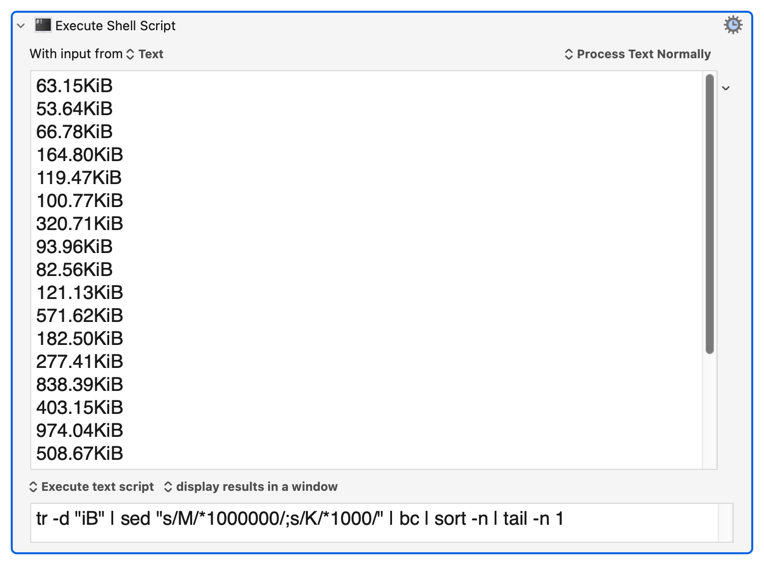
FWIW, a Haskell solution.
We could define a custom datatype (the order of the constructors matter for the ordering):
data FileSize = B | KiB | MiB | GiB | TiB deriving (Eq, Ord, Read, Show)
We could chain a series of functions (composition):
taking every line in the string,
lines
separating each into pairs of number strings and file sizes,
map (break isAlpha)
reading the first component as a Float and the second one as FileSize,
map (bimap (read :: String -> Float) (read :: String -> FileSize))
obtaining the maximum according to a custom comparator function, based on
- file size (second component)
- number (first component)
maximumBy (comparing snd `mappend` comparing fst)
transforming each component to its string representation,
bimap show show
appending (<>) the resulting pair to obtain a String.
uncurry (<>)
Finally, assembling the pieces (composing):
uncurry (<>)
. bimap show show
. maximumBy (comparing snd `mappend` comparing fst)
. map (bimap (read :: String -> Float) (read :: String -> FileSize))
. map (break isAlpha)
. lines
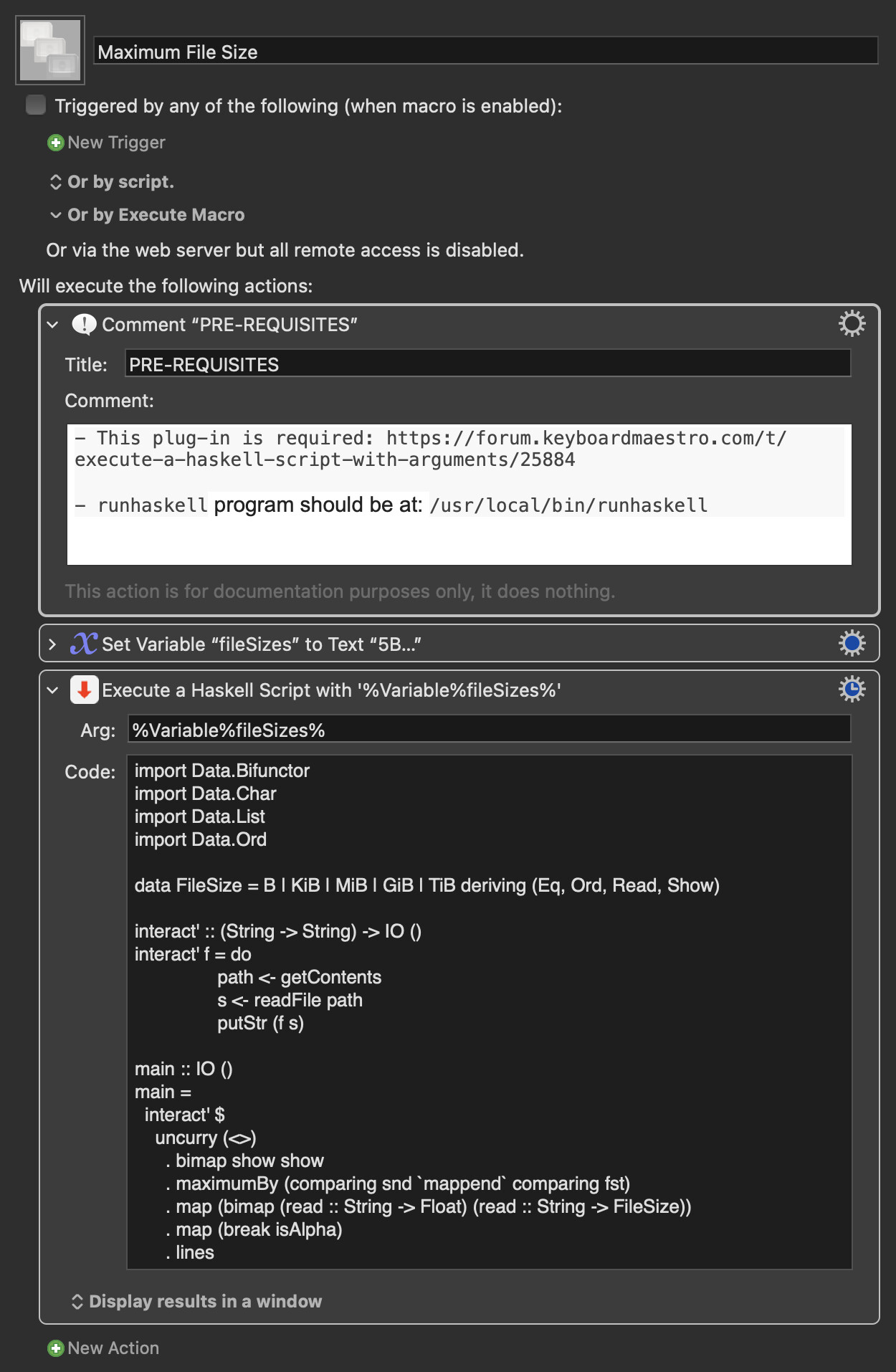
Maximum File Size.kmmacros (4.7 KB)
Expand disclosure triangle to view Haskell Source
import Data.Bifunctor
import Data.Char
import Data.List
import Data.Ord
data FileSize = B | KiB | MiB | GiB | TiB deriving (Eq, Ord, Read, Show)
interact' :: (String -> String) -> IO ()
interact' f = do
path <- getContents
s <- readFile path
putStr (f s)
main :: IO ()
main =
interact' $
uncurry (<>)
. bimap show show
. maximumBy (comparing snd `mappend` comparing fst)
. map (bimap (read :: String -> Float) (read :: String -> FileSize))
. map (break isAlpha)
. lines