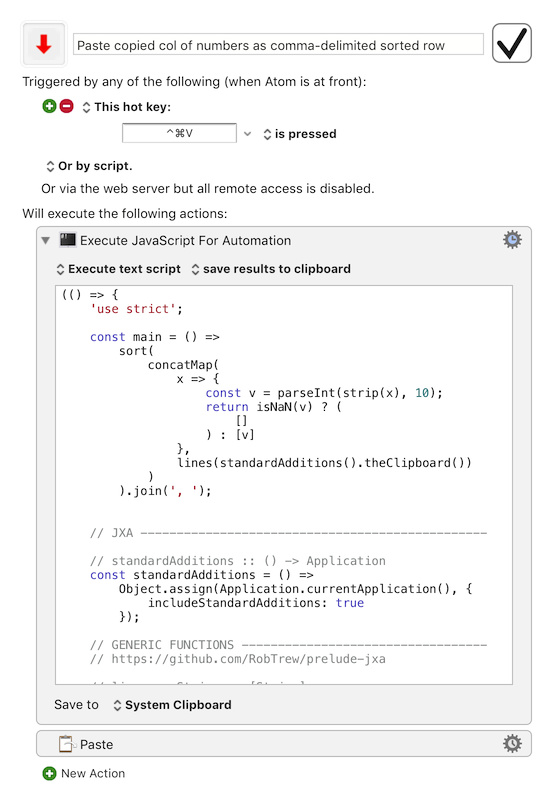
I’m hoping to copy some cells in Numbers (each cell contains a number). I’m wanting to convert the clipboard to plain text, convert the carriage returns into a comma space, and then sort the numbers into ascending order. This is for an index for a book.
The clipboard with plain text values would change from
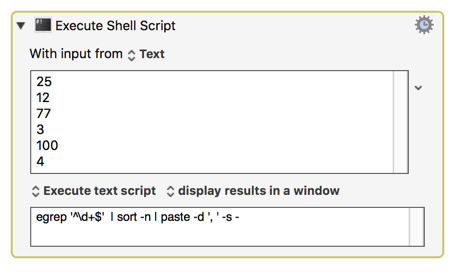
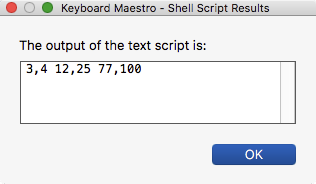
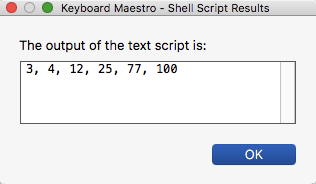
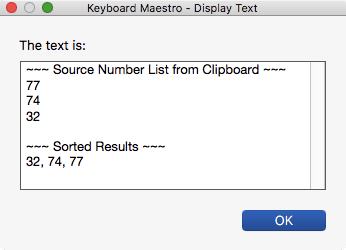
77
74
32
Peter, thanks for the cool script.
It sorts fine, but the format is a bit off.
How can I adjust to make it consistent, with a ", " (comma space) after every number?
Sorry, my mistake, paste-d option does not work like I thought, it rotates through the characters.
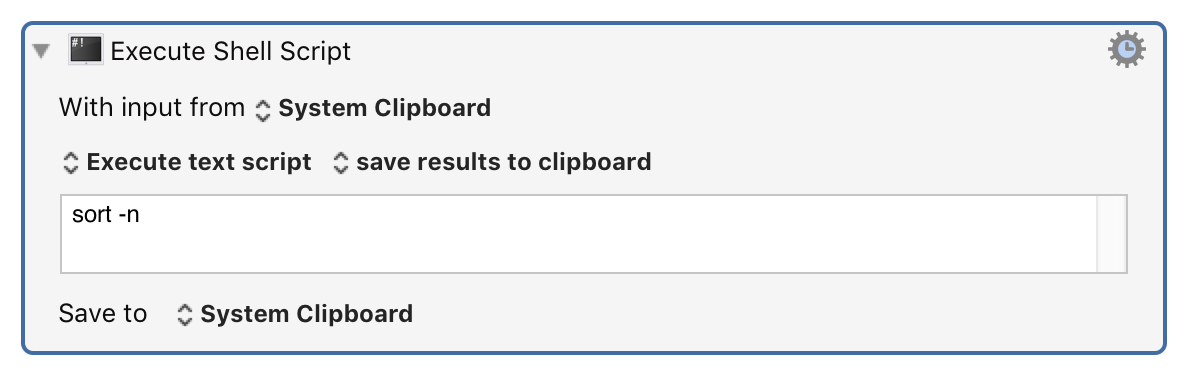
So you'd have to follow the paste -d, with yet another pipe and replace the commas with comma-space.
You would think. Part of the issue is not wanting to include the trailing , which is why paste works well.
So a good solution would be:
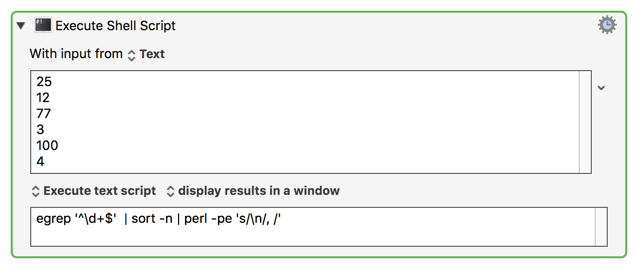
paste -sd, - | sed 's/,/, /g'
Alternatively, perl has no problem changing the trailing \n into a comma-space.
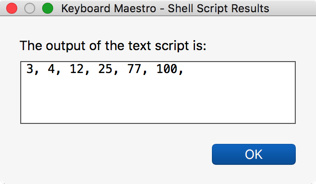
perl -pe 's/\n/, /'
And some of this comes back to the discussion about a line ending character at the end of the text. I contend that normal multiline text ends with a linefeed. But either way you need to consider the end of the text and how that behaves as regards to replacing text. \n will only match a linefeed, but $ or \z or \Z will match at the end of the last line even if it does not have a trailing linefeed, although they are all zero width assertions so can't replace the linefeed.
Traditionally I have used a triangle (eg △), and word processors with “show invisibles” typically use a grey middle dot (eg ·) (BBEdit uses this for example). But realistically if you don't write it out no one is going to know what you mean.
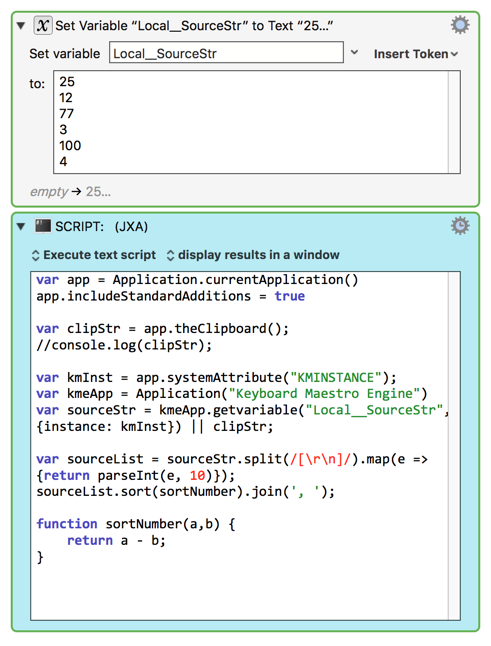
I am generally not a fan of compacting code just for the sake of doing so, but if we limit the input to the clipboard, the JavaScript could be:
var app = Application.currentApplication()
app.includeStandardAdditions = true
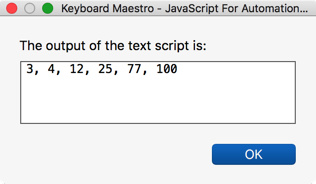
var sourceList = app.theClipboard().split(/[\r\n]/).map(e => {return parseInt(e, 10)});
sourceList.sort(sortNumber).join(', ');
function sortNumber(a,b) { return a - b; }
In case anyone is following the RegEx from the other thread, JavaScript does NOT support \R. So we have to use workarounds like [\r\n], which really should be: \r?\n|\r
Where is @Tom? He is always really good at these games.
Yes, that was why paste was good, because it avoids that.
You can also remove the trailing “, ” with:
perl -pe 's/, $//'
so
perl -pe 's/\n/, /' | perl -pe 's/, $//'
But yes, a surprisingly complicated problem to get right. And a good reminder that you really have to know what the limitations on the input and what the desired output is.
MACRO: Sort Numbers on Clipboard and Format Output [Example] @Bash
#### DOWNLOAD:
<a class="attachment" href="/uploads/default/original/3X/c/5/c54e84508977cf0674da8ff602de29cd17ca4ab9.kmmacros">Sort Numbers on Clipboard and Format Output [Example] @Bash.kmmacros</a> (3.0 KB)
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---

If you are like many computer users, you would frequently like to make changes in various text files wherever certain patterns appear, or extract data from parts of certain lines while discarding the rest. To write a program to do this in a language such as C or Pascal is a time-consuming inconvenience that may take many lines of code. The job is easy with awk, especially the GNU implementation: gawk.