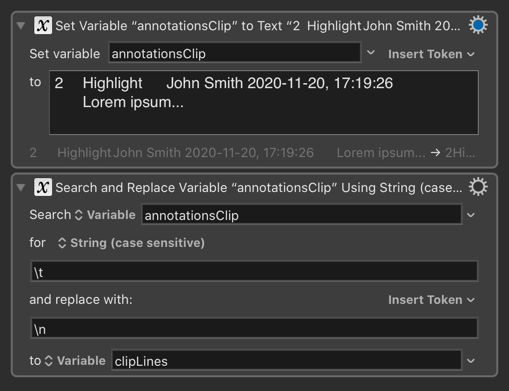
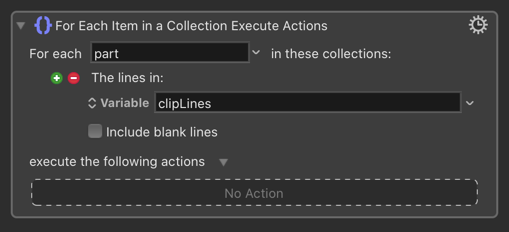
A problem with PDF annotations is that each annotation is proceeded by a prefix which makes for very tedious reading, so I want to just delete all prefixes in a RTF file text.
Well, I’m not exactly sure what it is you’re trying to match with your complex regex but if it’s the stuff up to but not including “Lorem ipsum” this will do the job:
(\d.+?:\d\d )
So the match for the entire annotation would be:
^(\d.+?:\d\d )(.*)$
I think. (Can’t test it properly as regex101.com is down!) The second capture group is the contents of the annotation, the first is the prefix.
thank you very much.
I really like your clean and simple solution. Aesthetically beautiful. regex101.com is down so I tested it with BBedit's regex playground
I identified 3 problems 2 of which I don't know how to solve,:
1- d )* → d)* - took out the space before ).
2- the regex does not highlight the seconds (:30 at the end)
3- there is a tab after the seconds which I also would like to highlight/delete
thanks again very much @tiffle. I have been working on this for 2 days !
In the examples you originally provided you didn’t say there was a tab between the seconds and Lorem ipsum... so I assumed it was a space which is why it doesn’t work.
So, as it’s a tab you can use this:
^(\d.+?:\d\d\t)(.*)$
or
^(\d.+?:\d\d\s)(.*)$
The first matches a tab specifically while the second matches any white space character (space, tab, ...)
My tip for regex here is this: there’s no need to match every single bit of the text provided you can uniquely match the beginning pattern and the end pattern; everything in between can be “soaked” up by .+?
One last question and I shall leave you in peace.
Just for my education and because I like your short and sweet (and smart) approach to regex, could one even create a regex which deletes all text before the 45th character on each line, a “line being defined” as a string of text ending with a line feed ?
thanks again very much
Replace the first capture group with nothing; the second capture group contains the remainder of the line. Is that what you meant? BTW - the first capture group matches the first 44 characters of the line. If you wanted 45, the change the 44 to 45.
For efficient use of human time, regex rarely score very well.
Before diving straight back into the regex whirlpool, it might be worth a quick look at alternatives like Keyboard Maestro Substring actions, which have a range option:
First, I would like to encourage you to keep using and learning Regular Expressions (RegEx).
IMO, it is one of the most powerful and useful languages, and can be used just about everywhere.
Now, to your request.
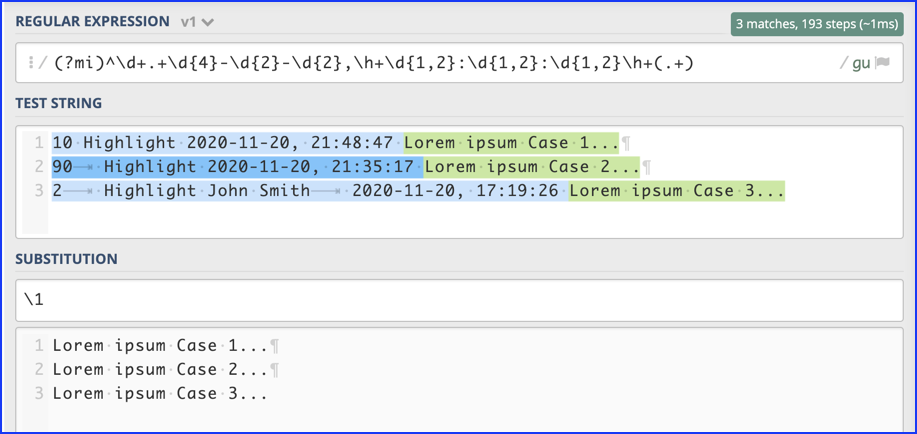
Actually, you were pretty close with: ^(?\d+)\s(?Highlight)\s\s(?\d{4}-\d+-\d+),\s(?\d+:\d+:\d+)\s(?.+)$
My solution is: (?mi)^\d+.+\d{4}-\d{2}-\d{2},\h+\d{1,2}:\d{1,2}:\d{1,2}\h+(.+)