I'd like to request help for a task that goes beyond my knowledge of KM: I want to transfer all tags of the type {x1} ... {/x1} in source sentences to the corresponding target sentences (translations).
The tags should be inserted at the correct position, related to the surrounding quote characters (either left or right of the quote character).
Note that the tags don't need to be paired in all sentences.
Example:
Source 1:
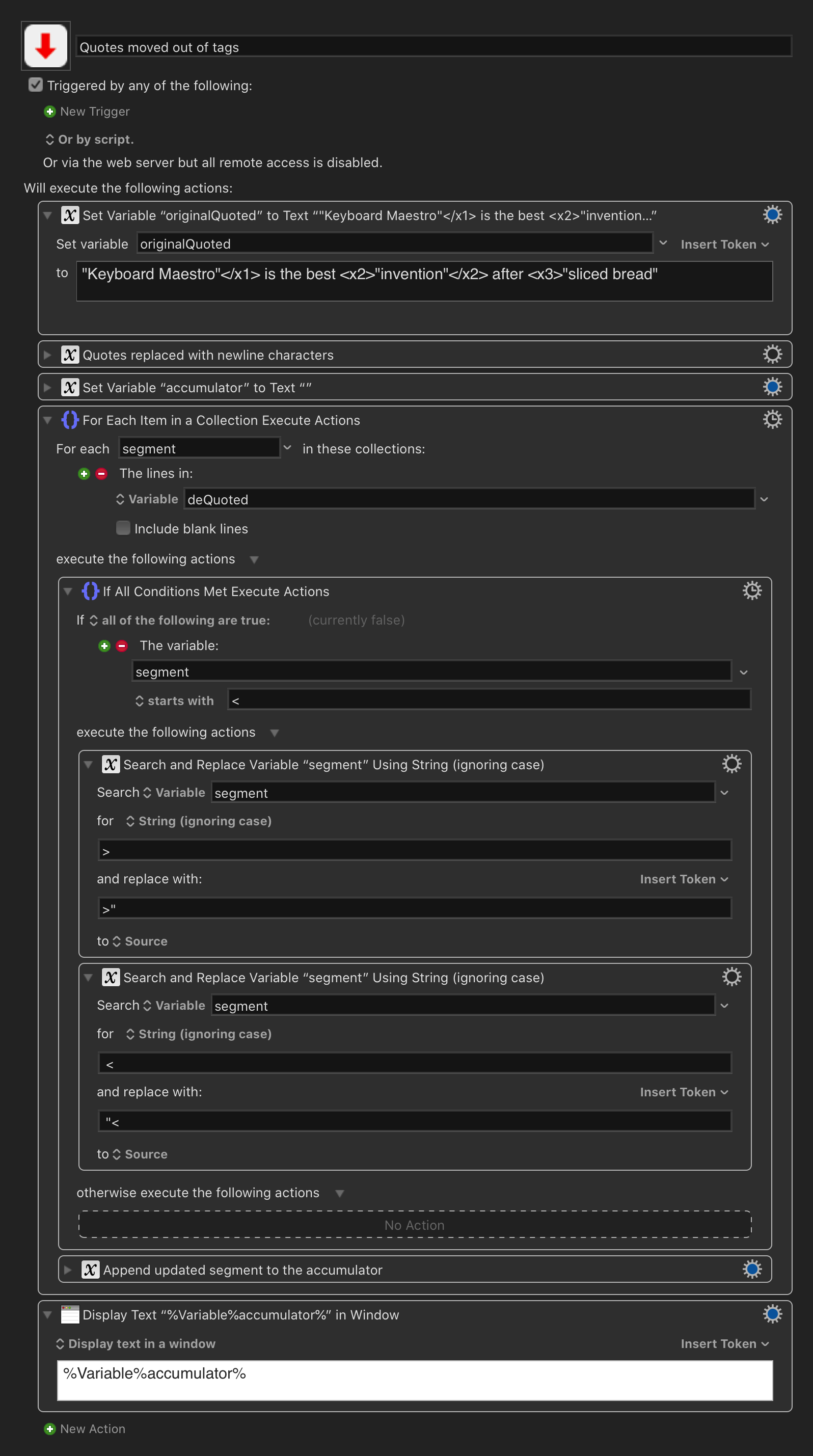
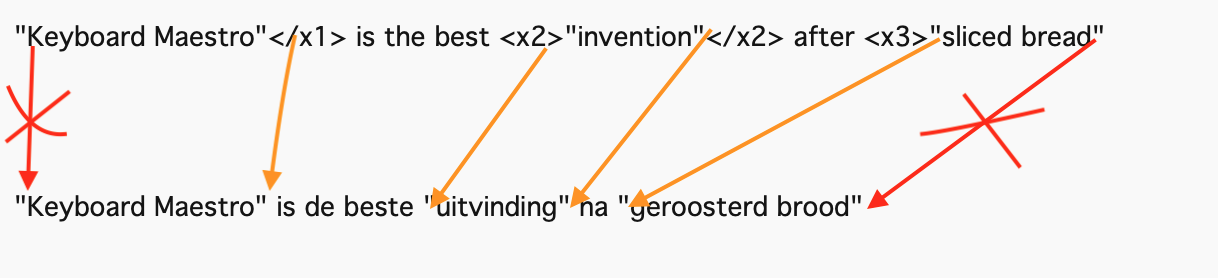
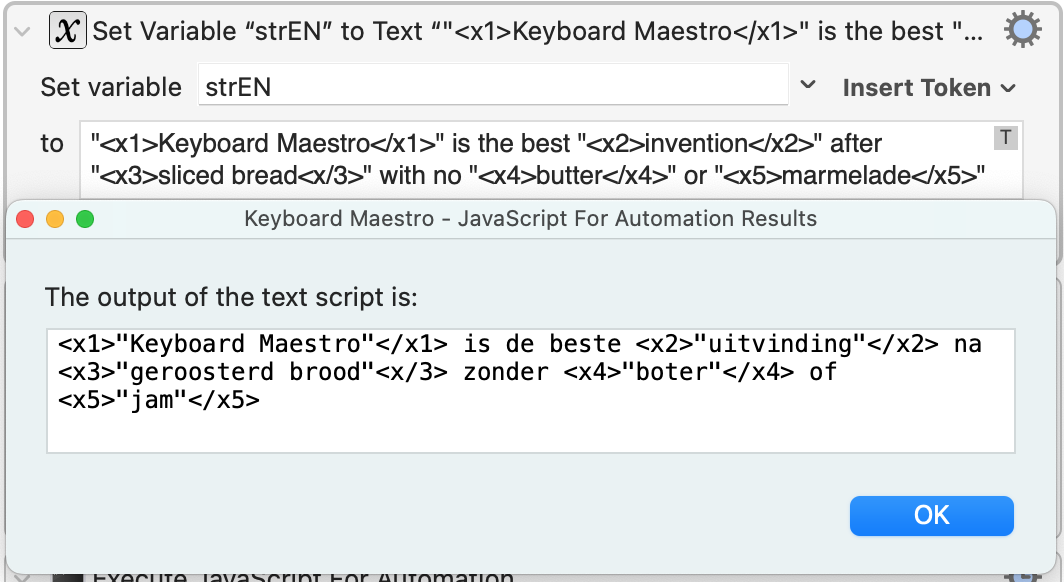
"Keyboard Maestro"{/x1} is the best {x2}"invention"{/x2} after {x3}"sliced bread"
Source 2:
"{x1}Keyboard Maestro{/x1}" is the best "{x2}invention{/x2}" after "{x3}sliced bread{/x3}"
Target 1:
"Keyboard Maestro"{/x1} is de beste {x2}"uitvinding"{/x2} na {x3}"geroosterd brood"
Target 2:
"{x1}Keyboard Maestro{/x1}" is de beste "{x2}uitvinding {/x2}" na "{x3}geroosterd brood{/x3}"
(I've used { and } to representative the less than and greater than characters.)
In source 1 the first opening and the last closing tags are missing, because they would be at the first/last position of the sentence (my editor hides them at these positions).
If that were the goal, then others might be keen to move straight to applying the problem to the need for Regular Expression practice, but I think my first experiment, in a KM context, might be some variant of a pattern like this:
So the quotes with the orange arrows have to be tagged (at the correct side of the quote, either at the left or at the right, like in the source), whereas the quotes with the red arrows (that aren't tagged in the source), should be omitted. And, to complicate things: the tag numbering has to match the numbering in the source.
So the NL input string already has quotation marks ?
(matching the positions of the quotes in the EN ?)
i.e. if we sketched out the inputs in terms of JS, it might look like this:
const
strEN = '"Keyboard Maestro"</x1> is the best <x2>"invention"</x2> after <x3>"sliced bread"',
strNL = '"Keyboard Maestro" is de beste "uitvinding" na "geroosterd brood"';
Yes, that's indeed correct. However, I realised that it's very likely that the authors of these texts won't be very consequent in their tagging (at least that's what I see every day). So variations of tag-quote spanning and even errors will be present too. The easiest approach will be to just mimic the variations and errors (a manual correction can take place later).
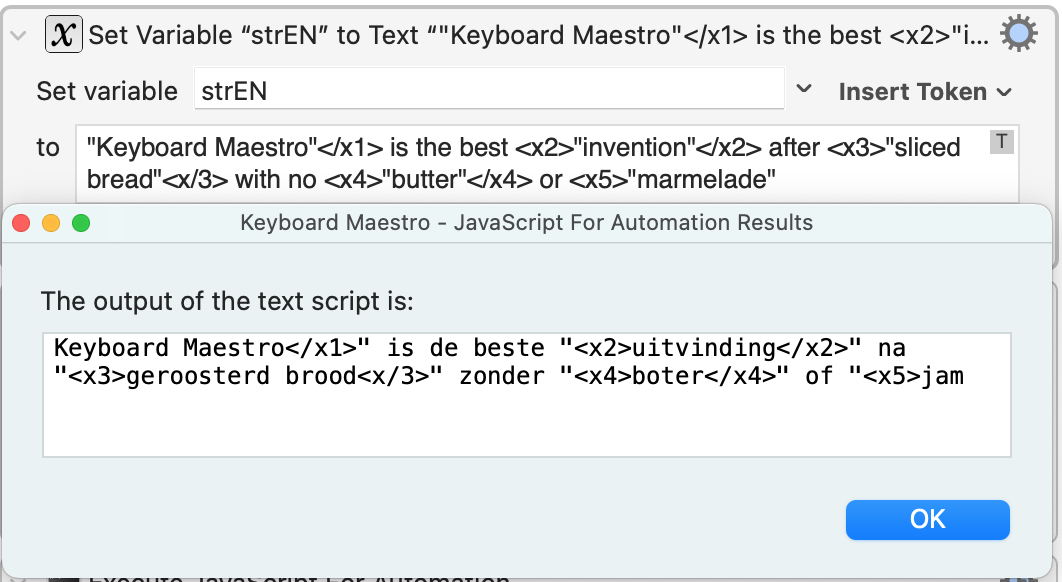
strEN = '"Keyboard Maestro"</x1> is the best <x2>"invention"</x2> after <x3>"sliced bread<x/3>" with no "<x4>butter"</x4> or <x5>"marmelade"',
strNL = '"Keyboard Maestro" is de beste "uitvinding" na "geroosterd brood" zonder "boter" of "jam"';
Very generous! This should cover all possible cases:
strEN = '‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for ‘<x6>real’',
strNL = '‘Keyboard Maestro’</x1> is de beste <x2>‘uitvinding’</x2> na <x3>‘geroosterd brood<x/3>’ zonder ‘<x4>boter’</x4> of ‘<x5>jam</x5>’, zeker ‘<x6>weten’';
(I've replaced the straight double quotes with the single curly ones, because I want to be able to adapt the JS to paired surrounding punctuation marks like (), {}, <> etc.)
strEN = '‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for ‘<x6>real’',
strNL = '‘Keyboard Maestro’</x1> is de beste <x2>‘uitvinding’</x2> na <x3>‘geroosterd brood<x/3>’ zonder ‘<x4>boter’</x4> of ‘<x5>jam</x5>’, zeker ‘<x6>weten’';
strEN = '‘<x1>Keyboard Maestro</x1>’ is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for <x6>‘real’</x6>',
strNL = '‘<x1>Keyboard Maestro</x1>’ is de beste <x2>‘uitvinding’</x2> na <x3>‘geroosterd brood<x/3>’ zonder ‘<x4>boter’</x4> of ‘<x5>jam</x5>’, zeker <x6>‘weten’</x6>';
Your assumption is correct. I just added the tags to the NL to indicate where they have to be placed.
strEN = '‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for ‘<x6>real’',
strNL = '‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’';
strEN = '‘<x1>Keyboard Maestro</x1>’ is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for <x6>‘real’</x6>',
strNL = '‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’';
In the meanwhile, you may find that you can fine-tune it by experimenting with adjustments to line 14 of the JS source in the Execute JavaScript action.
Here is a more vanilla version of the macro and that code, which leaves the double quotes in place.
This is a great use case for using RegEx.
However, that requires clear, consistent examples of source text, and the same for the output results text.
Unfortunately, your example is inconsistent, and it is not clear how you are converting (translating) all of the text. You are changing some text that is NOT between tags.
So, in order to have a meaningful solution I have had to edit your source and results text:
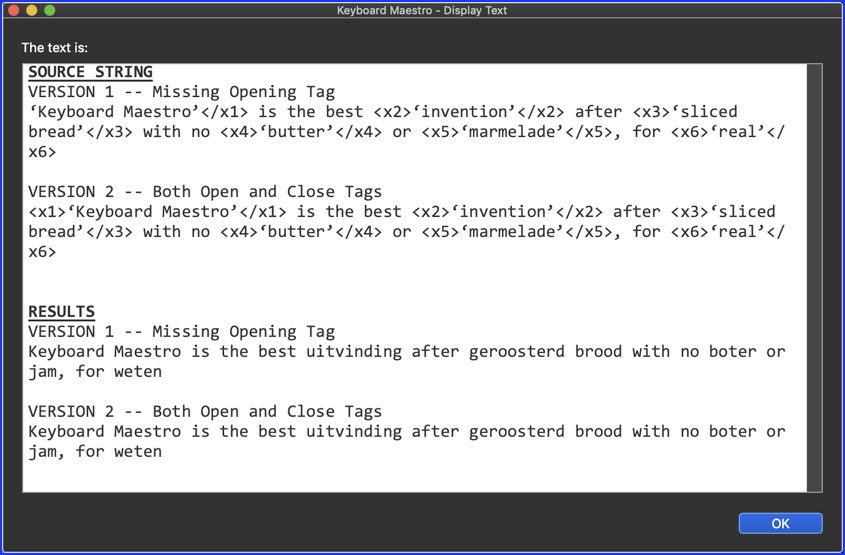
Source Text
VERSION 1 -- Missing Opening Tag
‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread’</x3> with no <x4>‘butter’</x4> or <x5>‘marmelade’</x5>, for <x6>‘real’</x6>
VERSION 2 -- Both Open and Close Tags
<x1>‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread’</x3> with no <x4>‘butter’</x4> or <x5>‘marmelade’</x5>, for <x6>‘real’</x6>
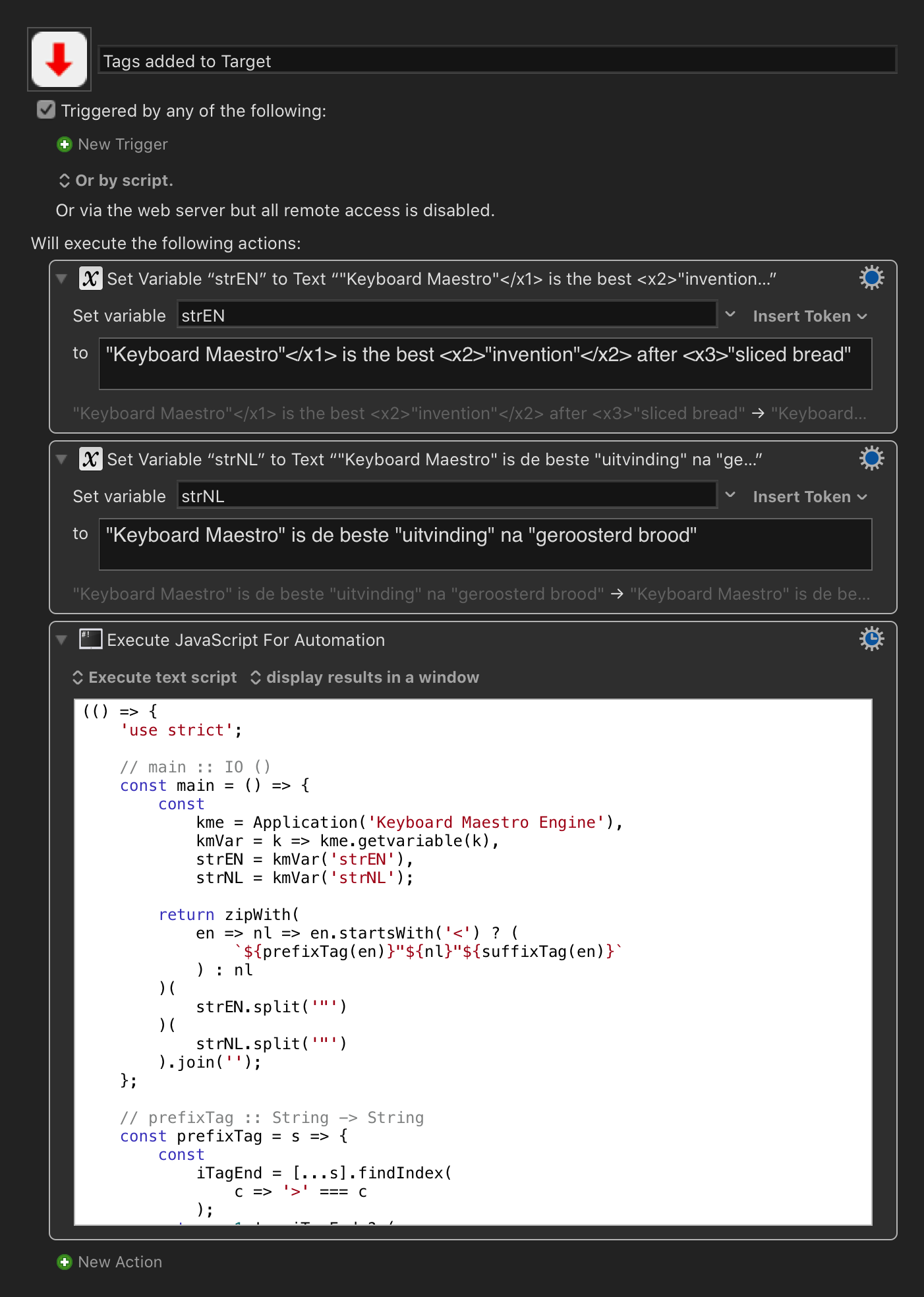
So here is a RegEx solution that replaces the Tag block, and any source text, with the same text based solely on the Tag Name:
x1
Keyboard Maestro
x2
uitvinding
x3
geroosterd brood
x4
boter
x5
jam
x6
weten
I suspect that the source and replacement text for a given Tag (like "x2") could vary with your input source text. If so, you will need to provide specific examples.
For now, the replacement text is based solely on the Tag Name.
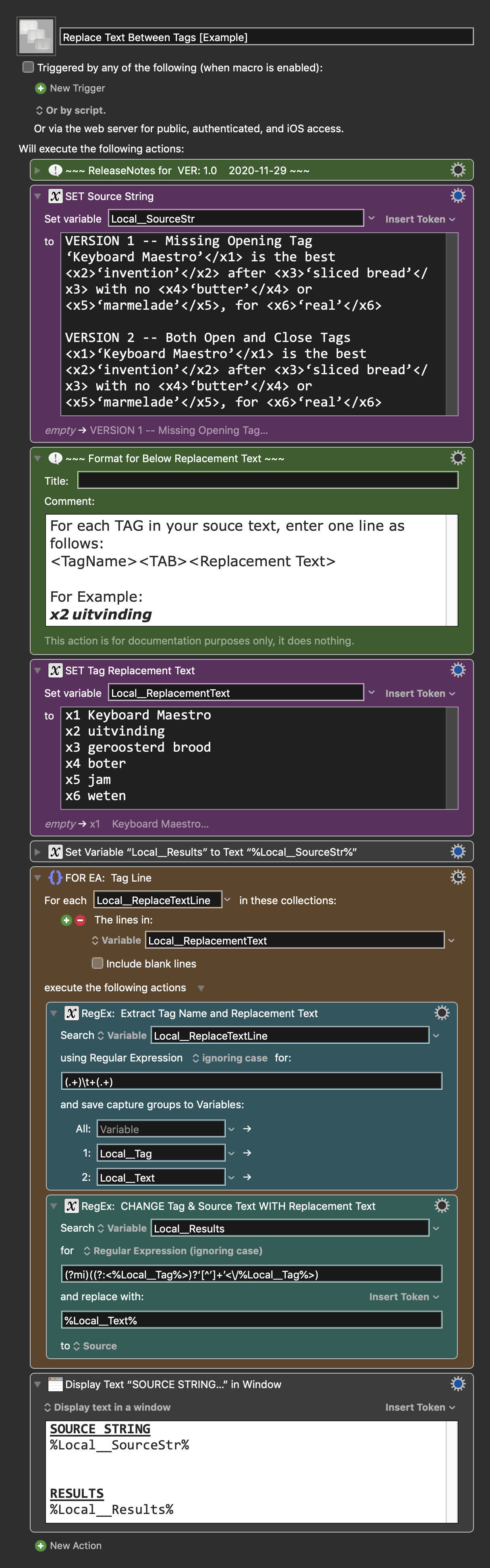
Tags (Open & Close) and Original Text Are Replaced by Text in "ReplacementText" KM Variable
Note that this replaces ANY text between the Tags with the same replacement text. This assumes that the same source text is always the same for a given Tag.
HOW TO USE
First, make sure you have followed instructions in the Macro Setup below.
REPLACE the text in the first two Set Variable Actions with your actual data
Trigger this macro.
MACRO SETUP
Carefully review the Release Notes and the Macro Actions
Make sure you understand what the Macro will do.
You are responsible for running the Macro, not me. ??
. Make These Changes to this Macro
Assign a Trigger to this macro.
Move this macro to a Macro Group that is only Active when you need this Macro.
ENABLE this Macro, and the Macro Group it is in.
.
REVIEW/CHANGE THE FOLLOWING MACRO ACTIONS:
(all shown in the magenta color)
SET Source String
The source text that you want to process
SET Tag Replacement Text
List of Tags and the corresponding replacement text
REQUIRES:
KM 9.0+ (may work in KM 8.2+ in some cases)
macOS 10.11.6 (El Capitan)+
TAGS: @RegEx@Strings@Example
USER SETTINGS:
Any Action in magenta color is designed to be changed by end-user
The examples were exactly as intended: I tried to add all irregularities that occur. Note that these aren't database strings or so that have to adhere to strict structural rules. They are e.g. MS Word strings where every tag stands for a colour change or e.g. a hyperlink. (Authors are often sloppy and they aren't consequent in placing quotes in or outside formatting.)
Besides that, the macro has to be generic. What it needs to do is transfer tags in exactly the same order from source to target, at exactly the same side of the quote as in the source. Using a list with words would make the macro inflexible.
I'm sorry to say that the second version doesn't solve the task either.
I understand that I've been not clear enough in defining what the macro needs to do. So please let me define the task better.
Task:
Transfer tags near quotes in exactly the same order from source to target, at exactly the same side of the quote as in the source. Only quotes should be used to determine the position of tags, no words should be used.
There are 2 different variants of the source sentence, one with only paired tags and one with paired tags and unpaired tags. Every variant has all possible combinations of the order of tags and quotes. The editor creates an intermediate target (which is a translation of the source) without any tags. The macro should insert all tags to the intermediate target to create the desired target (final translation).
Variant 1: Paired tags only
Source ‘<x1>Keyboard Maestro</x1>’ is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for <x6>‘real’</x6>
Intermediate target ‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’
Desired target ‘<x1>Keyboard Maestro</x1>’ is de beste <x2>‘uitvinding’</x2> na <x3>‘geroosterd brood<x/3>’ zonder ‘<x4>boter’</x4> of ‘<x5>jam</x5>’, zeker <x6>‘weten’</x6>
Variant 2: Paired tags and unpaired tags
Source ‘Keyboard Maestro’</x1> is the best <x2>‘invention’</x2> after <x3>‘sliced bread<x/3>’ with no ‘<x4>butter’</x4> or ‘<x5>marmelade</x5>’, for ‘<x6>real’
Intermediate target ‘Keyboard Maestro’ is de beste ‘uitvinding’ na ‘geroosterd brood’ zonder ‘boter’ of ‘jam’, zeker ‘weten’
Desired target ‘Keyboard Maestro’</x1> is de beste <x2>‘uitvinding’</x2> na <x3>‘geroosterd brood<x/3>’ zonder ‘<x4>boter’</x4> of ‘<x5>jam</x5>’, zeker ‘<x6>weten’