That's the first example you give but the second example has the tags outside the single quotes, like this:
Is it really that inconsistent or is it just a typo?
That's the first example you give but the second example has the tags outside the single quotes, like this:
Is it really that inconsistent or is it just a typo?
That's indeed intended inconsistency. (The technical background: The editor that I use to translate, allows to hide sentence-spanning tags. This is very useful if the whole sentence is spanned: these spanning tags won't be displayed. It's a little less useful if the opening tag at the start of the sentence (or closing tag at the end) is hidden, since the corresponding closing (or opening) tag will still be displayed, like in the second variant.)
To get the match between inputs and ouputs that you after, we need to know:
If you can, try not to think in terms of 'tasks to solve' and what scripts 'do',
and instead just narrow focus exclusively down to examples of
Here is an update which broadens out the range of delimiting quotes that are recognised, to include '"{}().
Tags added to Target.kmmacros (20.5 KB)
Could you tell us:
(I absolutely appreciate the relevance of concepts like works and doesn't' work, solves and doesn't solve at your end, but here they leave us rather in the dark.
All we can work with is:
Input pairs:
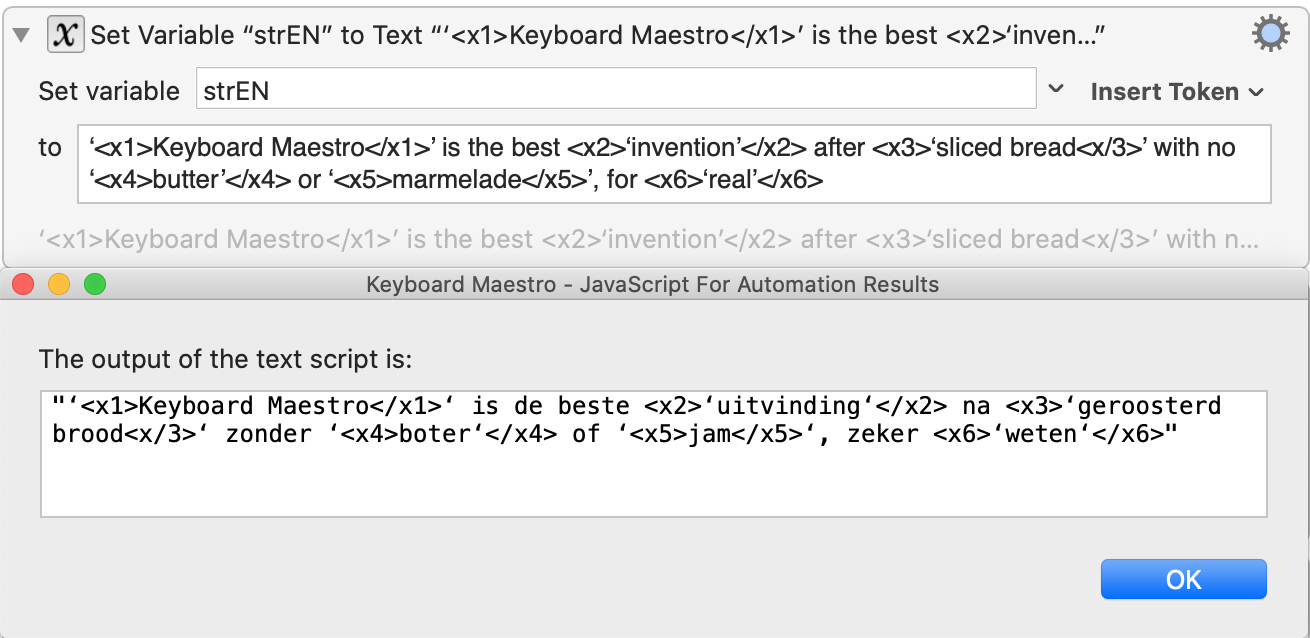
Variant 1: Paired tags only
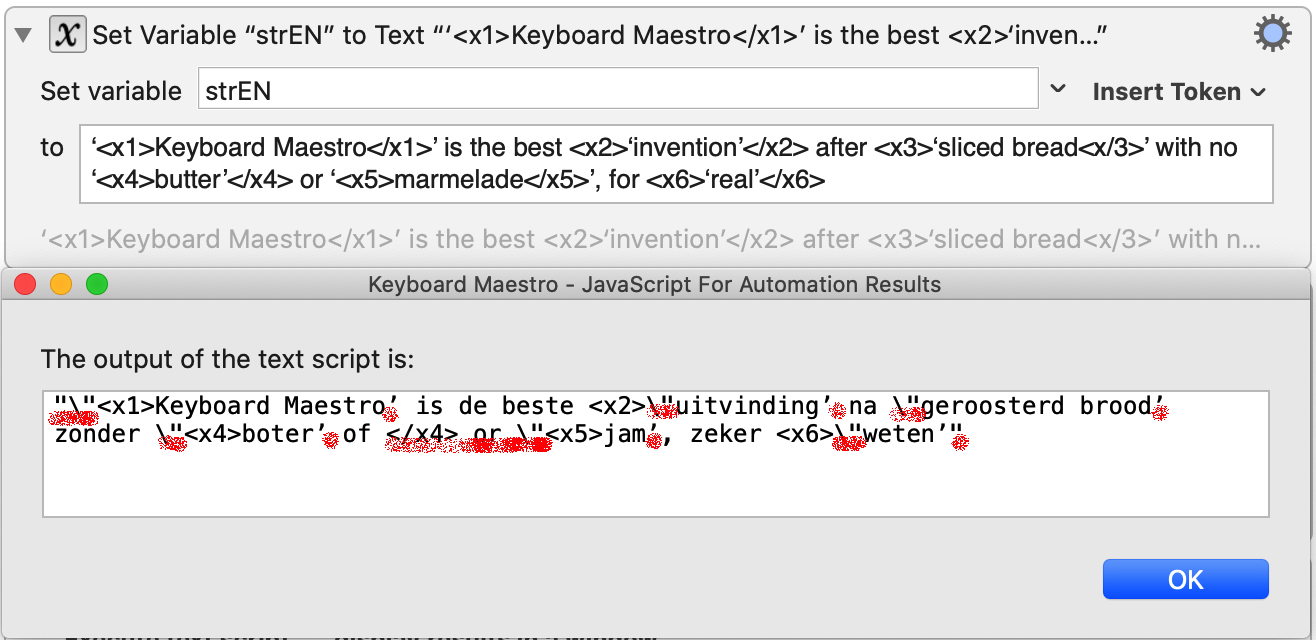
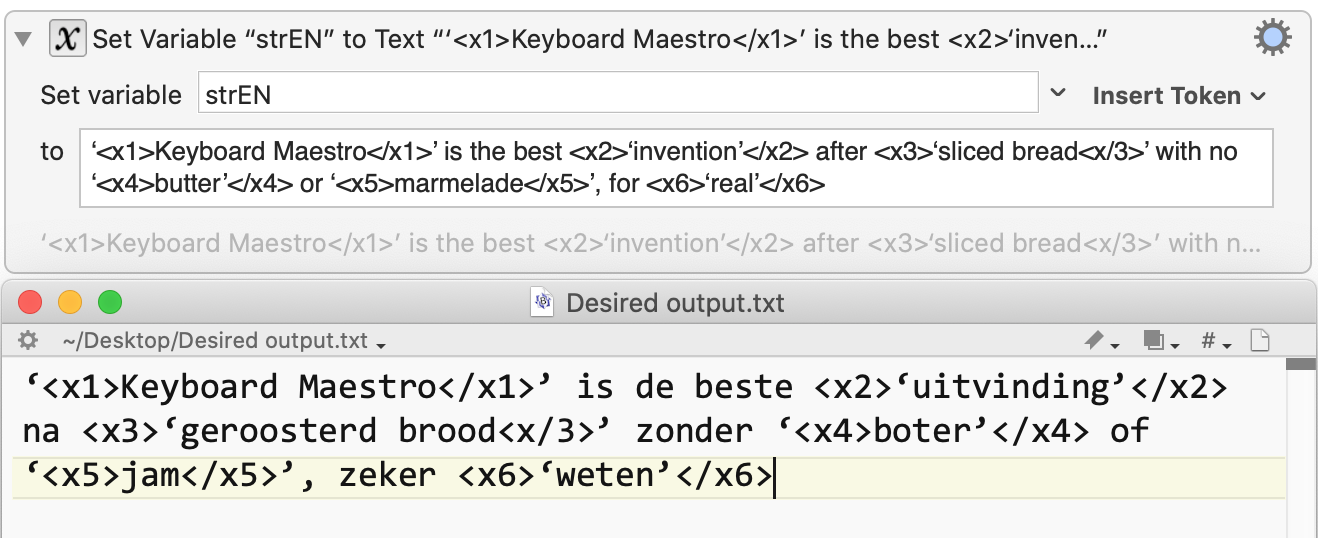
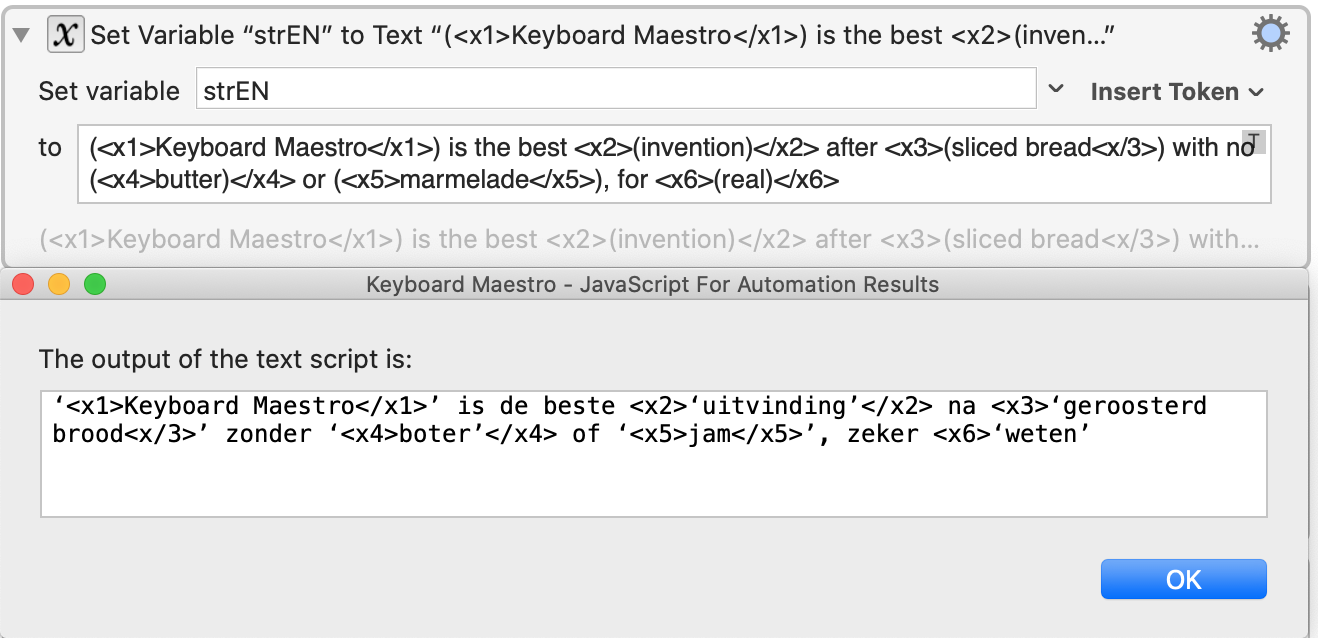
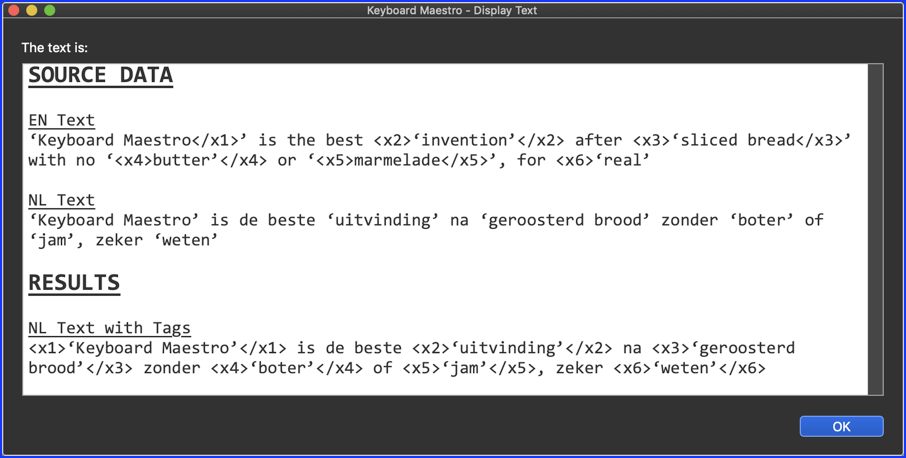
Input EN ‘<x1>Keyboard Maestro</x1>’ is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for <x6>‘real’</x6>
Input NL ‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’
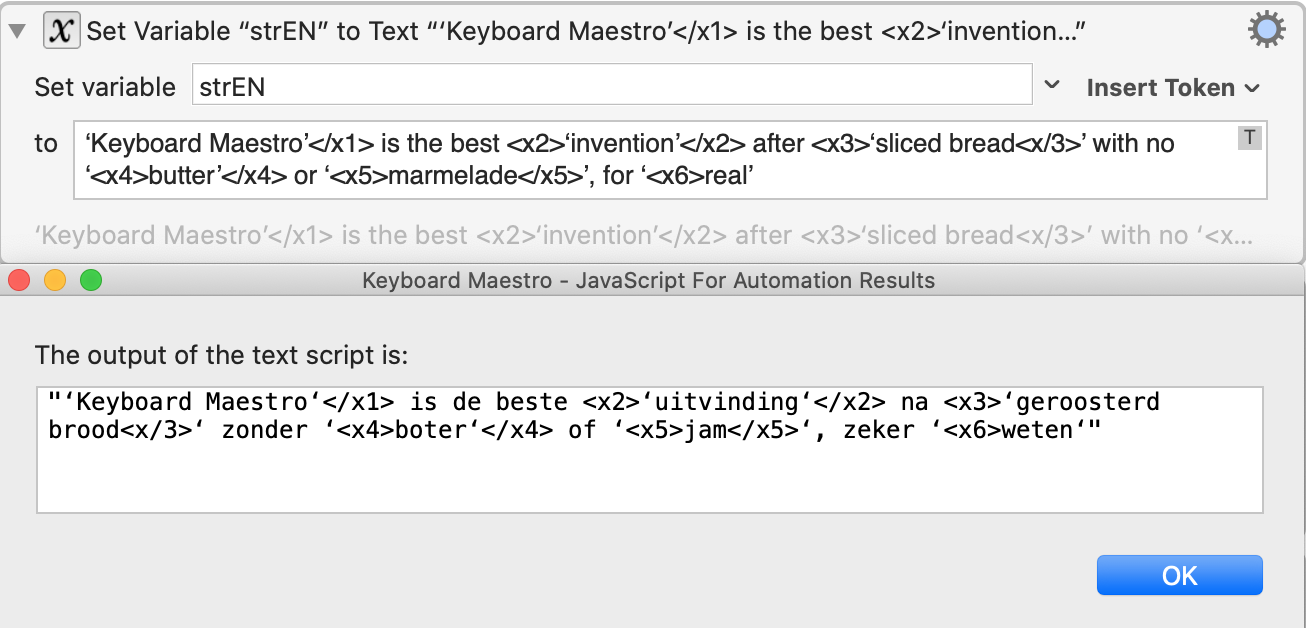
Variant 2: Paired tags and unpaired tags
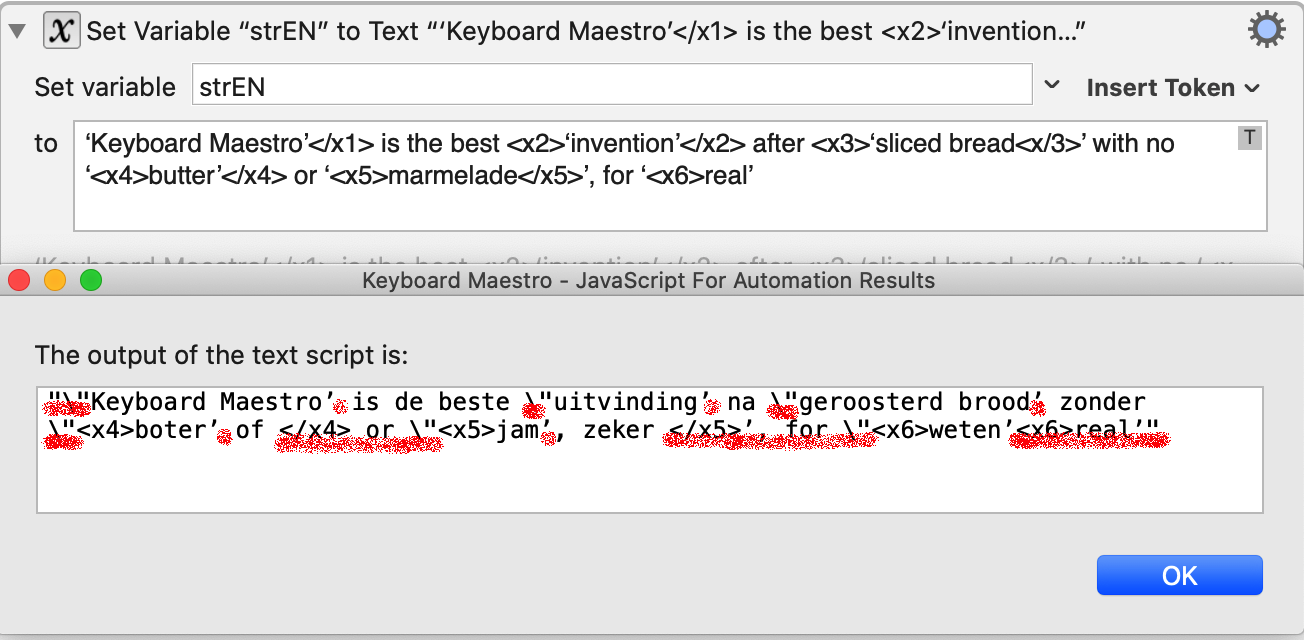
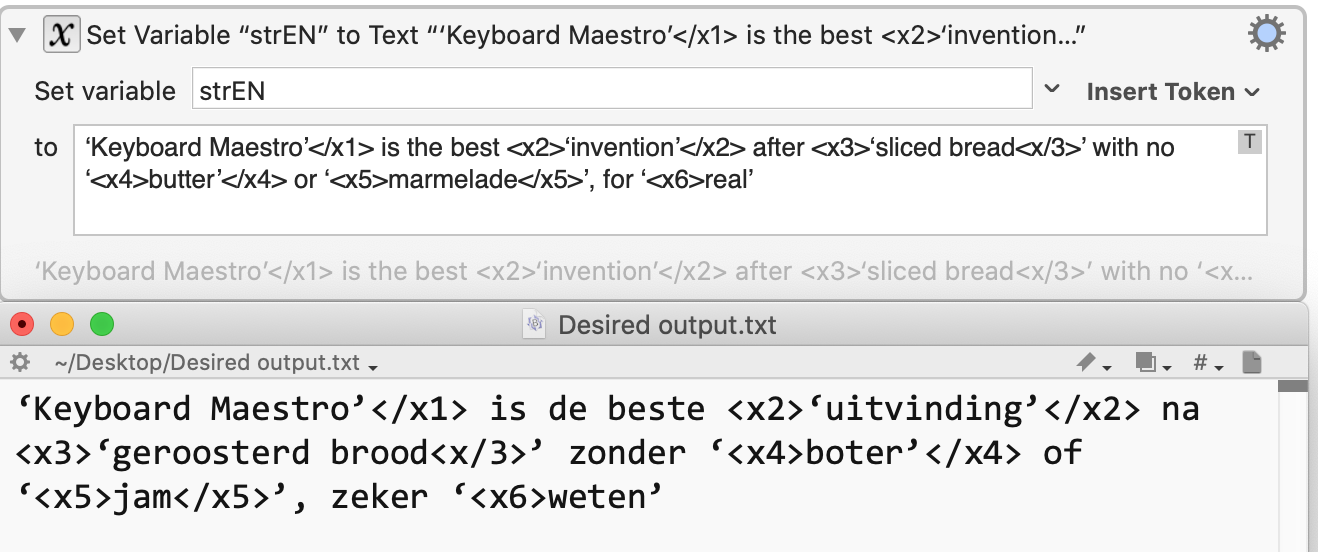
Input EN ‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for ‘<x6>real’
Input NL ‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’
What I see (I marked the undesired results in red):
What it should be:
Second variant, what I see:
What it should be:
Thanks for taking the trouble to do that – it's really helpful.
It may be more solid to break the problem down into two parts:
<numbered tags>
Let's start by trying to solve problem 1, and if we can get that right, then we can think about problem 2.
On placing the <numbered tags>, are we getting closer with this ?
Tags added to Target.kmmacros (20.9 KB)
An initial guess at stage 2 (detecting and preserving various quote pair types), when we get there, might look something like:
Tags added around various Quote pairs.kmmacros (23.6 KB)
(() => {
'use strict';
// main :: IO ()
const main = () => {
const
kme = Application('Keyboard Maestro Engine'),
kmVar = k => kme.getvariable(k),
strEN = kmVar('strEN'),
strNL = kmVar('strNL');
const delims = '\"\'\“\”\‘\’{}()';
// delimSplit :: String -> [String]
const delimSplit = s =>
groupBy(on(eq)(c => delims.includes(c)))(s);
return zipWith(
en => nl => {
return en.includes('<') ? (
`${firstTag(en)}${nl}${lastTag(en)}`
) : nl;
}
)(
delimSplit(strEN)
)(
delimSplit(strNL)
).join('');
};
// firstTag :: String -> String
const firstTag = s =>
s.startsWith('<') ? (() => {
const i = [...s].findIndex(c => '>' === c);
return -1 !== i ? (
s.slice(0, 1 + i)
) : '';
})() : '';
// lastTag :: String -> String
const lastTag = s =>
s.endsWith('>') && s !== firstTag(s) ? (() => {
const
i = [...s].reverse().findIndex(
c => '<' === c
);
return -1 !== i ? (
s.slice(s.length - (1 + i))
) : '';
})() : ''
// --------------------- GENERIC ---------------------
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: 'Tuple',
'0': a,
'1': b,
length: 2
});
// showLog :: a -> IO ()
const showLog = (...args) =>
console.log(
args
.map(JSON.stringify)
.join(' -> ')
);
// groupBy :: (a -> a -> Bool) -> [a] -> [[a]]
const groupBy = fEq =>
// Typical usage: groupBy(on(eq)(f), xs)
xs => (ys => 0 < ys.length ? (() => {
const
tpl = ys.slice(1).reduce(
(gw, x) => {
const
gps = gw[0],
wkg = gw[1];
return fEq(wkg[0])(x) ? (
Tuple(gps)(wkg.concat([x]))
) : Tuple(gps.concat([wkg]))([x]);
},
Tuple([])([ys[0]])
),
v = tpl[0].concat([tpl[1]]);
return 'string' !== typeof xs ? (
v
) : v.map(x => x.join(''));
})() : [])(list(xs));
// on :: (b -> b -> c) -> (a -> b) -> a -> a -> c
const on = f =>
// e.g. groupBy(on(eq)(length))
g => a => b => f(g(a))(g(b));
// eq (==) :: Eq a => a -> a -> Bool
const eq = a =>
// True when a and b are equivalent in the terms
// defined below for their shared data type.
b => {
const t = typeof a;
return t !== typeof b ? (
false
) : 'object' !== t ? (
'function' !== t ? (
a === b
) : a.toString() === b.toString()
) : (() => {
const kvs = Object.entries(a);
return kvs.length !== Object.keys(b).length ? (
false
) : kvs.every(([k, v]) => eq(v)(b[k]));
})();
};
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// sj :: a -> String
function sj() {
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
const args = Array.from(arguments);
return JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0]) ? [
args[1], null, args[0]
] : [args[0], null, 2]
);
}
// zipWith :: (a -> a -> b) -> [a] -> [b]
const zipWith = f => {
// A list with the length of the shorter of
// xs and ys, defined by zipping with a
// custom function, rather than with the
// default tuple constructor.
const go = xs =>
ys => 0 < xs.length ? (
0 < ys.length ? (
[f(xs[0])(ys[0])].concat(
go(xs.slice(1))(ys.slice(1))
)
) : []
) : [];
return go;
};
// MAIN --
return main();
})();
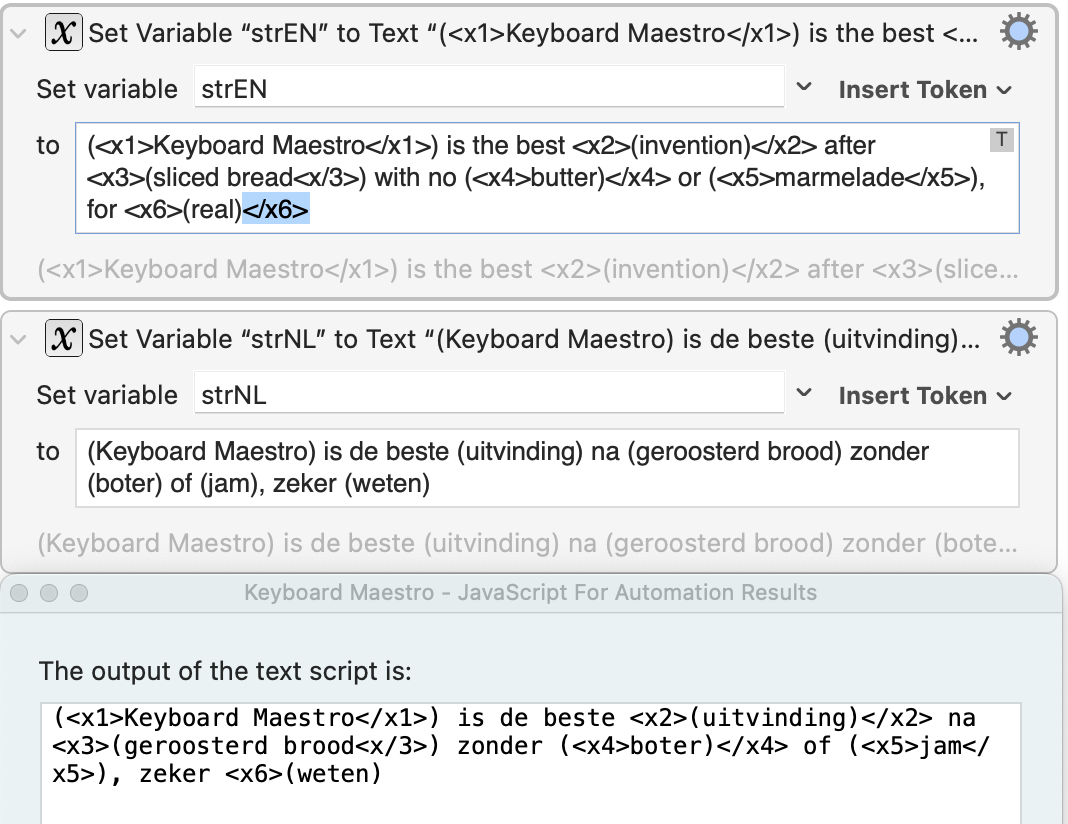
This is almost perfect. There's only the closing quote marks that don't match (‘ instead of ’). Works for both variants:
And:
I take it that This refers, in your context, to version 1 above (Tags added to Target) ?
(that draft doesn't aim to get the quotes right, so its sounds like we're making progress)
How about version 2 (the draft for stage 2 of the problem, above):
Tags added around various Quote pairs ?
What are you seeing in the output there ?
You're getting there.
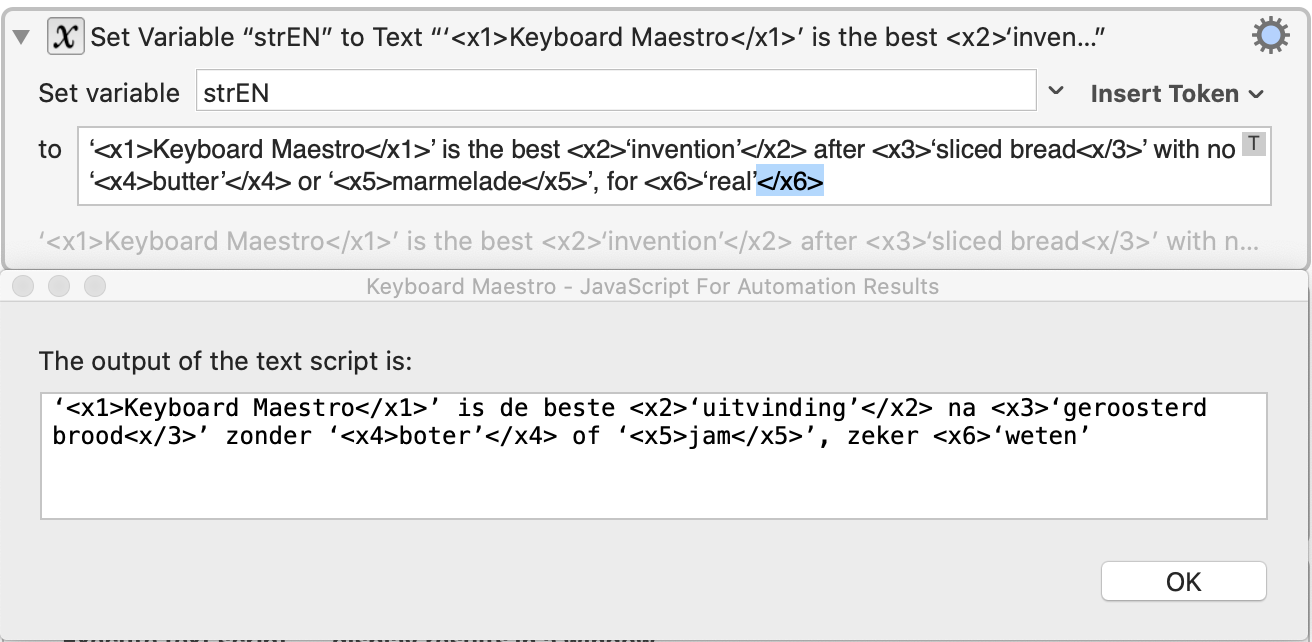
There's only one glitch in the variant with the Paired tags only: the last, closing tag is missing:
The other variant is correct.
Then there is this issue with the punctuation marks not being transferred to (synced with) the source. Instead of () the target shows ‘’:
And:
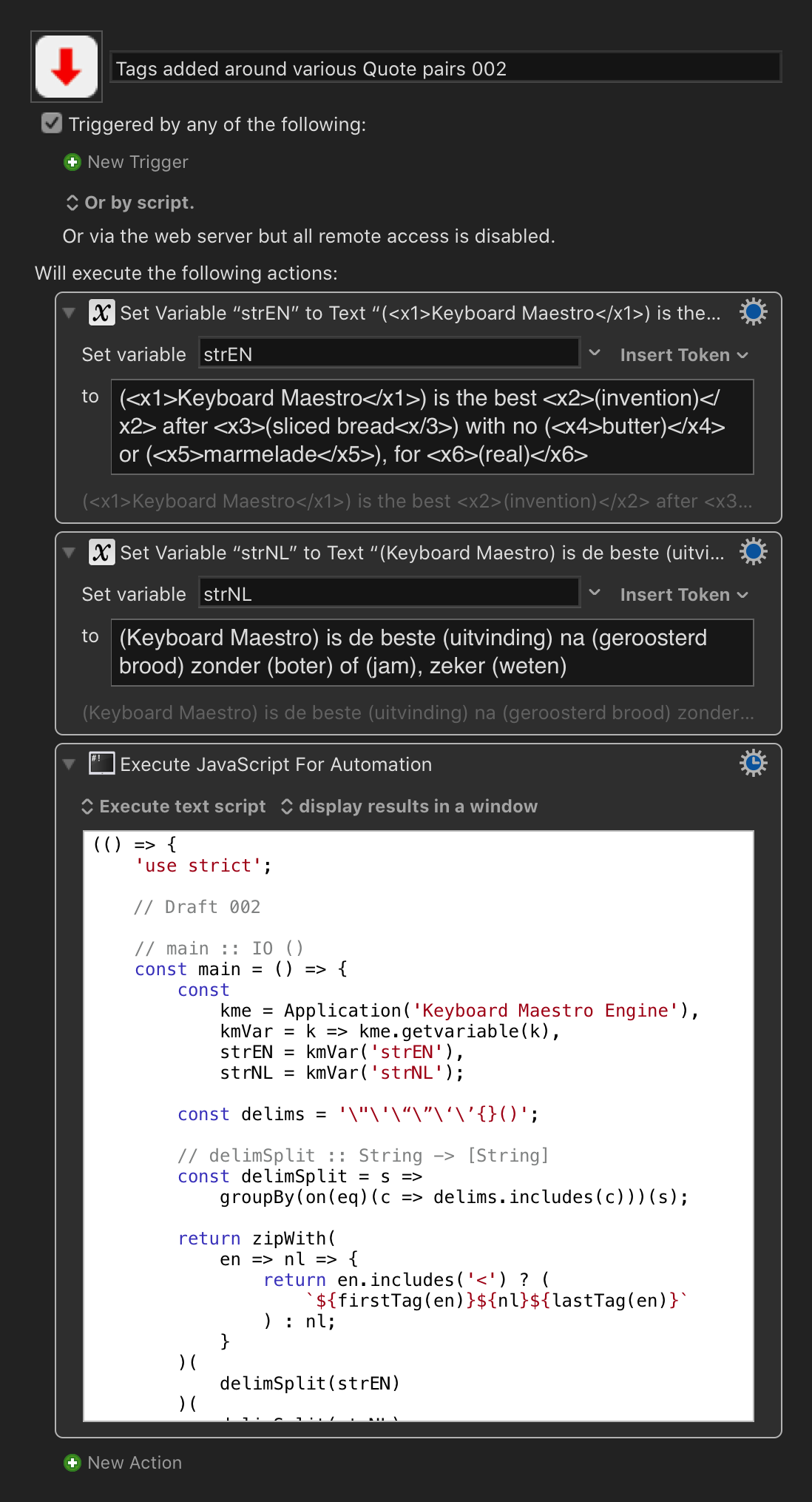
Next step, with this version:
Tags added around various Quote pairs 002.kmmacros (24.4 KB)
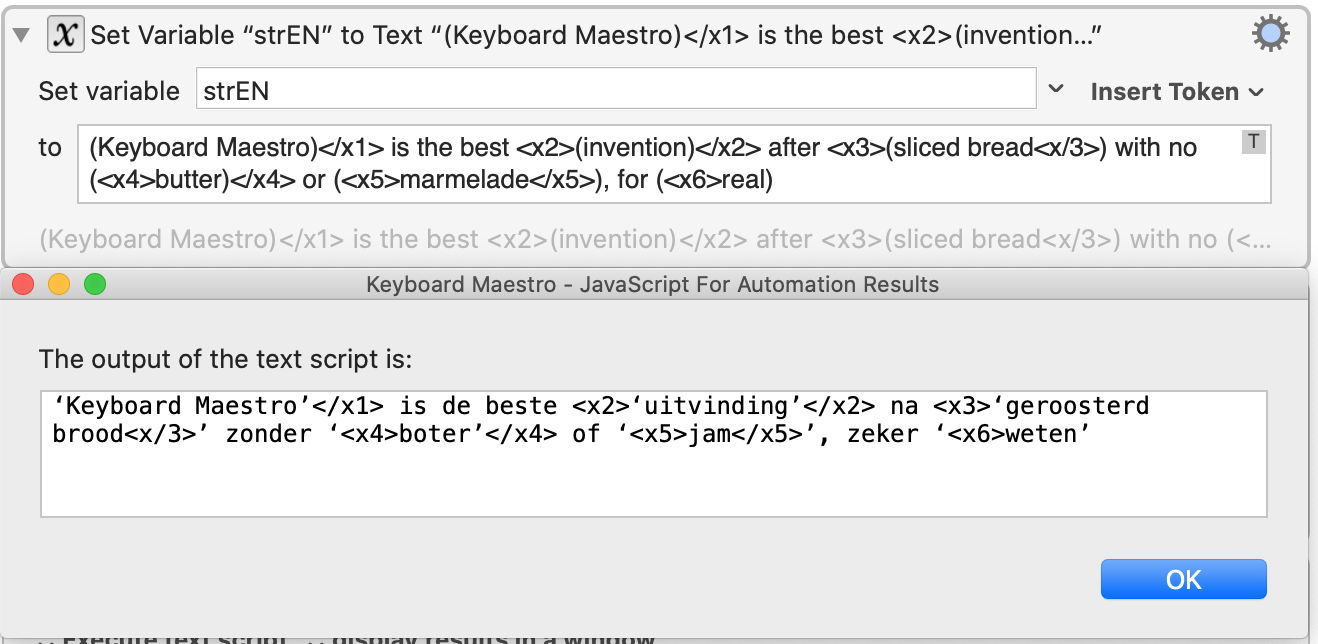
I am seeing
(<x1>Keyboard Maestro</x1>) is de beste <x2>(uitvinding)</x2> na <x3>(geroosterd brood<x/3>) zonder (<x4>boter)</x4> of (<x5>jam</x5>), zeker <x6>(weten)
Could you again mark any points of divergence (in the output) for us ?
i.e. show us the text triples of this kind that you are seeing:
(input EN, input NL) -> output NL
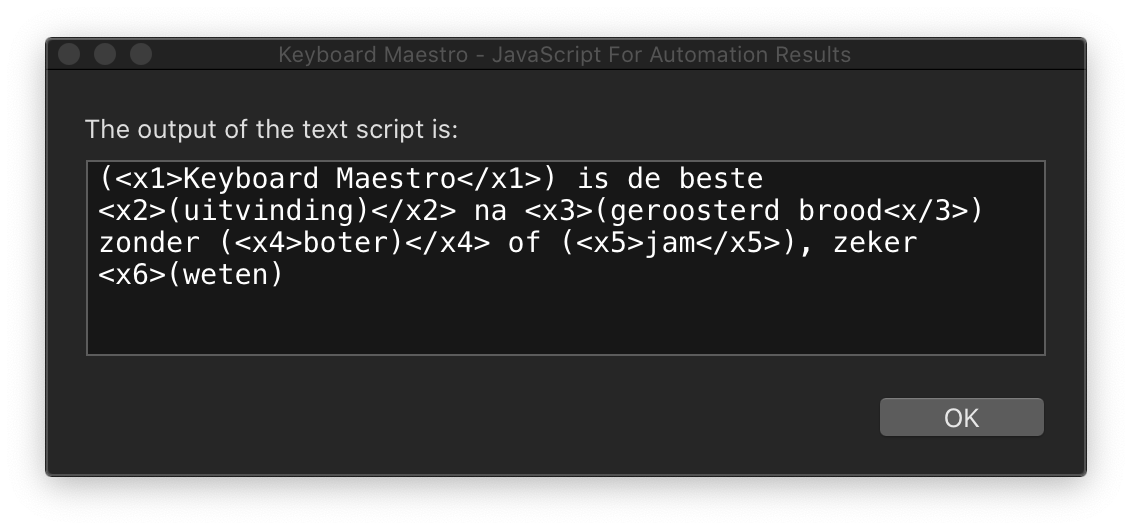
Indeed. And the last closing tag is missing in this variant:
It also looks like the targets always default to ‘’ instead of matching the () {} “” in the source:
And:
In that example the number of segments in the EN is one unit longer than the number of segments in the NL, so I'll need a variant of
zipWith
to allow for paired lists with differing lengths.
I think I may have a zipWithLong in my library somewhere. If not I'll write one – it may prove useful elsewhere.
Ah, you want the NL to adopt the bracketing delimiters from the EN source as well as the tags ?
OK. I'll take a look at that.
Next step:
zipWithLong to pick up an extra trailing segmentCould you again show us any divergences in the
(EN input, NL input) -> NL output
triples ?
Tags added around various Quote pairs 003.kmmacros (23.7 KB)
(() => {
'use strict';
// Draft 003
// main :: IO ()
const main = () => {
const
kme = Application('Keyboard Maestro Engine'),
kmVar = k => kme.getvariable(k),
strEN = kmVar('strEN'),
strNL = kmVar('strNL');
const delims = '\"\'\“\”\‘\’{}()';
// delimSplit :: String -> [String]
const delimSplit = s =>
groupBy(on(eq)(c => delims.includes(c)))(s);
return zipWithLong(
en => nl => en.includes('<') ? (
`${firstTag(en)}${nl}${lastTag(en)}`
) : delims.includes(nl) ? (
en
) : nl
)(
delimSplit(strEN)
)(
delimSplit(strNL)
).join('');
};
// firstTag :: String -> String
const firstTag = s =>
s.startsWith('<') ? (() => {
const i = [...s].findIndex(c => '>' === c);
return -1 !== i ? (
s.slice(0, 1 + i)
) : '';
})() : '';
// lastTag :: String -> String
const lastTag = s =>
s.endsWith('>') && s !== firstTag(s) ? (() => {
const
i = [...s].reverse().findIndex(
c => '<' === c
);
return -1 !== i ? (
s.slice(s.length - (1 + i))
) : '';
})() : ''
// --------------------- GENERIC ---------------------
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: 'Tuple',
'0': a,
'1': b,
length: 2
});
// showLog :: a -> IO ()
const showLog = (...args) =>
console.log(
args
.map(JSON.stringify)
.join(' -> ')
);
// groupBy :: (a -> a -> Bool) -> [a] -> [[a]]
const groupBy = fEq =>
// Typical usage: groupBy(on(eq)(f), xs)
xs => (ys => 0 < ys.length ? (() => {
const
tpl = ys.slice(1).reduce(
(gw, x) => {
const
gps = gw[0],
wkg = gw[1];
return fEq(wkg[0])(x) ? (
Tuple(gps)(wkg.concat([x]))
) : Tuple(gps.concat([wkg]))([x]);
},
Tuple([])([ys[0]])
),
v = tpl[0].concat([tpl[1]]);
return 'string' !== typeof xs ? (
v
) : v.map(x => x.join(''));
})() : [])(list(xs));
// on :: (b -> b -> c) -> (a -> b) -> a -> a -> c
const on = f =>
// e.g. groupBy(on(eq)(length))
g => a => b => f(g(a))(g(b));
// eq (==) :: Eq a => a -> a -> Bool
const eq = a =>
// True when a and b are equivalent in the terms
// defined below for their shared data type.
b => {
const t = typeof a;
return t !== typeof b ? (
false
) : 'object' !== t ? (
'function' !== t ? (
a === b
) : a.toString() === b.toString()
) : (() => {
const kvs = Object.entries(a);
return kvs.length !== Object.keys(b).length ? (
false
) : kvs.every(([k, v]) => eq(v)(b[k]));
})();
};
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// sj :: a -> String
function sj() {
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
const args = Array.from(arguments);
return JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0]) ? [
args[1], null, args[0]
] : [args[0], null, 2]
);
}
// zipWithLong :: (a -> a -> a) -> [a] -> [a] -> [a]
const zipWithLong = f => {
// A list with the length of the *longer* of
// xs and ys, defined by zipping with a
// custom function, rather than with the
// default tuple constructor.
// Any unpaired values, where list lengths differ,
// are simply appended.
const go = xs =>
ys => 0 < xs.length ? (
0 < ys.length ? (
[f(xs[0])(ys[0])].concat(
go(xs.slice(1))(ys.slice(1))
)
) : xs
) : ys
return go;
};
// MAIN --
return main();
})();
Thank you for all the patient examples of inputs outputs and divergences : -)
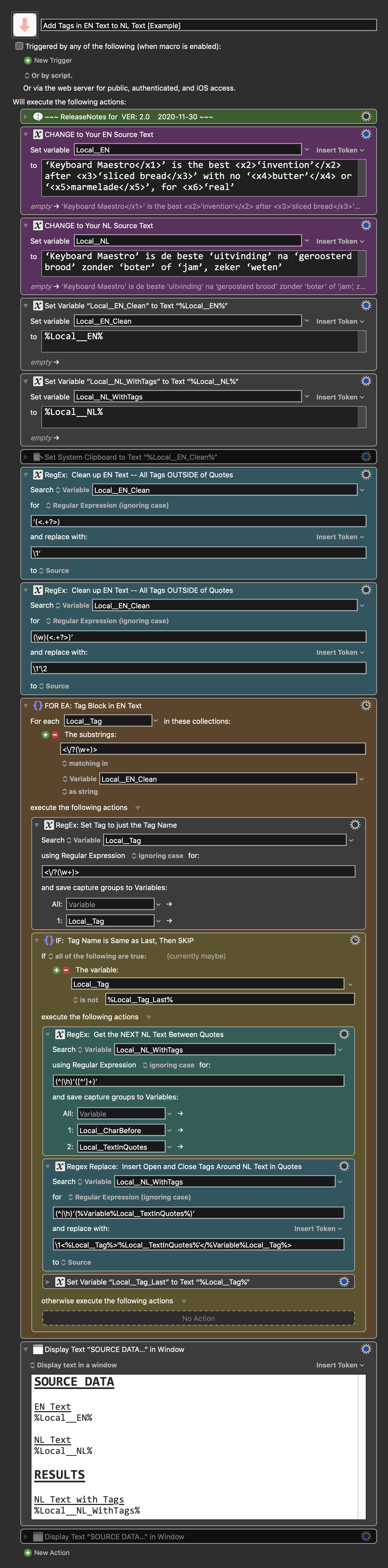
Now that I better understand both your data and workflow, I can provide a KM Macro that uses Regex Actions. IMO, this Macro is far simpler, and easier to understand than the complex JavaScript solution. Of course, you do have to have some understanding of RegEx. Let me know if you have any questions.
Below is just an example written in response to your request. You will need to use as an example and/or change to meet your workflow automation needs.
Please let us know if it meets your needs.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-~~~ VER: 2.0 2020-11-30 ~~~
Requires: KM 8.2.4+ macOS 10.11 (El Capitan)+
(Macro was written & tested using KM 9.0+ on macOS 10.14.5 (Mojave))
Add Tags in EN Text to NL Text [Example].kmmacros
Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.
Author.@JMichaelTX
PURPOSE:
HOW TO USE
MACRO SETUP
REQUIRES:
TAGS: @RegEx @Strings @Example
USER SETTINGS:
Good to see variant approaches – I would be particularly interested to see an approach (which I think should be possible, perhaps with JSON-patterned KM variable values) which bypasses both script and regular expressions.
Note though, that your Regex draft hasn't yet caught up with the full set of requirements and data samples that emerged in the thread.
In particular:
for example (see the most recent draft of the version using an Execute Javascript action):
EN input:
(<x1>Keyboard Maestro</x1>) is the best <x2>(invention)</x2> after <x3>(sliced bread<x/3>) with no (<x4>butter)</x4> or (<x5>marmelade</x5>), for <x6>(real)</x6>
NL input:
{Keyboard Maestro} is de beste {uitvinding} na {geroosterd brood} zonder {boter} of {jam}, zeker {weten}
Macro output (preserving all tag and quote boundaries, even when overlapping):
(<x1>Keyboard Maestro</x1>) is de beste <x2>(uitvinding)</x2> na <x3>(geroosterd brood<x/3>) zonder (<x4>boter)</x4> of (<x5>jam</x5>), zeker <x6>(weten)</x6>
(I'm sure the regular expression version can be quickly updated to fix those points, at little cost to 'simplicity', for those who are keeping up their training in debugging regular expressions : -)
If the OP is interested in my RegEx solution, AND is willing to post a complete set of requirement (real-world examples of source text, unedited, and real-world examples of desired output results, then I would be happy to revise my solution accordingly.
@ALYB, please let me know if you are interested.
Thank you for your kind offer @JMichaelTX, but the solution provided by @ComplexPoint is already perfect for my purposes.
No problem, I just wanted to provide a working example for those interested in using RegEx.
The RegEx is not that hard in this case, but it does take some creative thinking in how to use multiple RegExes in order to design a solution.
Nothing wrong with using JavaScript, if that is your preference. I use JavaScript all the time.