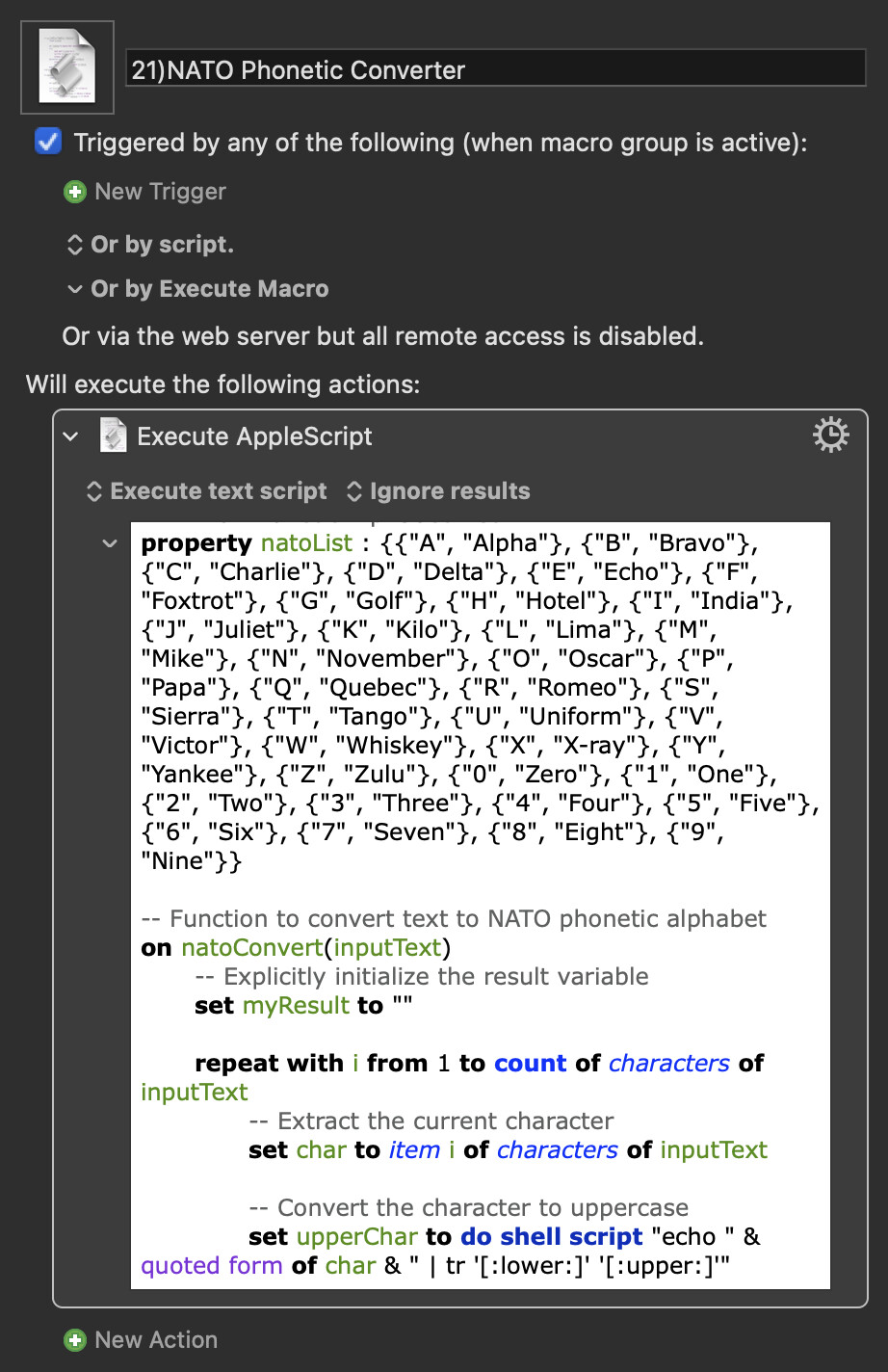
NATO Phonetic Converter Macro (ChatGPT made AppleScript) (v11.0.3)
I see @tiffle already covered this topic 4.5 years ago using JavaScript: Replace Clipboard with its NATO Phonetic Representation Macro (v9.0.5)
This version is in AppleScript and the input and output are handled differently by presenting a dialog to input the words to convert and outputting them on screen. It shares the action of copying the result to the clipboard as @tiffle's version does. Not world shattering differences.
The reason I'm posting here it is to say that this macro is nothing more than a single AppleScript AND ChatGPT wrote it from beginning to the end.
What I have found in the few AppleScripts I've used ChatGPT to write is that it has usually taken a minimum of six iterations to get it right. It's proving a useful tool for me to get somethings done that would otherwise take a lot more time and effort.
If you use this macro, please note all the usual cautions. This has not been tested much at all so I can not vouch for its reliability.
21)NATO Phonetic Converter.kmmacros (4.3 KB)