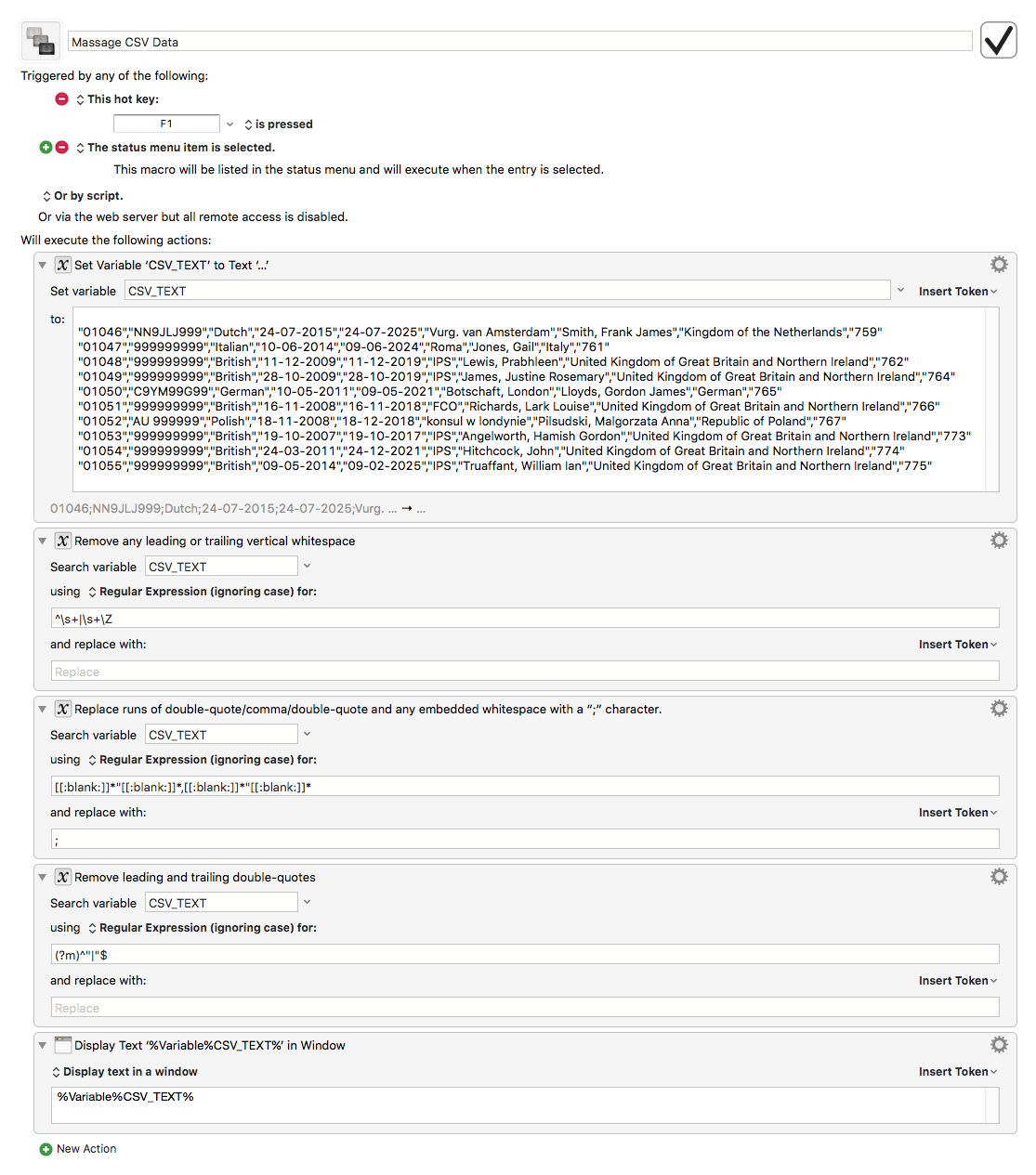
Thank you for the further replies.
Here is an entirely representative sample of data:
"01046","NN9JLJ999","Dutch","24-07-2015","24-07-2025","Vurg. van Amsterdam","Smith, Frank James","Kingdom of the Netherlands","759"
"01047","999999999","Italian","10-06-2014","09-06-2024","Roma","Jones, Gail","Italy","761"
"01048","999999999","British","11-12-2009","11-12-2019,"IPS","Lewis, Prabhleen","United Kingdom of Great Britain and Northern Ireland","762"
"01049","999999999","British","28-10-2009","28-10-2019","IPS","James, Justine Rosemary","United Kingdom of Great Britain and Northern Ireland","764"
"01050","C9YM99G99","German","10-05-2011,"09-05-2021","Botschaft, London","Lloyds, Gordon James","German","765"
"01051","999999999","British","16-11-2008","16-11-2018","FCO","Richards, Lark Louise","United Kingdom of Great Britain and Northern Ireland","766"
"01052","AU 999999","Polish",18-11-2008,"18-12-2018","konsul w londynie","Pilsudski, Malgorzata Anna","Republic of Poland","767"
"01053","999999999","British","19-10-2007","19-10-2017","IPS","Angelworth, Hamish Gordon","United Kingdom of Great Britain and Northern Ireland","773"
"01054","999999999","British","24-03-2011","24-12-2021","IPS","Hitchcock, John","United Kingdom of Great Britain and Northern Ireland","774"
"01055","999999999","British","09-05-2014",09-02-2025,"IPS","Truaffant, William Ian","United Kingdom of Great Britain and Northern Ireland","775"
And here is what I would like to end up with:
01046;NN9JLJ999;Dutch;24-07-2015;24-07-2025;Vurg. van Amsterdam;Smith, Frank James,Kingdom of the Netherlands;759;
01047;999999999;Italian;10-06-2014;09-06-2024;Roma;Jones, Gail;Italy;761;
01048;999999999;British;11-12-2009;11-12-2019,;IPS;Lewis, Prabhleen;United Kingdom of Great Britain and Northern Ireland;762;
01049;999999999;British;28-10-2009;28-10-2019;IPS;James, Justine Rosemary;United Kingdom of Great Britain and Northern Ireland;764;
01050;C9YM99G99;German;10-05-2011,;09-05-2021;Botschaft, London;Lloyds, Gordon James;German;765;
01051;999999999;British;16-11-2008;16-11-2018;FCO;Richards, Lark Louise;United Kingdom of Great Britain and Northern Ireland;766;
01052;AU 999999;Polish;,18-11-2008,;18-12-2018;konsul w londynie;Pilsudski, Malgorzata Anna;Republic of Poland;767;
01053;999999999;British;19-10-2007;19-10-2017;IPS;Angelworth, Hamish Gordon;United Kingdom of Great Britain and Northern Ireland;773;
01054;999999999;British;24-03-2011;24-12-2021;IPS;Hitchcock, John;United Kingdom of Great Britain and Northern Ireland;774;
01055;999999999;British;09-05-2014;,09-02-2025,;IPS;Truaffant, William Ian;United Kingdom of Great Britain and Northern Ireland;775;
The other databases are entirely consistent with this. As I originally wrote the only difficulty I have is removing the " at the beginning of each line, and replacing the " at the end of each line and replacing it with a ;.