I am now using the Drafts app, previously only on IOS and now Mac also to take notes, review documents (converted) and make annotations in those documents.
Basically, the documents are converted to Markdown format which means that I work in Markdown when I am making annotations in draft documents.
I have come to use markdown headers (#) to make annotations when I review documents in drafts, reason being that in Markdown format Headers are convenient as annotations because the red font is easy to see when I scroll down the documents.
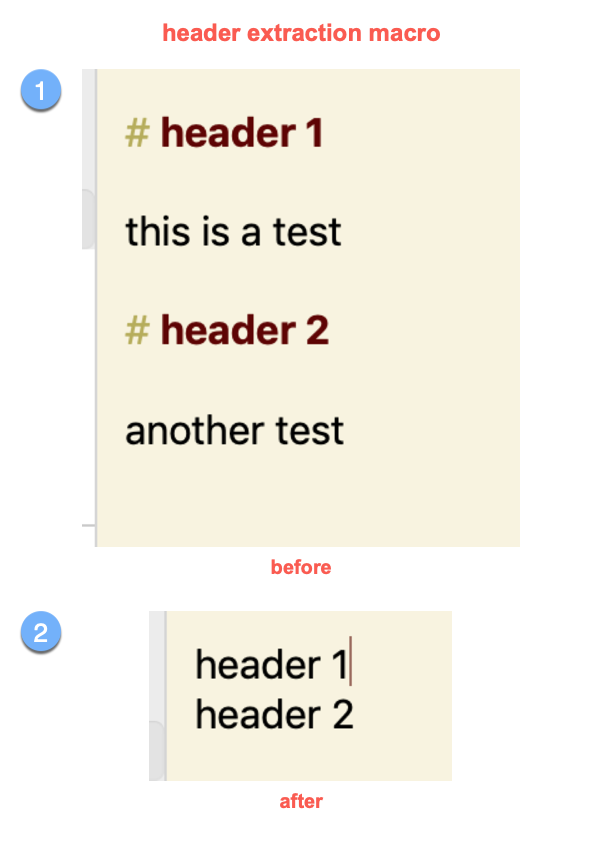
I would like to create a macro which would basically create an annotation summary, something you commonly find with PDF files.:
extract all the header lines from the Draft app note (called a draft) = the annotations summary
strip those headers of the hashtag # prefix
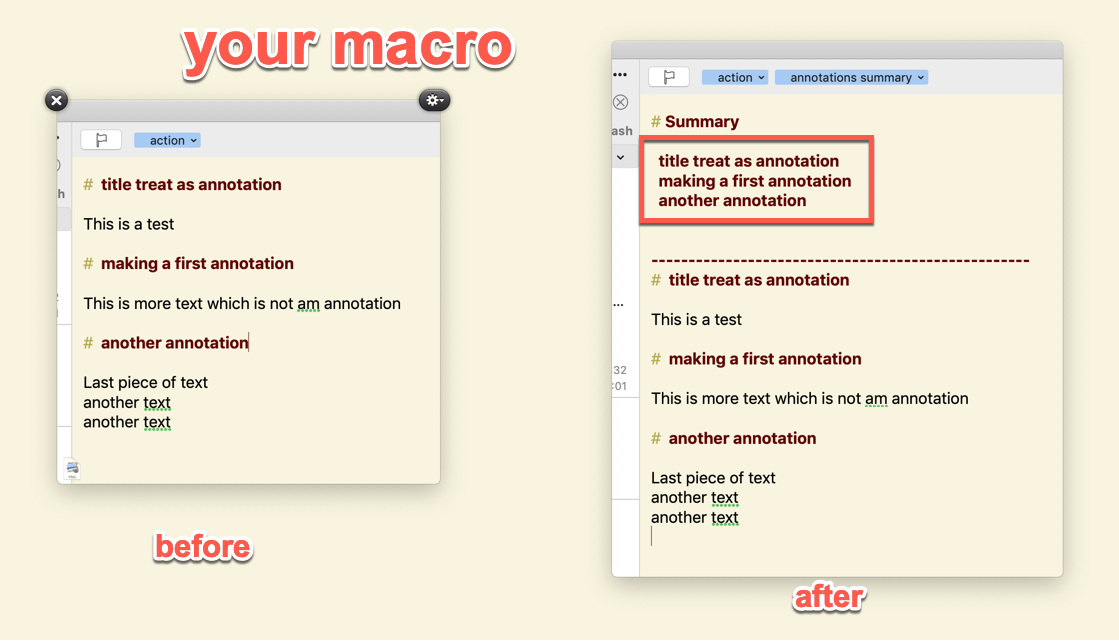
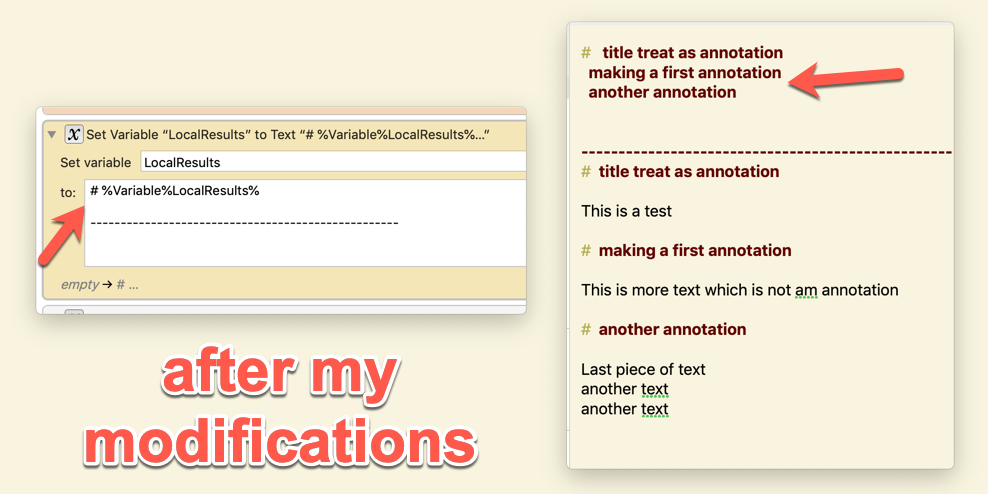
A before / after snapshot below will help you understand the end result.
Intuitively, I wonder if some kind of regex formula acting on the clipboard could do the job, but there are probably many options.
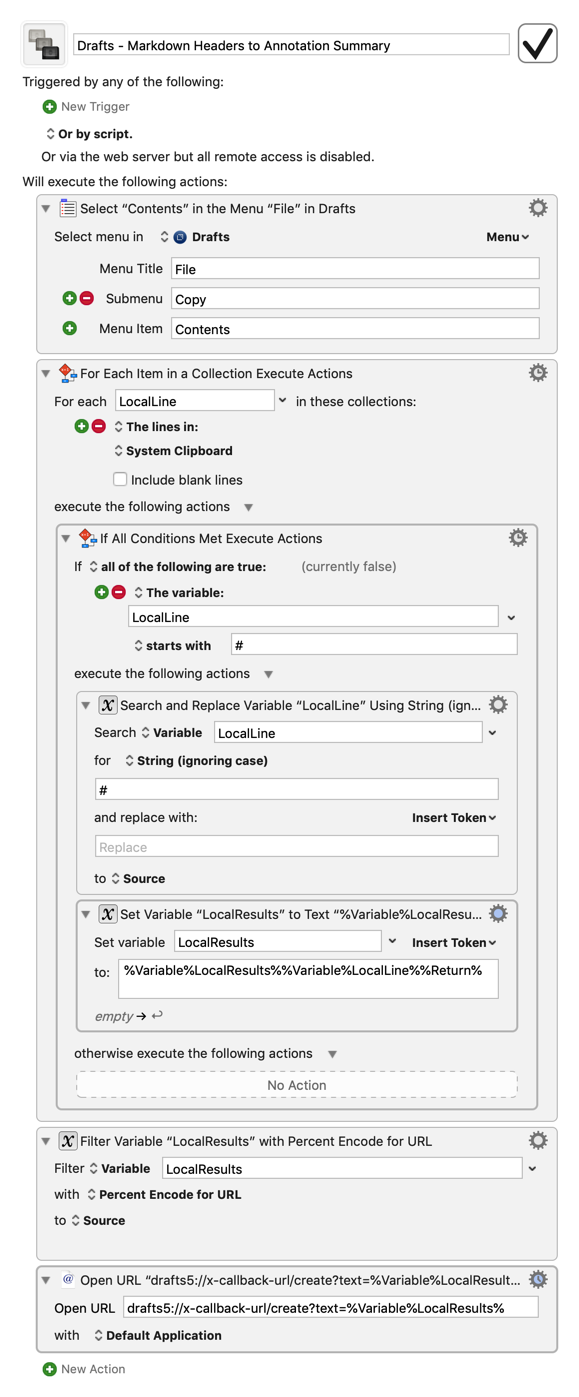
It isn't quite clear from your OP where exactly you want to create this annotation summary, but I assume from the title that you want to make a new note in Drafts with them. This certainly can be done with regex, but it can also be done without it:
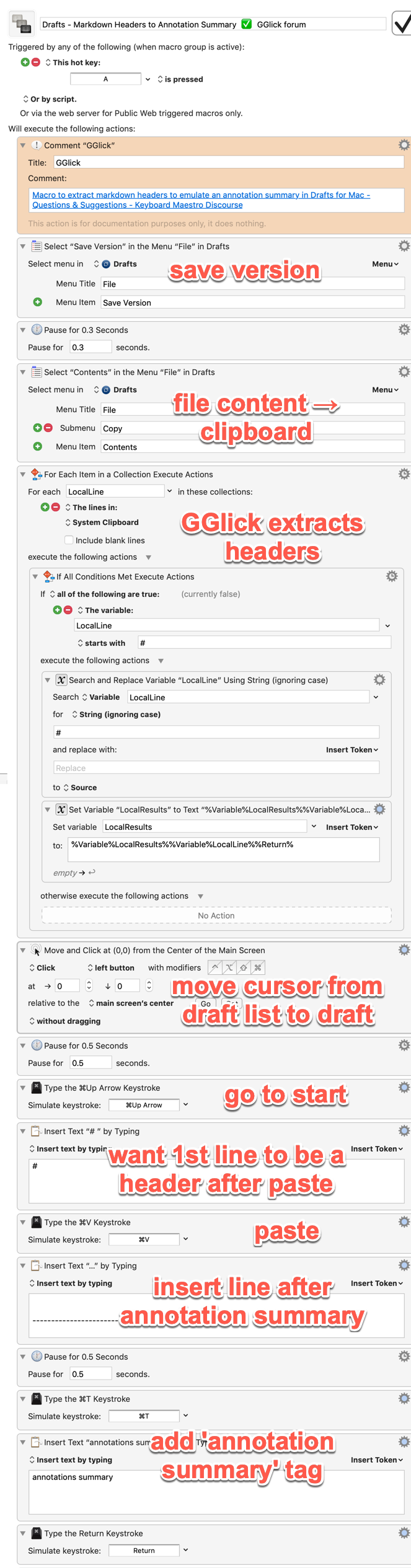
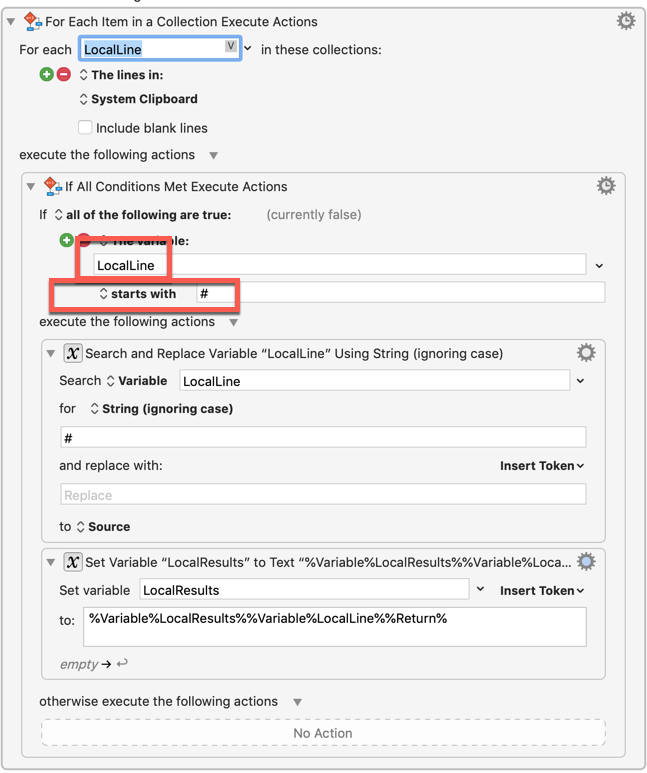
Drafts doesn't have scripting support, but it does have other useful menu options and a robust URL scheme, so instead of doing the standard Select All > Copy step at the start, I used Drafts' built-in menu option to copy the contents of the current draft to the clipboard, then I used the URL scheme at the end to create a new draft with the extracted headers. While there's no one right way to handle this task, and Select All > Copy in conjunction with regex, making a new note in Drafts with ⌘N, and pasting the results could also work, I thought this way would be a bit more automatic and reliable.
I am very happy that you know drafts !
I tried your macro, and found that it is too complicated to create a second annotation summary draft. The second draft would have to inherit the tags, otherwise it is not in the proper workspace, I end up with too many drafts etc, so I made a few self explanatory modifications.
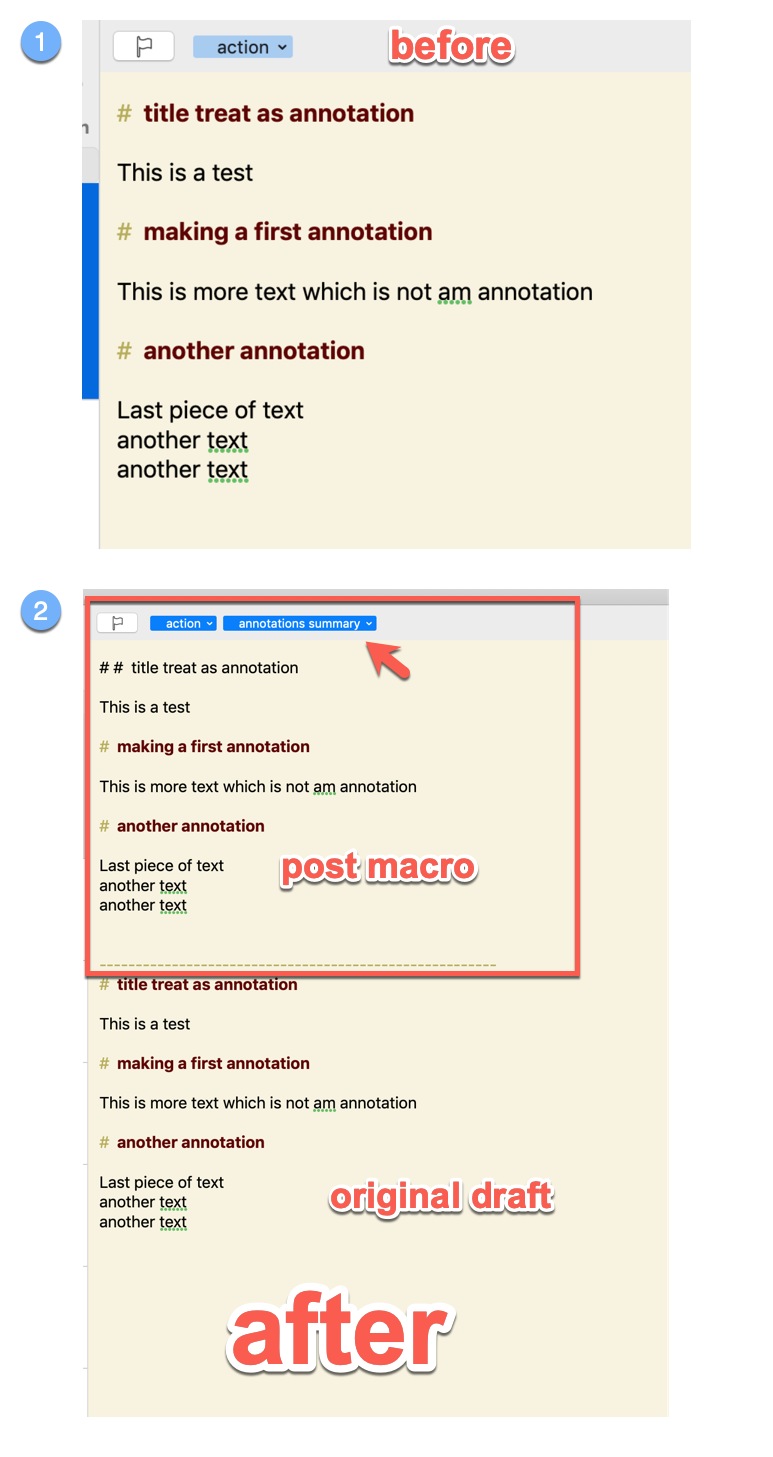
Basically I want to take the engine of your macro (the header extraction), and put it at the beginning of the draft, with a few cosmetic changes. Unfortunately, the macro does not work: it simply pastes the entire draft into the beginning of the first draft. It is as if the GGlick action (the core of the macro) does not function, which I am sure is due to my modifications. Probably a question of variable ?
For the rest, the neanderthalic part written by me, it consists of an initial version save (just in case), a bit of formatting, adding a tag, etc
thanks again very much
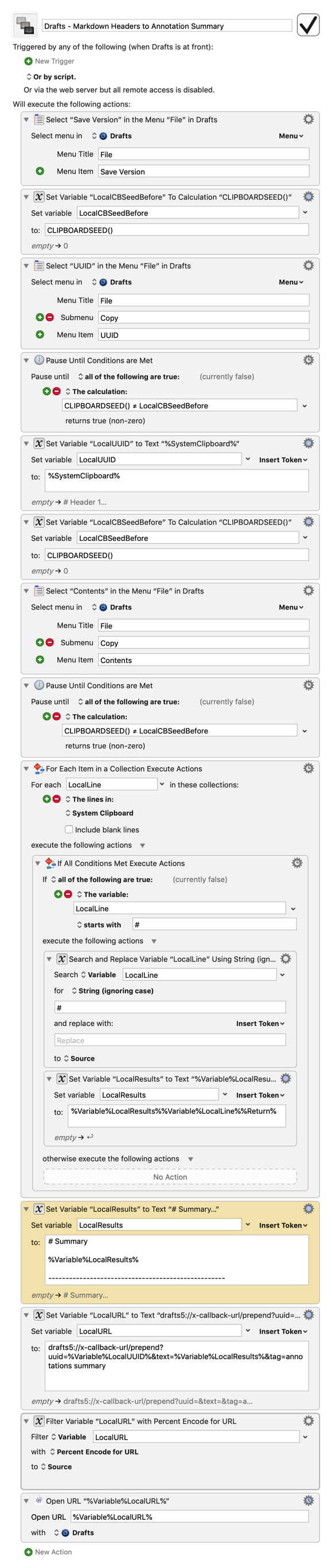
I'm afraid it's still not perfectly clear to me exactly how you want to format the summary, but that aside, I better understand your goal. What you want is to prepend this annotation summary to your macro with a new tag, both of which are things Drafts supports natively via its URL scheme, which in turn means they can be automated with KM in a much more reliable way than simulated mouse clicks and keystrokes.
your macro is fantastic ?
There is one funny behaviour: the pasted summary is bold red, but without being preceeded by a # which I did not know was possible.
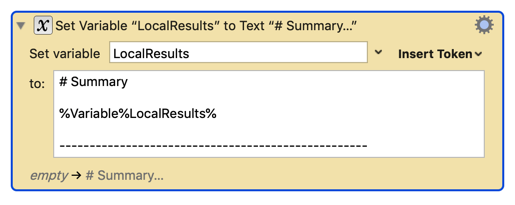
I slightly modified the macro so that the title (always a header) is at the top and therefore easy to see in the draft list, and removed the text annotations summary (tag is enough). Everything is fine except that I only want the first line treated as a header, and the rest of the summary normal format. Once again I see that strange header with no # display.
thanks again VERY much !
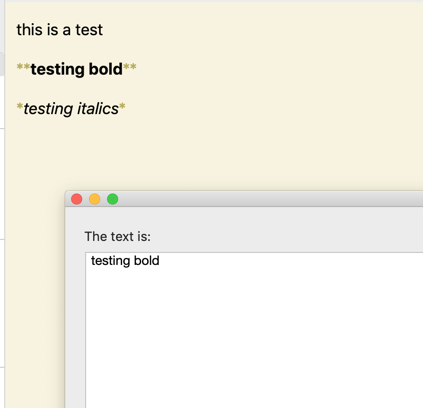
For my education and while we are on the topic, how would you edit this action to extract all bold or italics text.
Instead of 'starting with #' , one would extract all text contained between ** and ** or between * and *
I imagine that it is a question of changing LocalLine to something meaning text contained between (but could not find that option), and changing starts with but there again I could not find the right alternative.
thank you
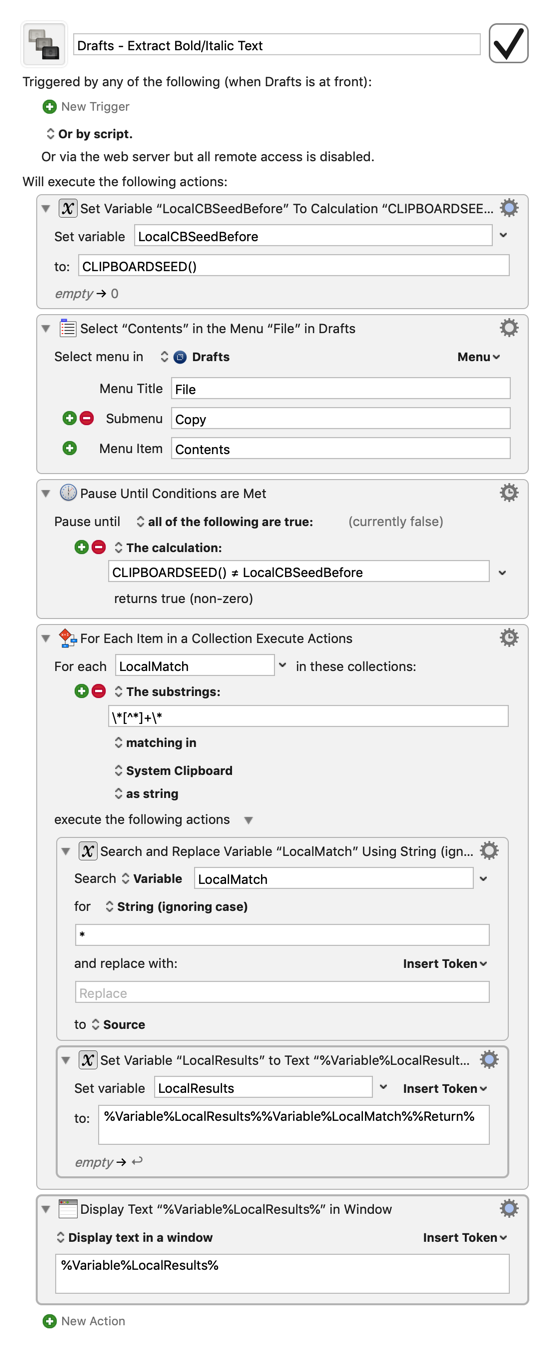
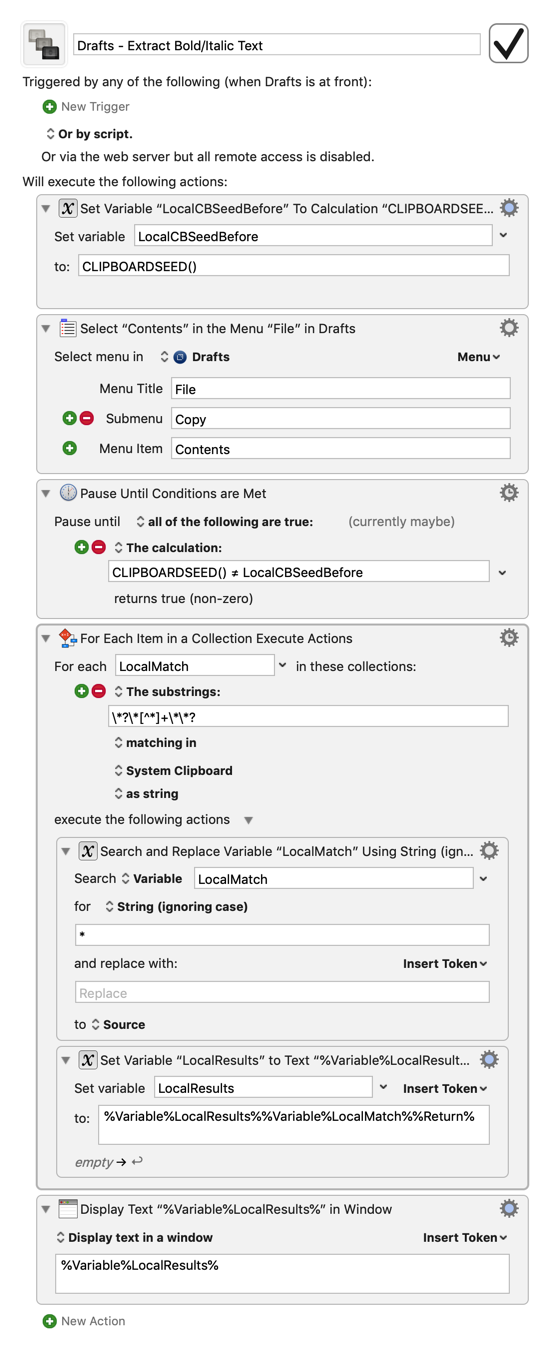
Extracting text between * is definitely a job for regex, so KM's lines collection isn't what we want in this case. Here's a quick and dirty macro based on the one for extracting summaries that looks for text between asterisks and saves it to a transient local KM variable:
thank you.
I don't understand why the regex in your macro
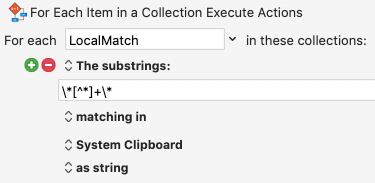
*[^]+*
extracts bold (**) and not italics () since the formula only contains one *.
What would be the regex for italics. In your Post, you include a screenshort which I assume was the regex for italics but the syntax is the same as bold
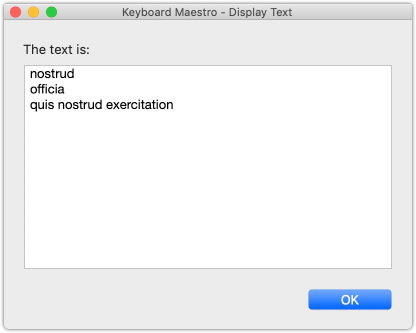
Hmm, I guess I didn't test it thoroughly enough. The macro I just uploaded worked fine extracting italic text with this sample data:
# Header 1
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis *nostrud* exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui *officia* deserunt mollit anim id est laborum.
## Header 2
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, *quis nostrud exercitation* ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis autke irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
### Header 3
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
But it did indeed fail when I mixed in bold text. Fortunately, this tweaked version: \*?\*[^*]+\*\*? seems to handle both fine so far: