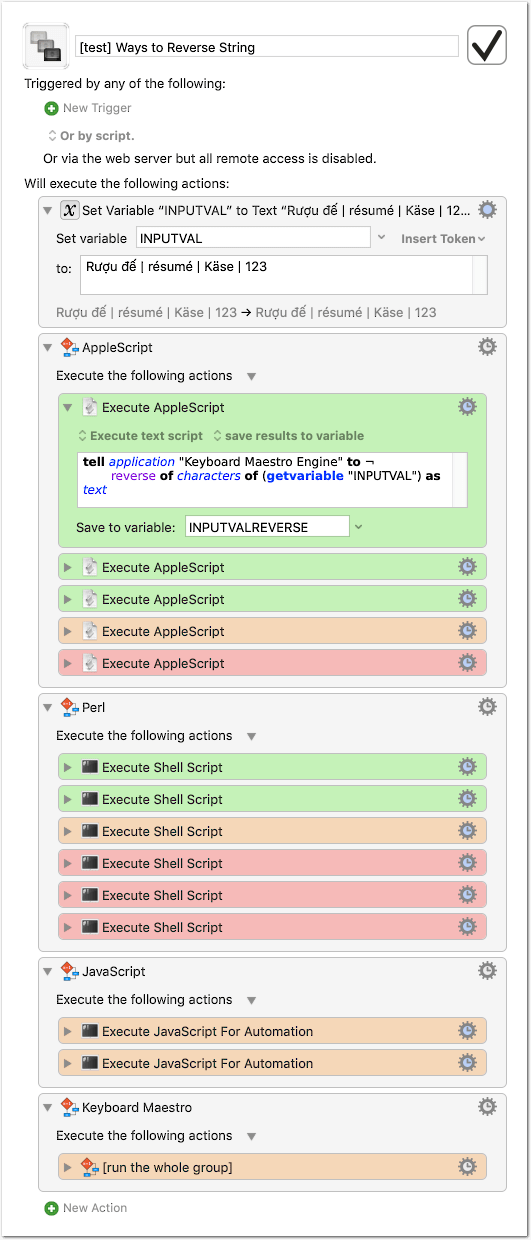
The green actions should produce this result: