Context: I'm new to Keyboard Maestro, and have limited knowledge of programming (I'm in UX design not a development)
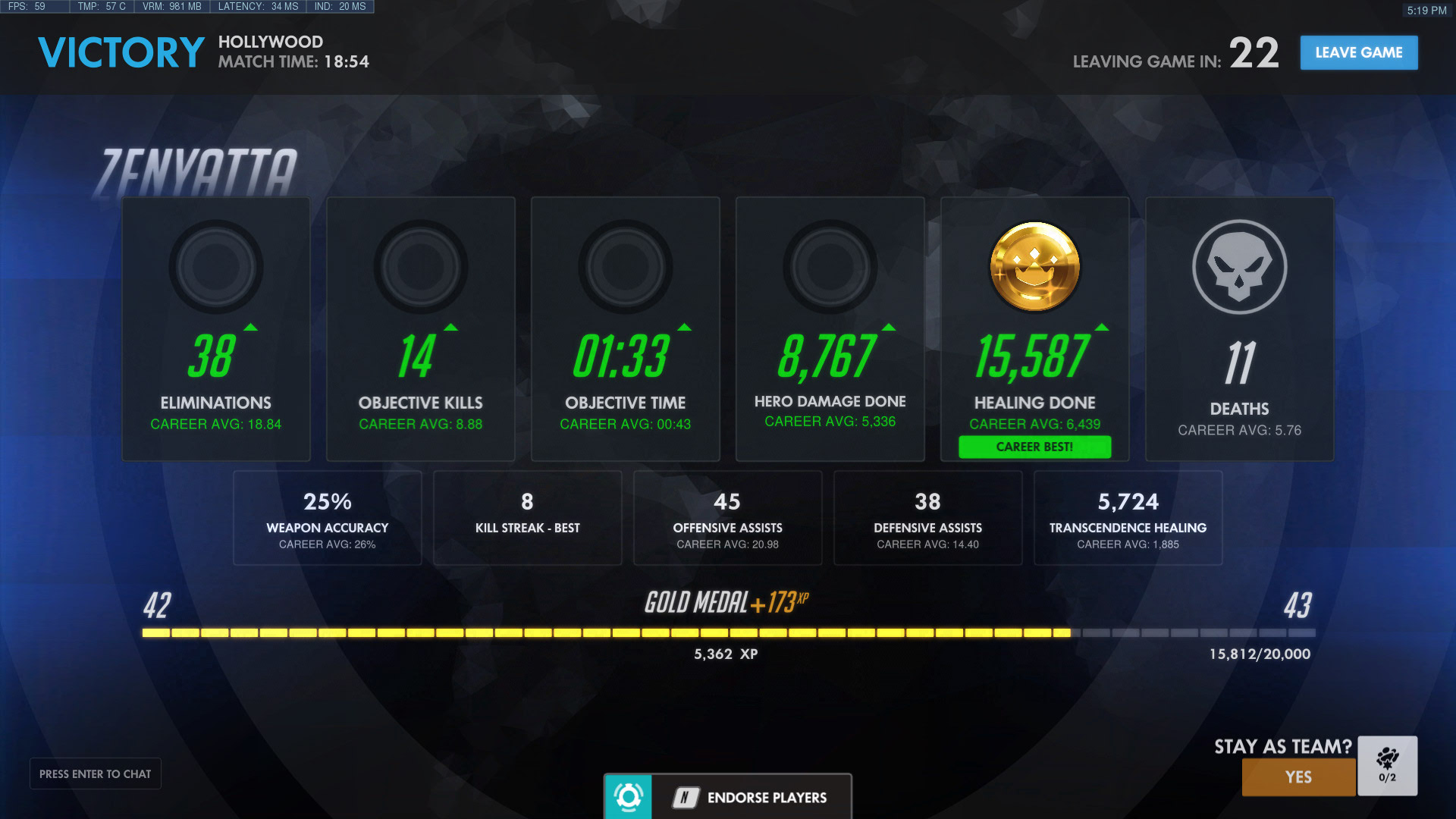
I'm trying to get numbers from a screenshot I take at the end of a match of Overwatch when your statistics for the match are shown.
I've uploaded the screenshot I start with (Example A: OG_Screenshot.jpg).
I'm expecting to do some light work in photoshop to get rid of the complexities that the screenshot has initially. That photoshop work should get any given screenshot to a much cleaner state (Example B: BW3.jpeg)
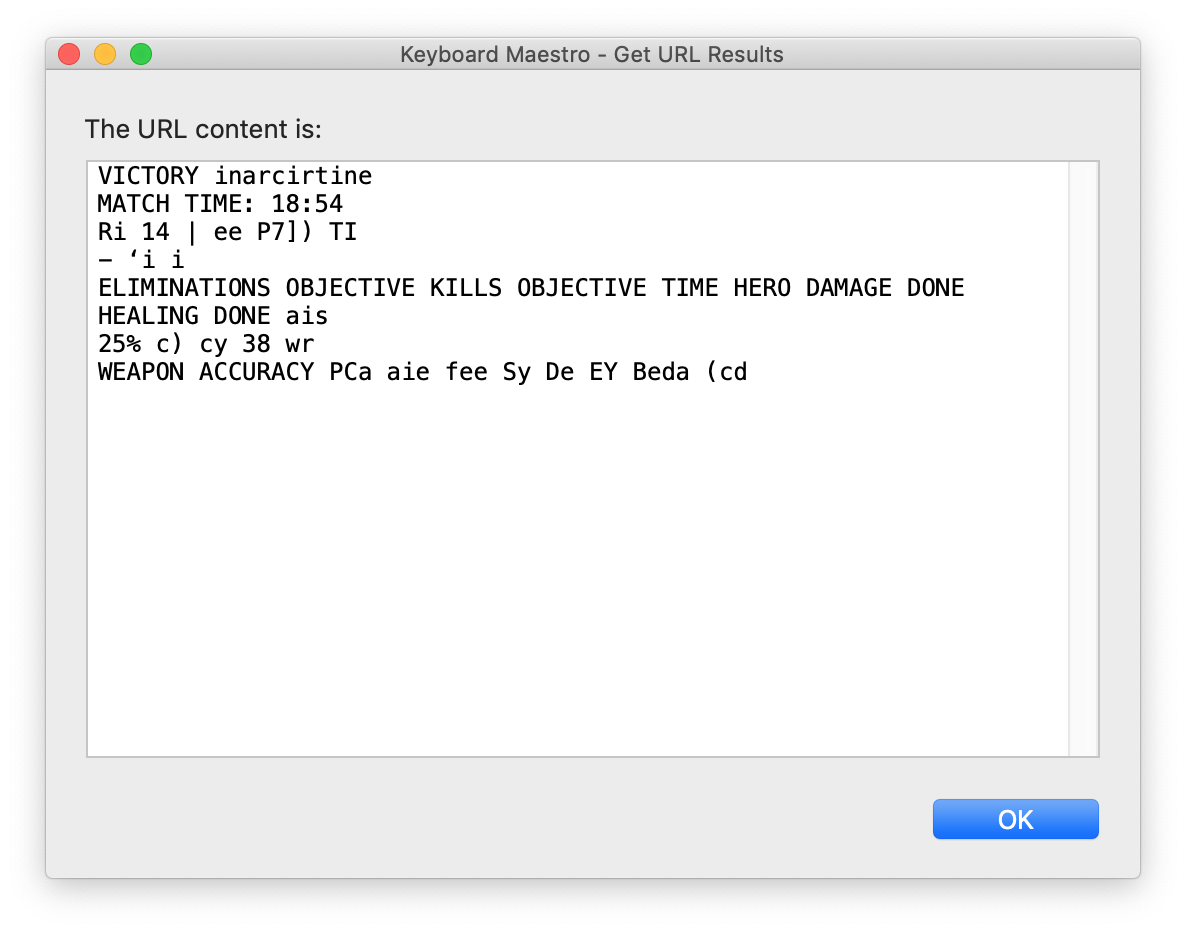
I haven't been able to get as much usable text as I would have hoped (Example C: KM_Output.png)
My question is how might I get all of the text in BW3.jpeg into Keyboard Maestro?
(The end goal pull all of the screenshot statistics into an existing google sheets doc where I do a bunch of analysis, but I'll raise those questions further on down the road)
I'm still learning to control the OCR action myself. But I'm making progress. One thing I've learned is that when an image contains multiple font sizes, it works better if you use the AREA option in the OCR action to isolate the areas with the different font sizes. That way the OCR action is dealing with only one font size per area. (This should also speed up your results, as OCR is pretty slow.)
In your case you have huge diagonal fonts mixed with regular fonts of two different sizes. Try isolating those areas with separate OCR actions for better results. This is especially true when part of the image contains graphics, as does your first example.
From my experience your second example should be fairly easy to get perfect results. Your first one will be a little trickier.
I'm also working on some algorithms that use the OCR action multiple times on the same area to see if the results can be improved, but I haven't finished that yet. Not enough to post anything. But the OCR action is a little slow, and using it multiple times on the same area makes it even slower.
I am NOT getting usable results either even when I just select one of the numbers, and OCR that. I don't know how the OCR engine works, but my guess is that it uses the fonts for the language you have selected for OCRing. I doubt that the numbers on your screenshot correspond to a standard font.
So, I'm not hopeful that you will get a usable result using the OCR engine that KM has chosen. It is documented, and does offer different languages, so it is possible that you could contact the developers of the OCR engine to ask them if there is a way to OCR the numbers in your screenshot.
As a side note, I also have SnagIT, which has its own OCR engine, and I was able to properly OCR one of the numbers using SnagIT.
Using the B&W screenshot with SnagIT I got good results:
That is true, minimizing the search area can cause problems. Another tip I've learned is try to include multiple columns of text. Somehow that helps the OCR code work better. And he does have multiple columns.
Tesseract OCR is basically a machine learning system with trained values fed in to it. So it works with fonts and text and colors that it has seen, and the further from that the worse it gets.
I tried several image pre-processing on the white-on-black image you posted, and inverting it gets closer, but still far from useful.
So maybe some resizing might work, but other than that, the only option would be using a custom trained data file, and I'm not familiar with how to do that (Keyboard Maestro allows custom trained data, but it is not something I have investigated or support directly).
Well I greatly appreciate everyone chiming in. It looks like it may not be possible at this point, but I definitely learned some useful things about OCR technology along the way.
OCR different styled text separately
White background with black text seems to work better
Include multiple columns of text
SnagIT is another possible OCR program one could tie into the Keyboard Maestro macro (Currently $49.95)
I haven't exhausted my bag of tricks yet. Eg, many application developers know that many of their users are colour blind. So they provide a way to modify their colour palette for colourblind users. If you change the app's settings this way, you can usually get improved OCR.