The amount of pages in a manual is rarely an indicator of the power or the usefulness of a tool
Awk shines when it comes to structured data, or better: data that can be structured. Recognizing fields in an record and then attemptimg to work with the fields (which includes the separators) is always better than treating the separators as mere strings and brute-forcely replacing them via regex. I think.
But, I think, you can achieve the same with Perl without regexes (i.e. only by manipulating separators). Beyond my current Perl knowledge
Concerning the gawk on macOS, I’m not sure. Most likely macOS has just awk, who knows which version. Have to look it up. I got a related problem here.
Edit:
No, gawk, as expected, comes only when installed via Homebrew or similar. But I don’t know the differences between gawk and awk, and I don’t know if awk/gawk scripts tend to use only the specific implementation (gawk or awk) or if they generously default to the one that is installed. (I have no practice with awk scripting.)
If you are like many computer users, you would frequently like to make changes in various text files wherever certain patterns appear, or extract data from parts of certain lines while discarding the rest.
That’s what I meant with “data that can be structured”. I tend to use Awk for that. Although “in general” I prefer Perl for text (not for data) manipulation. But applying regexes while clearly a data structure is present (delimeters, fields, etc.) feels a bit clunky/forced/out-of-place. But I’m sure Perl also has Awk-like capabilities (if not better!) to handle fields and such. I just don’t know them.
Yes, I started out (ie, several decades ago) using sed & awk for text processing. But since perl does everything they do and more, I tend to use perl directly instead of sed or awk for most tasks.
Basically, sed and awk are very useful tools, but they tend to be limited in what they can do, and when you hit the limit then you have to start again from scratch, which is why I tend to just use perl, which can do the sort of text processing that sed and awk can do, but then extends out to anything else as needed.
But just like @ComplexPoint reaches for JavaScript and @ccstone reaches for AppleScript, we all tend to use whatever tools we are most familiar with to solve any given task.
Yep, something like that is what I had in mind as I said “But I’m sure Perl also has Awk-like capabilities (if not better!) to handle fields and such. I just don’t know them.”
But here's why I would normally reach for AppleScript and the Satimage.osax:
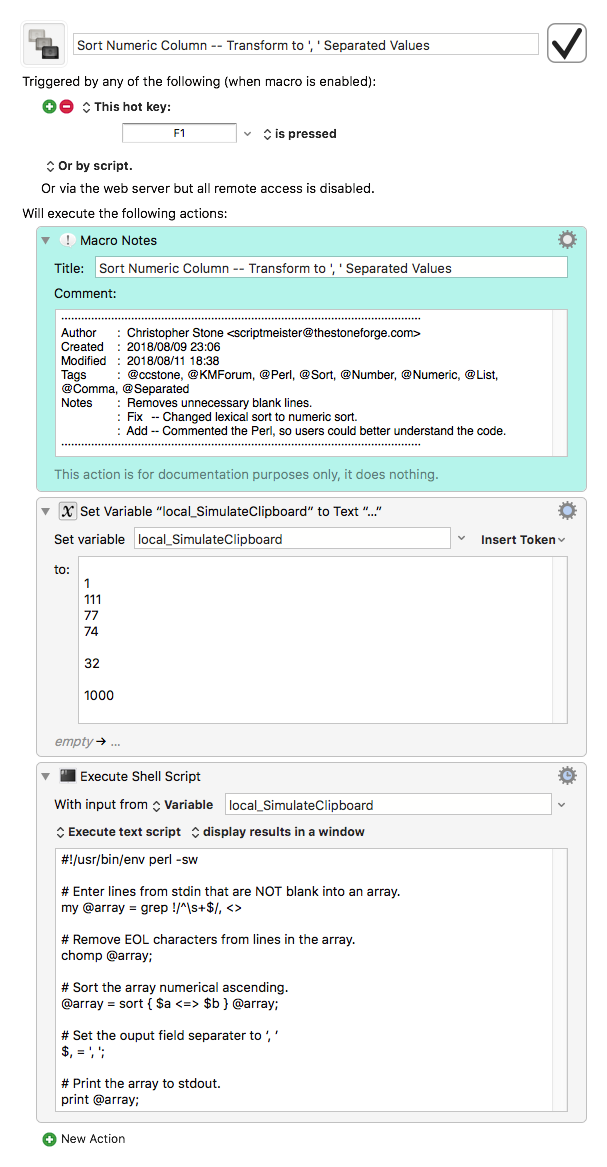
----------------------------------------------------------------
# REQUIRES: Satimage.osax --> http://tinyurl.com/satimage-osaxen
# AppleScript and the Satimage.osax are fully Unicode-aware.
----------------------------------------------------------------
# Make sure the clipboard has what we want on it:
set the clipboard to text 2 thru -2 of "
77
74
32
"
----------------------------------------------------------------
--» Main
----------------------------------------------------------------
set numList to join (sortlist (find text "\\d+" in (get the clipboard) with regexp, all occurrences and string result) comparison 2) using ", "
----------------------------------------------------------------
--> "32, 74, 77"
----------------------------------------------------------------
I really like sed and awk, but they are fairly obsolete (GNU sed and GNU awk notwithstanding), because they don't handle Unicode text very adroitly.
So – my recommendation is:
Learn as much sed and awk as you want – particularly snippets that are useful.
But if you want to seriously study something then study Perl. It's Unicode-aware and many times more powerful than sed and awk combined.
Of all of the bash solutions, this script is the most readable to me.
Of course, readability depends in large part on the reader's knowledge of the language, and I'm clearly a novice at bash.
But I do enjoy RegEx, so it is fairly easy for me to read this script, and make changes to it if need be.
However, we have a number of good choices posted here, so you can pick the one whose language you understand/like the best.
Yes. I thought I explained why. I already know some RegEx so it is easy for me to read the perl commands. Whereas I don't know any of the other commands you used (other than sort).
For those that don't know RegEx, the perl probably looks like gibberish.
BTW, I didn't say one was better than the other -- just which one was more readable to me. YMMV.
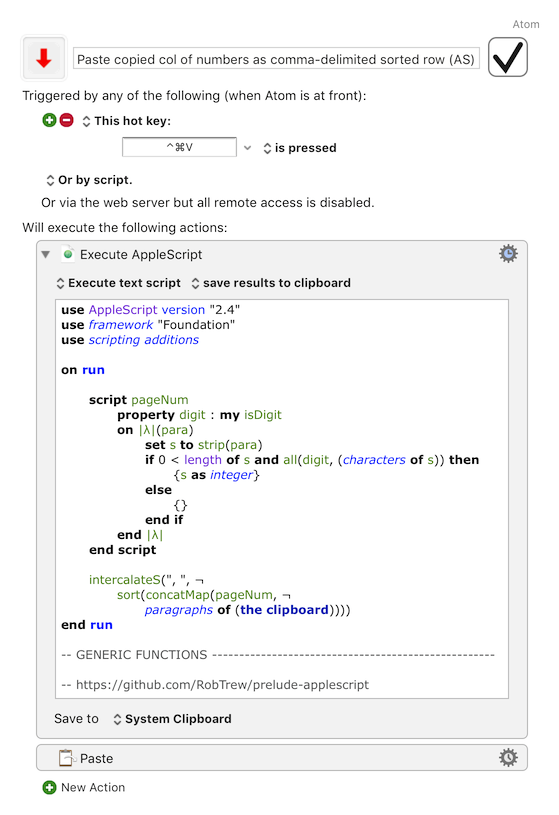
use AppleScript version "2.4"
use framework "Foundation"
use scripting additions
on run
script pageNum
property digit : my isDigit
on |λ|(para)
set s to strip(para)
if 0 < length of s and all(digit, (characters of s)) then
{s as integer}
else
{}
end if
end |λ|
end script
intercalateS(", ", ¬
sort(concatMap(pageNum, ¬
paragraphs of (the clipboard))))
end run
-- GENERIC FUNCTIONS ------------------------------------------------------
-- https://github.com/RobTrew/prelude-applescript
-- Applied to a predicate and a list, `all` determines if all elements
-- of the list satisfy the predicate.
-- all :: (a -> Bool) -> [a] -> Bool
on all(f, xs)
tell mReturn(f)
set lng to length of xs
repeat with i from 1 to lng
if not |λ|(item i of xs, i, xs) then return false
end repeat
true
end tell
end all
-- concatMap :: (a -> [b]) -> [a] -> [b]
on concatMap(f, xs)
set lng to length of xs
if 0 < lng and class of xs is string then
set acc to ""
else
set acc to {}
end if
tell mReturn(f)
repeat with i from 1 to lng
set acc to acc & |λ|(item i of xs, i, xs)
end repeat
end tell
return acc
end concatMap
-- drop :: Int -> [a] -> [a]
on drop(n, xs)
if n < length of xs then
if text is class of xs then
text (n + 1) thru -1 of xs
else
items (n + 1) thru -1 of xs
end if
else
{}
end if
end drop
-- dropWhile :: (a -> Bool) -> [a] -> [a]
-- dropWhile :: (Char -> Bool) -> String -> String
on dropWhile(p, xs)
set lng to length of xs
set i to 1
tell mReturn(p)
repeat while i ≤ lng and |λ|(item i of xs)
set i to i + 1
end repeat
end tell
drop(i - 1, xs)
end dropWhile
-- dropWhileEnd :: (a -> Bool) -> [a] -> [a]
-- dropWhileEnd :: (Char -> Bool) -> String -> String
on dropWhileEnd(p, xs)
set i to length of xs
tell mReturn(p)
repeat while i > 0 and |λ|(item i of xs)
set i to i - 1
end repeat
end tell
take(i, xs)
end dropWhileEnd
-- intercalateS :: String -> [String] -> String
on intercalateS(sep, xs)
set {dlm, my text item delimiters} to {my text item delimiters, sep}
set s to xs as text
set my text item delimiters to dlm
return s
end intercalateS
-- isDigit :: Char -> Bool
on isDigit(c)
set n to (id of c)
48 ≤ n and 57 ≥ n
end isDigit
-- isSpace :: Char -> Bool
on isSpace(c)
set i to id of c
i = 32 or (i ≥ 9 and i ≤ 13)
end isSpace
-- min :: Ord a => a -> a -> a
on min(x, y)
if y < x then
y
else
x
end if
end min
-- Lift 2nd class handler function into 1st class script wrapper
-- mReturn :: First-class m => (a -> b) -> m (a -> b)
on mReturn(f)
if class of f is script then
f
else
script
property |λ| : f
end script
end if
end mReturn
-- sort :: Ord a => [a] -> [a]
on sort(xs)
((current application's NSArray's arrayWithArray:xs)'s ¬
sortedArrayUsingSelector:"compare:") as list
end sort
-- strip :: String -> String
on strip(s)
script isSpace
on |λ|(c)
set i to id of c
i = 32 or (i ≥ 9 and i ≤ 13)
end |λ|
end script
dropWhile(isSpace, dropWhileEnd(isSpace, s))
end strip
-- take :: Int -> [a] -> [a]
on take(n, xs)
if class of xs is string then
if n > 0 then
text 1 thru min(n, length of xs) of xs
else
""
end if
else
if n > 0 then
items 1 thru min(n, length of xs) of xs
else
{}
end if
end if
end take