Hey Victor,
Okay! Now we have something real to work with.
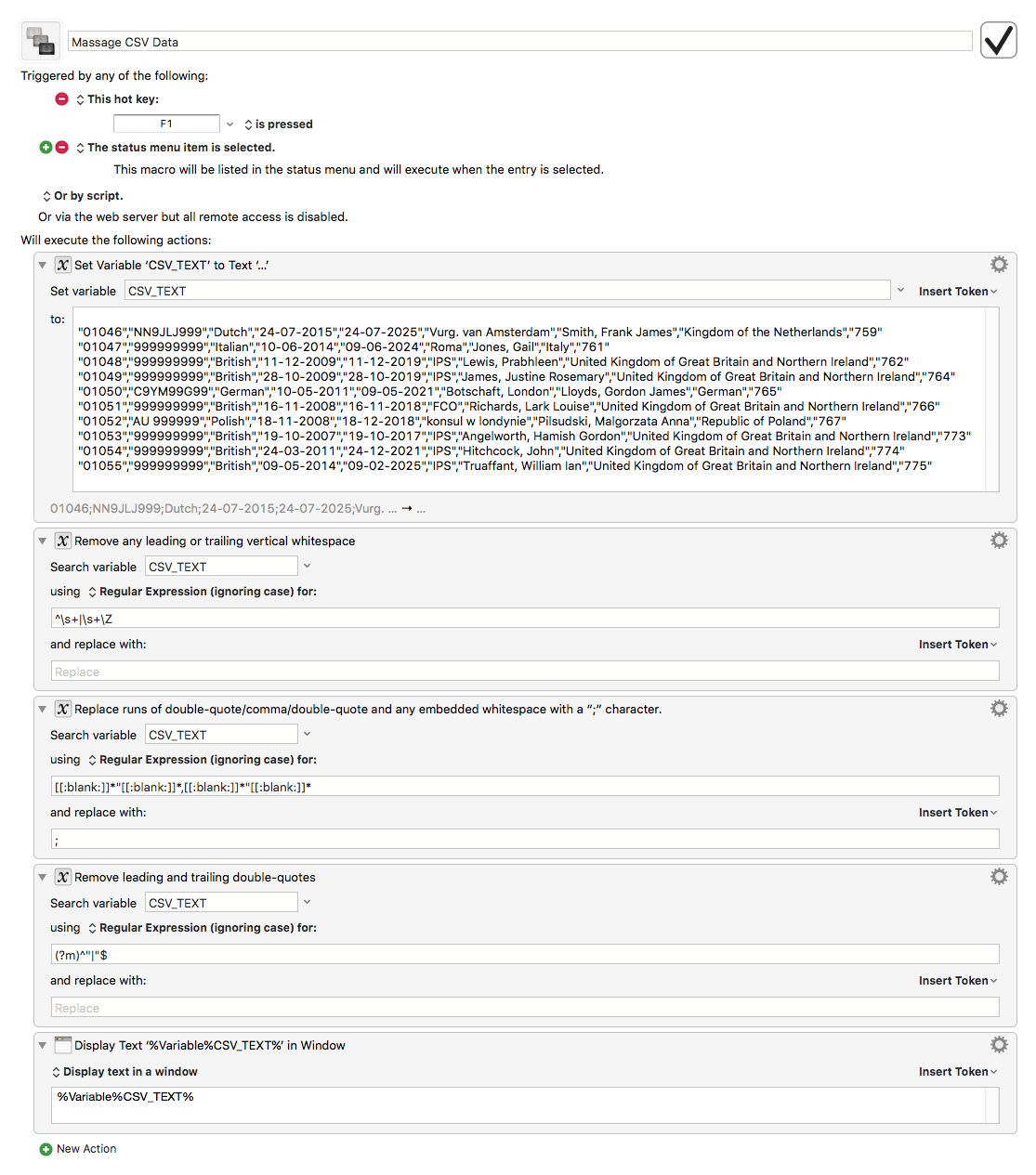
The quoting in your input data is NOT consistent in places. (e.g Some double-quotes are missing.)
Is this an error YOU introduced, or is this a problem with the original data?
I have changed the input data to be properly quoted in the CSV_TEXT for this example.
BUT it is vitally important to know if the original data is likely to contain quoting errors.
As I suspected there are special needs in the data, and you cannot simply do a rote replace of commas – since there are non-separator commas in the data.
Provided the original data is correctly consistent this job is simple.
If the original data has errors this job is still not too difficult, because understanding the exact structure and composition of the data file makes it relatively easy to repair.
-Chris
Massage CSV Data.kmmacros (5.5 KB)