Peter, I'm sure you're right.
But I guess I'm being a bit hard-headed about this, so I'm off on the proverbial fools errand, just to prove you right.  It is interesting when I do some Google searches it turns up a lot of people trying to do this.
It is interesting when I do some Google searches it turns up a lot of people trying to do this.
Of course ComplexPoint has some great ideas and code, and I'll likely end up using his stuff. But for now . . .
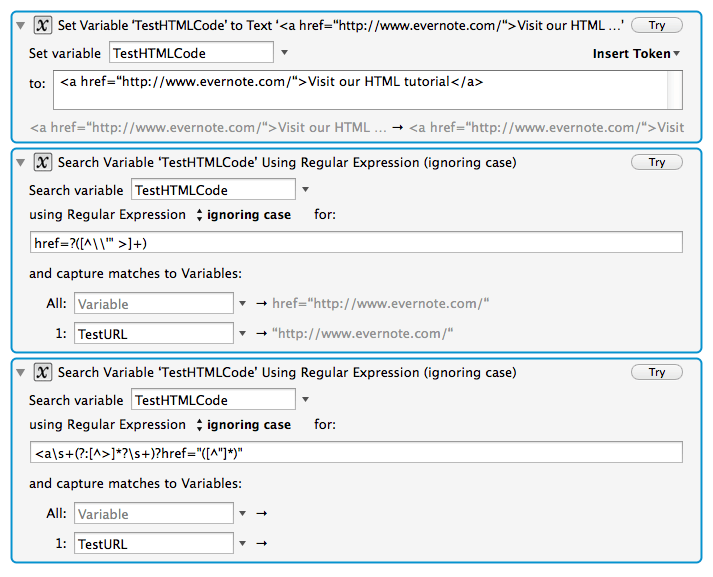
Here's what I'm thinking. All anchor tags must have at least a URL, right?
So, all I need to do is find the code segment that begins with "href" and take it from there.
So, given somewhere in the HTML code there is one of the following:
<a href="http://forum.keyboardmaestro.com/t/combining-rtf-in-clipboards/1556/7" class="title" style="color: rgb(34, 34, 34); [and perhaps more stuff before the ">"]
OR
the same as above without the quotes around the URL
<a href=http://forum.keyboardmaestro.com/t/combining-rtf-in-clipboards/1556/7 class="title" . . .
OR
Your worst case scenario:
<a alt="<>" href="http://www.stairways.com">
So in pseudo code:
<a [AnyText] href [AnyOf: Space = SingleQuote DoubleQuote] [theURL] [AnyOf: Space SingleQuote DoubleQuote] [AnyText] >
I think, but don't know how, one should be able to construct a RegEx with this logic:
FIND "<a" [AnyText] "href"
plus optionally [whitespace, =, whitespace, single quote, double quote]
That should put us at the beginning of the URL
Then match/capture:
any characters until it hits anyof [doubleQuote, SingleQuote, or space]
That marks the end of the URL
I can't think of any case where this would not work.
Now, if I can only find a RegEx guru to knows how to code my logic. 
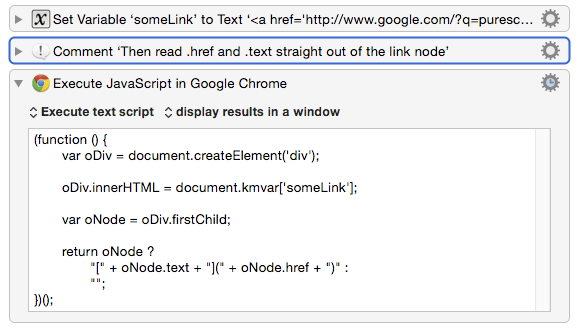
Here's one I found that seems to work well except for your case:
<\s*a\s+[^>]*href\s*=\s*[\"']?([^\"' >]+)[\"' >]