I am using possibly the smallest OCR macro possible. It seems as if there should be nothing to debug. And it's not working.
Here's the macro:
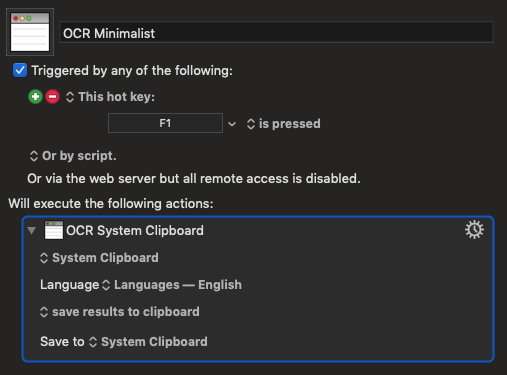
It simply takes whatever is on the clipboard, runs English OCR on it, and puts the result back in the clipboard.
I use it by pressing Ctrl+Cmd+Shift+4, dragging to select the area. That system hotkey puts the selected image in the clipboard. I then press F1 to run the macro, and I then paste the text from the clipboard where I want it, using Cmd+v.
In theory.
But when I select this image:

what I get as the OCR result is:
May be an image of text that says ‘no one is asking you to APOLOGIZE FOR BEING
TU RRC kara anal
Pe REO ee eee
TEA CHTCR AAEM TV Retna TnMstat sana stelt ea
It's like it gets the first line exactly right and the rest is nonsense, not even close. I can make it "work" by selecting one line of text at a time and pasting them together.
One thought that occurred to me, which I haven't tested, is that it is saving that first line, as it is completed, directly into the system clipboard before reading the rest of the clipboard for OCR processing, thereby messing up the source image. I would hope that was impossible, but ...
Any suggestions?
