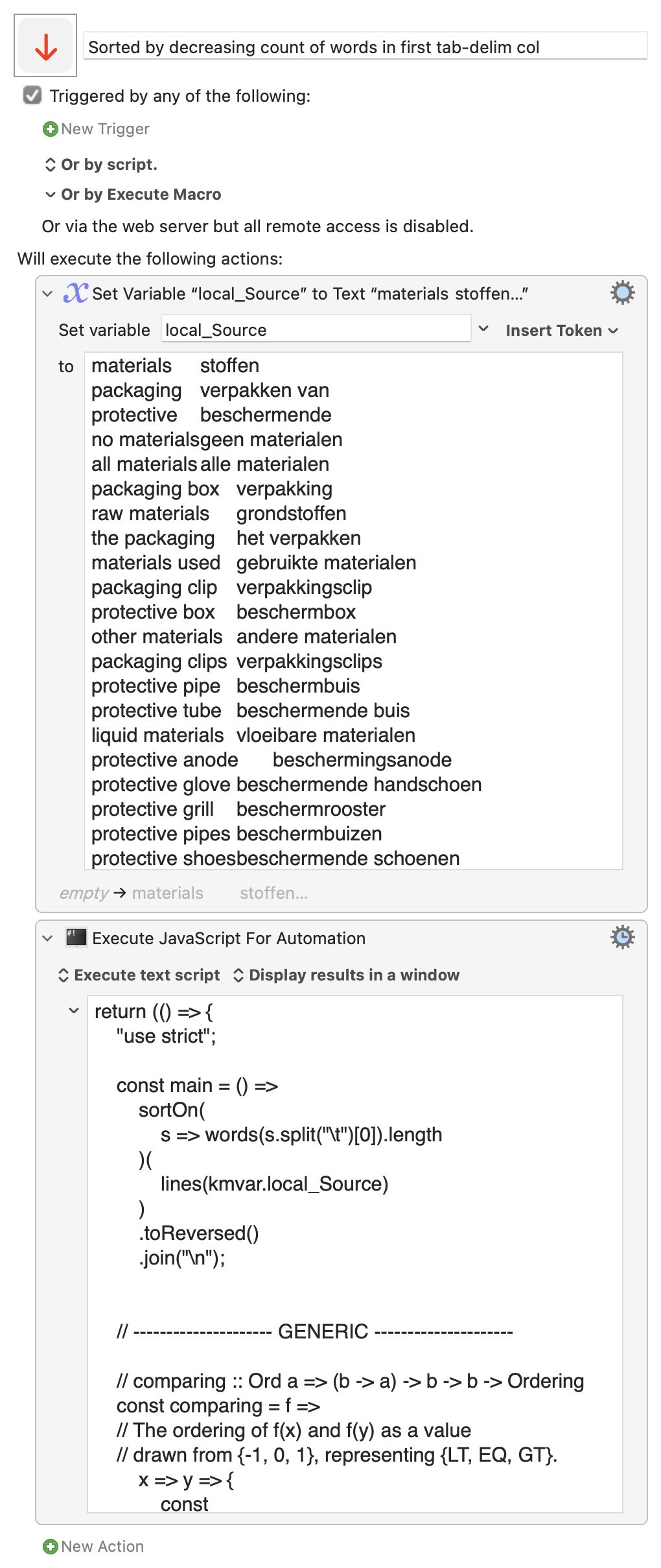
return (() => {
"use strict";
const main = () =>
sortOn(
s => words(s.split("\t")[0]).length
)(
lines(kmvar.local_Source)
)
.toReversed()
.join("\n");
// --------------------- GENERIC ---------------------
// comparing :: Ord a => (b -> a) -> b -> b -> Ordering
const comparing = f =>
// The ordering of f(x) and f(y) as a value
// drawn from {-1, 0, 1}, representing {LT, EQ, GT}.
x => y => {
const
a = f(x),
b = f(y);
return a < b
? -1
: a > b
? 1
: 0;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = f =>
// A copy of xs sorted by the comparator function f.
xs => xs.slice()
.sort((a, b) => f(a)(b));
// sortOn :: Ord b => (a -> b) -> [a] -> [a]
const sortOn = f =>
// Equivalent to sortBy(comparing(f)), but with f(x)
// evaluated only once for each x in xs.
// ('Schwartzian' decorate-sort-undecorate).
xs => sortBy(
comparing(x => x[0])
)(
xs.map(x => [f(x), x])
)
.map(x => x[1]);
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
// Leading and trailling space ignored.
s.split(/\s+/u).filter(Boolean);
// --------------------- LOGGING ---------------------
// showLog :: a -> IO ()
const showLog = (...args) =>
// eslint-disable-next-line no-console
console.log(
args
.map(JSON.stringify)
.join(" -> ")
);
// sj :: a -> String
const sj = (...args) =>
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0])
? [args[1], null, args[0]]
: [args[0], null, 2]
);
return main();
})();
I figured this was a perfect exercise for Javascript, and @ComplexPoint showed just that. Here's an alternative approach just using string manipulation in a brute force manner :). I count the characters in the first segment of each line, prepend that to the list, then sort the list based on the number and remove the characters.
Macros are always disabled when imported into the Keyboard Maestro Editor.
The user must ensure the macro is enabled.
The user must also ensure the macro's parent macro-group is enabled.
System information
macOS 14.5
Keyboard Maestro v11.0.3
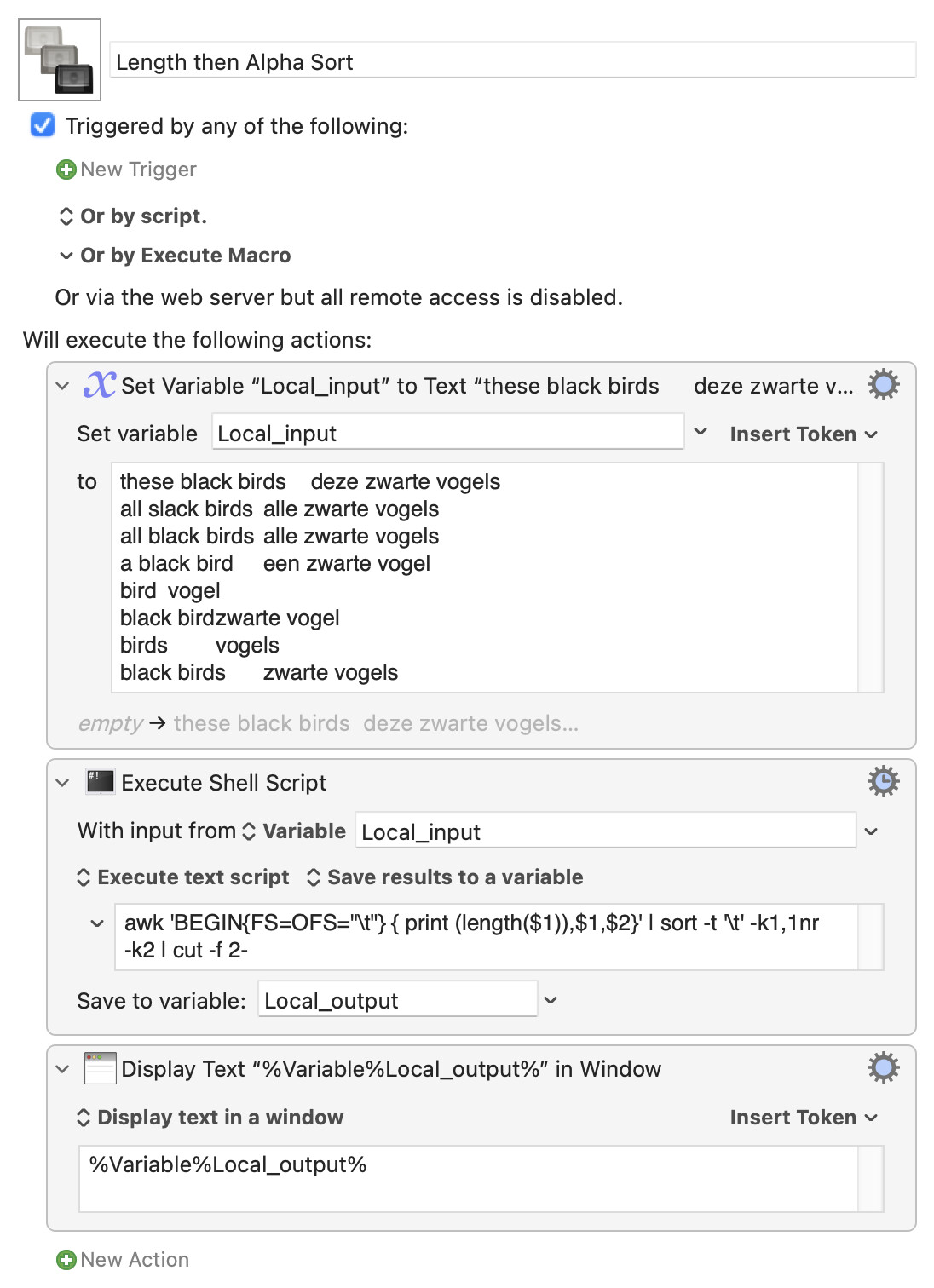
But don't use my method, it's much less efficient than the above Javascript solution—I mainly wrote it to see if what I thought would work would, in fact, work :).
Migrating 50% of the work to native KM actions is very good, but 100% would be better. I decided that a one line shell script would be "simpler" than even a 100% KM solution, which is why I wrote my solution using a shell.
More to the point, way more people here have at least some familiarity with KM's regular expressions than they do with awk. So that method of prepending character counts to a line might be more generally useful.
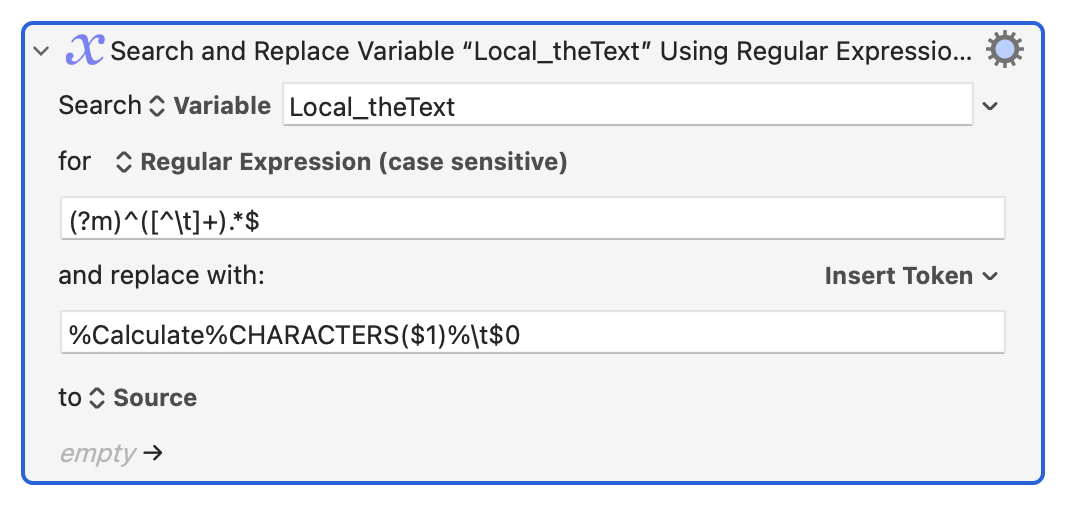
And @peternlewis has given us the ability to do a calculation using one of the capture groups and use the result in the replacement -- how cool is that?
I still haven't fully wrapped my head around how KM manages regular expressions. As you've show, it seems to be re-evaluated on a line by line basis. I'm not entirely sure how KM implements that.
If I'm understanding your question right, it's the (?m) flag that tells the regex engine to process each line separately. Without that, it treats it as a blob.
Is that different to other PCRE engines? The global /g switch you might expect to see is hidden in the action's settings as "All Matches" (the default), sure, but everything else bar the %Calculate% looks pretty standard.
The (?m) switch tells the engine to include "line start" and "line end" in ^ and $ anchor matches, /g is set, so this is just "with every occurrence that matches line-start, one or more non-tab characters, then anything else to line-end; replace with...".
For the replacement, $1 is the first capture group, $0 is the whole match (so the entire line) and the only KM-specific thing is using that first capture group in a function to get the character count, using the result in our replacement string.
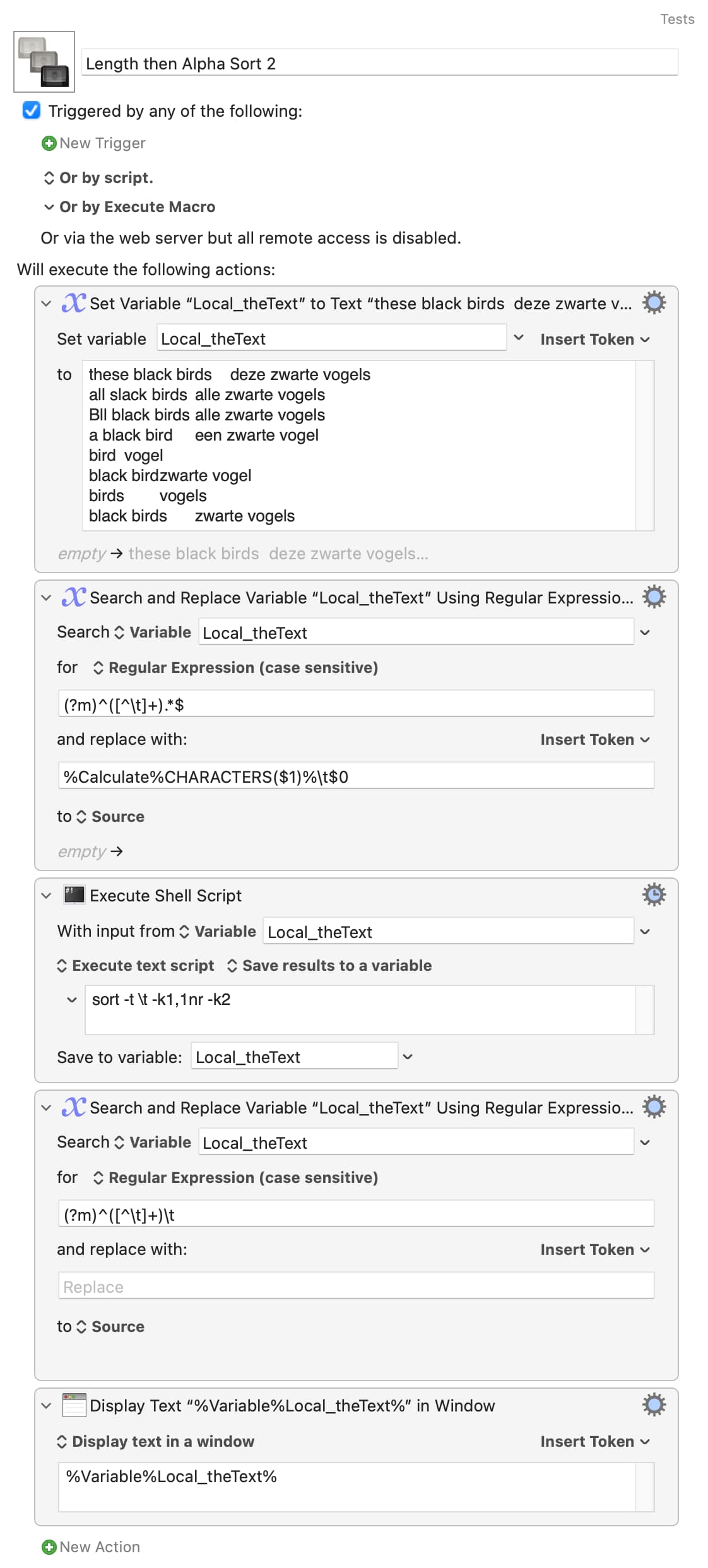
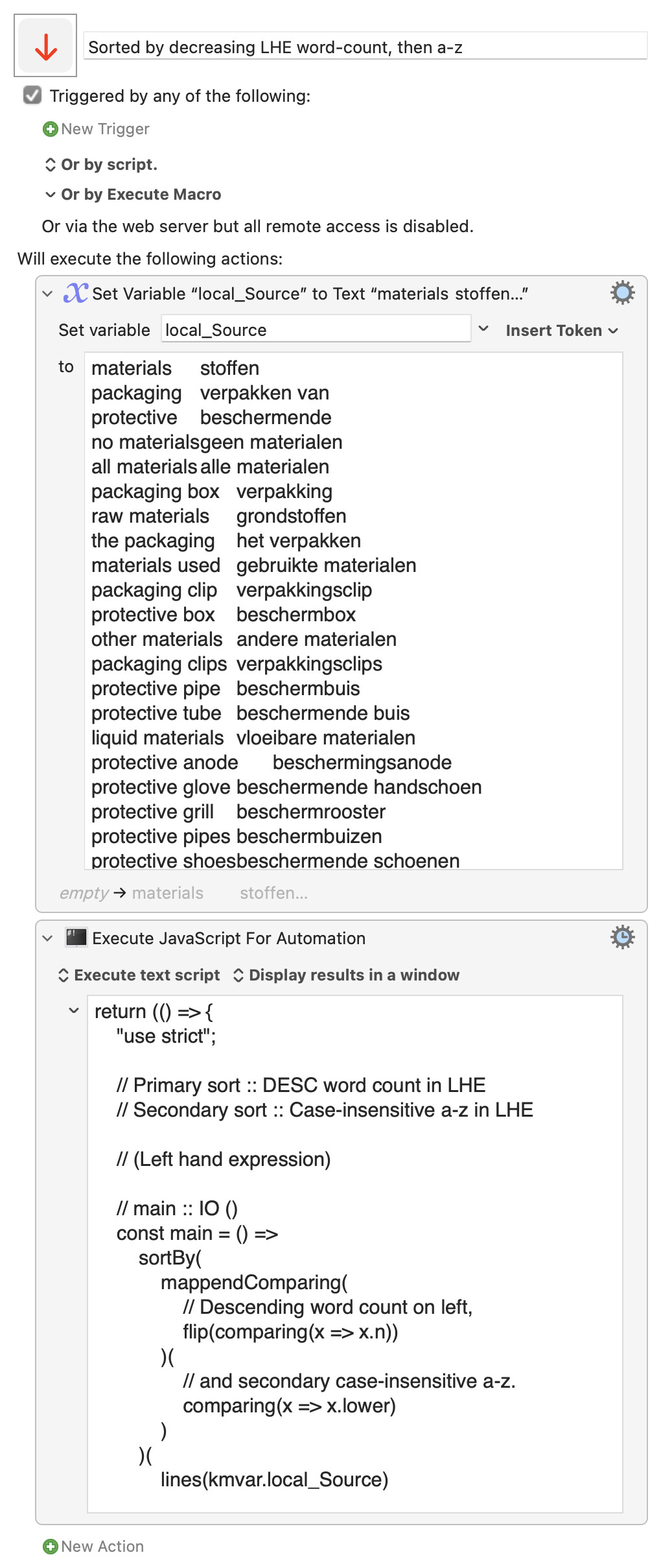
return (() => {
"use strict";
// Primary sort :: DESC word count in LHE
// Secondary sort :: Case-insensitive a-z in LHE
// (Left hand expression)
// main :: IO ()
const main = () =>
sortBy(
mappendComparing(
// Descending word count on left,
flip(comparing(x => x.n))
)(
// and secondary case-insensitive a-z.
comparing(x => x.lower)
)
)(
lines(kmvar.local_Source)
// Decorated list.
.map(s => {
const a = s.split("\t")[0];
return {
s,
lower: toLower(a),
n: words(a).length
};
})
)
// undecorated list.
.map(x => x.s)
.join("\n");
// --------------------- GENERIC ---------------------
// comparing :: Ord a => (b -> a) -> b -> b -> Ordering
const comparing = f =>
// The ordering of f(x) and f(y) as a value
// drawn from {-1, 0, 1}, representing {LT, EQ, GT}.
x => y => {
const
a = f(x),
b = f(y);
return a < b
? -1
: a > b
? 1
: 0;
};
// flip :: (a -> b -> c) -> b -> a -> c
const flip = op =>
// The binary function op with
// its arguments reversed.
1 !== op.length
? (a, b) => op(b, a)
: (a => b => op(b)(a));
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
0 < s.length
? s.split(/\r\n|\n|\r/u)
: [];
// mappendComparing (<>) :: (a -> a -> Bool)
// (a -> a -> Bool) -> (a -> a -> Bool)
const mappendComparing = cmp =>
cmp1 => a => b => {
const x = cmp(a)(b);
return 0 !== x
? x
: cmp1(a)(b);
};
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = f =>
// A copy of xs sorted by the comparator function f.
xs => xs.slice()
.sort((a, b) => f(a)(b));
// toLower :: String -> String
const toLower = s =>
// Lower-case version of string.
s.toLocaleLowerCase();
// words :: String -> [String]
const words = s =>
// List of space-delimited sub-strings.
// Leading and trailling space ignored.
s.split(/\s+/u).filter(Boolean);
// MAIN ---
return main();
})();
I'm trying to understand this. You first define the tab character as a separator. Then you add the length of column 1 of every line to a new column 0, then you sort on that column (which then has become column 1). And then you run awk again to just print the columns 2 and 3?
I think you understand it, taking Nige's comment into consideration.
Yes, shell scripts are amazingly powerful. I have a new macro that uses shell scripts to help us, but it's so big I need to take some time to test it before I upload it.