There have been some posts on this (not many) over the years, but most were beyond my skill level, involving JXA scripting. Or they relied on another third-party app (BBEdit) to do the sorting. I was looking for an all KM solution, but it had to be fast and (relatively) easy to implement. The following may be of use if you have long lists and need them de-duped.
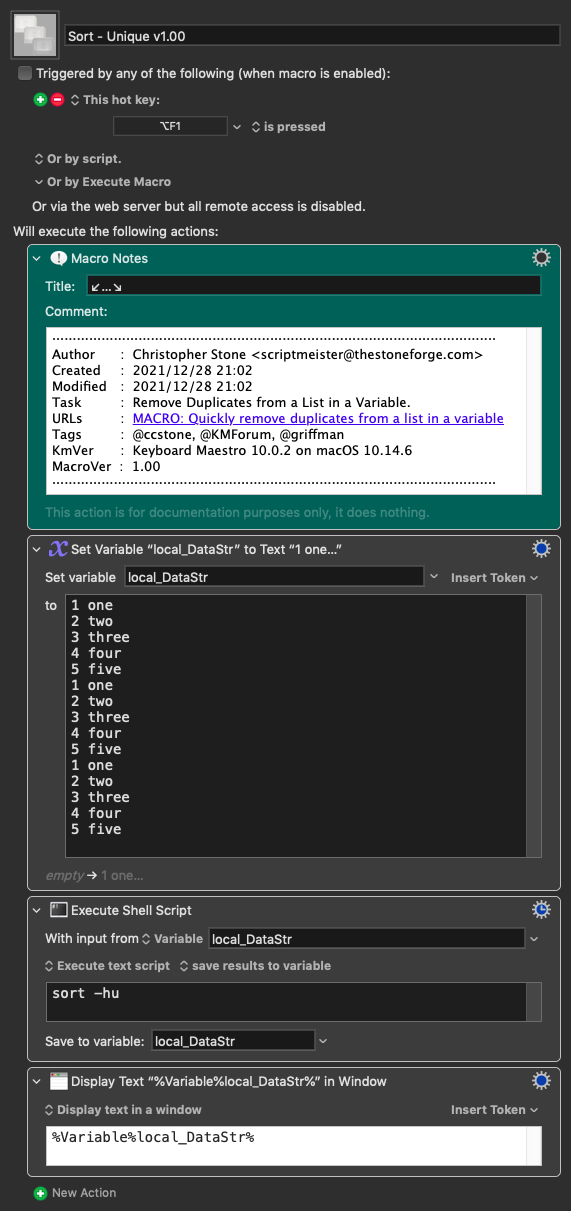
Every Mac user has a great de-duping tool built in on the Unix side of their OS: The combination of sort and uniq. The sort command does what it says, and uniq (with the -d flag) will spit out a list of matching records from whatever you send it. Put them together...
sort myfile.txt | uniq -d
And the output is a list of duplicates in the (unsorted) myfile.txt file. But even better, you can use it with standard input, so you can send it the contents of a variable. I used that to make a demo project showing how it can work, with both a short (20) and long (240+) list of words. Just enable/disable the short/long list to test either one:
Dedupe Demo.kmmacros (12.0 KB)
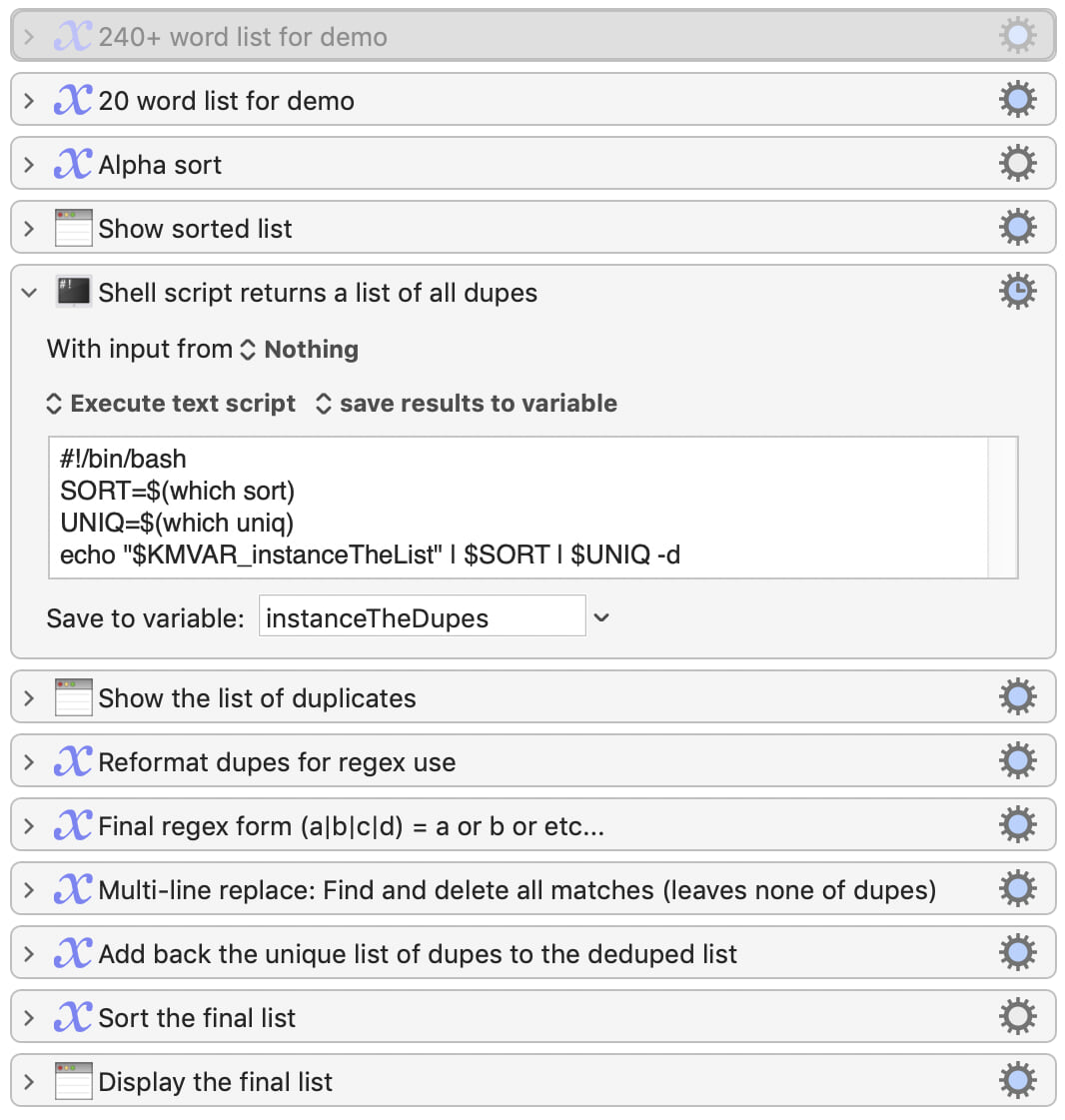
The list is sent through the above command, which returns the list of duplicates. I massage that list into a regular expression "or" format—(A|B|C|D) matches any row that are either A, B, C, or D—and then do a multi-row find/replace to remove all the dupes—not even leaving one in place. But because I have the list of dupes, I just add it back at the end, sort, and that's that.
It's quite speedy—fast enough for any lists I'll ever de-dupe; it took about a tenth of a second to do the big list. Hope others find this useful—I'm very happy with its performance; it's about six times faster than the old hodgepodge solution I'd come up with before.
A footnote on the shell script bit, which looks a bit odd with the two which lines. Although these commands are built into macOS, a user may have replaced them with another version on a different path, which would cause the script to fail. The alias variables prevent that from happening.
-rob.