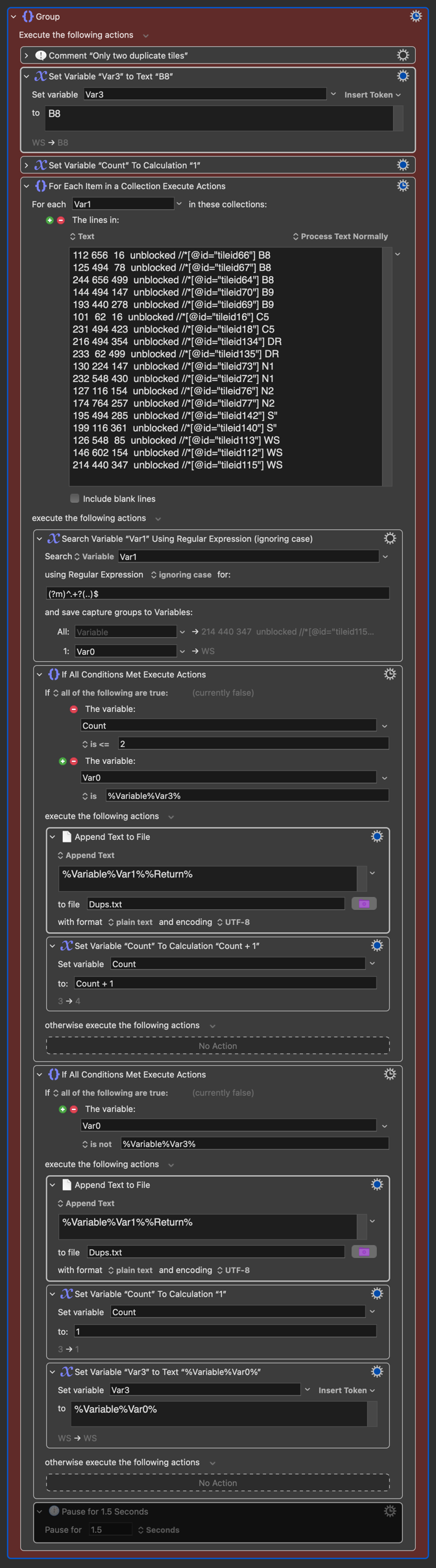
The goal is to iterate thru lines of text and compare the last two characters. If they match, output just the first two matching lines to a file. In my example the third line ending in B8 is ignored as desired but the last three lines are output instead of two lines. lines of text will always be sorted by the last two characters.
I prefer to use just KM actions to accomplish this goal.
Yes, these questions are always best asked by showing an (input, output) pair.
Iterating is certainly a possible solution, but the goal appears to be a derived list which includes only the first two lines in each group (where grouping is defined by sharing the last two characters).
(Note, incidentally that there may be a subtlety in your data source – it comes from Windows, or a Microsoft application, perhaps ? – in which the lines are delimited not by a single standard macOS/Unix "\n" linefeed, but by a two byte 0d 0a (CR LF) pair)
The components of your derived output list seem to be:
An input string delimited by CR LF pairs
a grouping of the delimited lines by the last two (non-delimiting) characters
taking only the first two lines of each such group
a concatenation of the pruned groups (lists of lists) down to a single flat list
a concatenation of that flat list to a single string (LF delimited for macOS ? CR LF for compatibility with some other context ?
all of those ingredients (splitting, grouping, taking a subset, flattening, forming a delimited string from a list) could be found, in one way or another, in KM action blocks or in a scripting language.
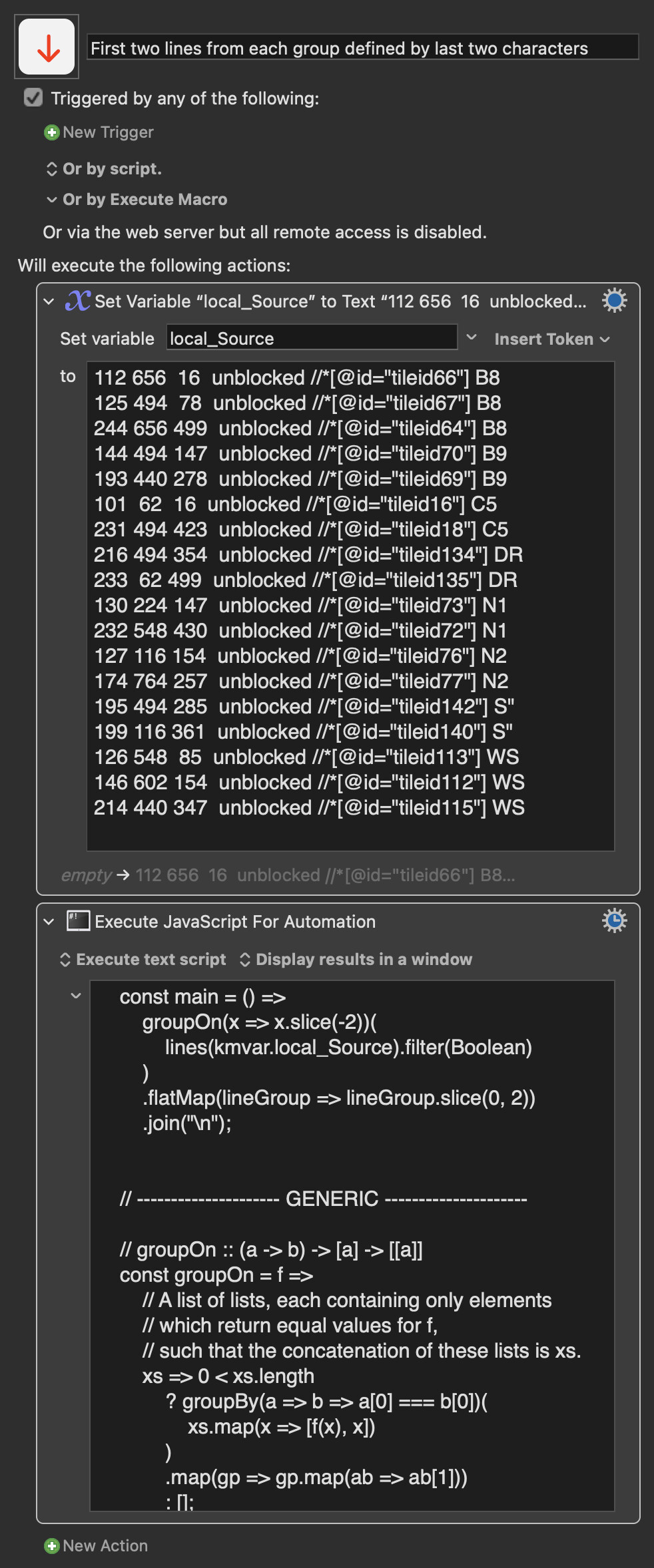
I happen, in this context, to reach first for Keyboard Maestro Execute JavaScript for Automation actions, so, perhaps, assuming Keyboard Maestro version 11, and assuming an output string delimited only by LF, one approach might look something like:
const main = () =>
groupOn(x => x.slice(-2))(
lines(kmvar.local_Source).filter(Boolean)
)
.flatMap(lineGroup => lineGroup.slice(0, 2))
.join("\n");
// --------------------- GENERIC ---------------------
// groupOn :: (a -> b) -> [a] -> [[a]]
const groupOn = f =>
// A list of lists, each containing only elements
// which return equal values for f,
// such that the concatenation of these lists is xs.
xs => 0 < xs.length
? groupBy(a => b => a[0] === b[0])(
xs.map(x => [f(x), x])
)
.map(gp => gp.map(ab => ab[1]))
: [];
// groupBy :: (a -> a -> Bool) -> [a] -> [[a]]
const groupBy = eqOp =>
// A list of lists, each containing only elements
// equal under the given equality operator, such
// that the concatenation of these lists is xs.
xs => 0 < xs.length
? (() => {
const [h, ...t] = xs;
const [groups, g] = t.reduce(
([gs, a], x) => eqOp(a[0])(x)
? [gs, [...a, x]]
: [[...gs, a], [x]],
[[], [h]]
);
return [...groups, g];
})()
: [];
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
return main();
ComplexPoint's solution, which I assume works but haven't tested, will be cleaner (and probably way faster) than what I was going to do, which was a variation on the looping that you were using. I'd go with that one :).
thanks. his solution will work and will be fast. I am trying to understand the design logic so that I can apply it in the future. I do not read JS or AS , etc... and to show my age I am trying to forget Fortran 4 and MS Basic. Hoping to stick with Keyboard Maestro and some shell commands. hence my request from the initial post. any help is appreciated.
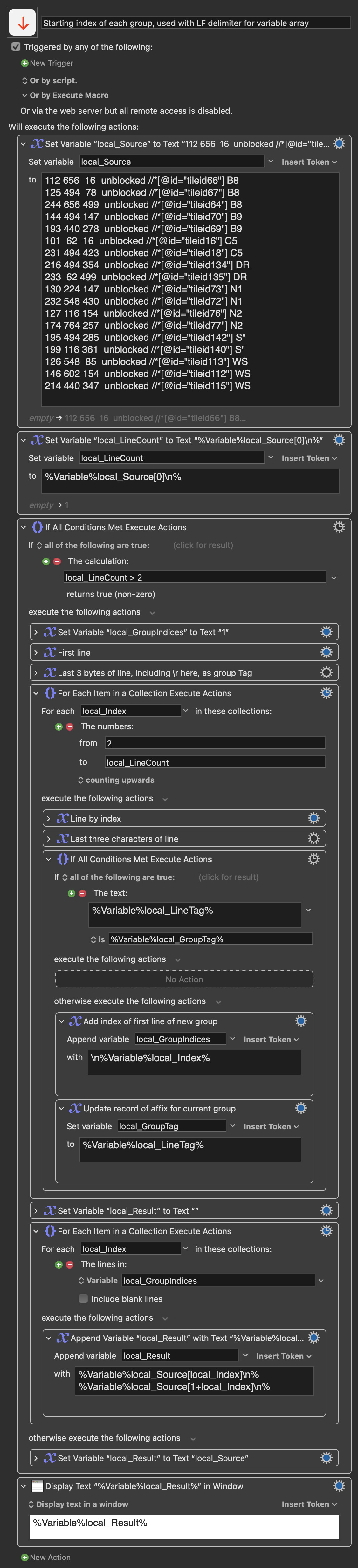
There may be a Maestronic way of grouping collection items (by some shared feature, like the last two characters, in the case of text lines) that I am failing to immediately spot, but if not, I wonder whether some kind of GROUP action might work well with any MAP action that you think of adding, at some point ?
Perhaps, in the case of grouping lines, one could let the user choose a single-character group delimiter for the grouped output,
so that Keyboard Maestro Variable Arrays (with custom delimiters) could yield access to groups as well as to individual lines ?
I appreciate the time you took to solve this request. Many thanks. It will take me some study to follow the process but it should help me in future efforts.
and we can use custom single-character delimiters, including \n ( %Linefeed% ).
This gives us line indexing, and for each group of lines defined by a shared affix, we can obtain the line number of the first line in the group. (Any line which doesn’t share an affix with its previous sibling)
The pruned copy of the input can be built by iteratively appending Lines[groupIndex] and Lines[1 + groupIndex] to an initially empty accumulator.
The main outstanding detail is whether or not you want to:
keep that redundant MS-style \r ( %Return% ) in each of your line delimiters, or
normalise your output to the macOS default of \n (%Linefeed%) only.
The macro above also assumes (perhaps implausibly) that each group of affix-sharing lines will have at least two members. You may need to add a conditional to avoid appending Lines[1 + GroupIndex] to the accumulator in cases where a particular affix is only found in one isolated line, which is followed immediately by a new group.