Yesterday, using OCR to grab text from images was working fine, but now I'm getting this weird text (shown in screenshot). Help?
Yesterday, using OCR to grab text from images was working fine, but now I'm getting this weird text (shown in screenshot). Help?
A variety of factors can affect how well OCR works.
This is what I got from OCR'ing your posted image:
be CE hue bed
Racy
-Chris
Ok, so there isn't something wrong with my app then, that's just the way it is sometimes?
I find that SOMETIMES stopping and starting the OCR engine gets it to start working again. Other times you have to change the rectangle you are searching in (usually making it larger, vertically, helps.) And here's a really amazing thing: I find it works better what I change the language to French. Yup, crazy idea, but it solves a lot of problems. Changing the language like that shouldn't help at all, but it does for me.
P.S. When Monterey arrives, (I'm already using the Beta) there's a way to use Monterey's OCR within KM, and that improves the accuracy of the OCR dramatically.
How do I stop/restart the OCR engine?
French? Wow, that's nuts!  I'll have to try that.
I'll have to try that.
Under the File menu in KM you can stop the engine and restart it.
Yup, it's crazy that French would detect English better than English. But for me it does.
A KM macro can stop the KM engine, but naturally it can't restart it. There are ways in macOS to automatically stop and restart the engine every, say, hour, but of course that could interfere with any running macros. With certain tricky steps, you can also get a KM macro to stop and restart the engine.
I saved an AppleScript that quits the engine and then restarts it an application and can trigger that from within KM.
I have found that after making a lot of edits to a lot of macros (especially if I’m working with clipboards) the engine starts lagging and restarting it makes everything run faster again. So I do that periodically.
Oh, I see. You meant the KM engine. I thought you were talking about a separate engine just for OCR.
I'm sorry about that misunderstanding. It does appear I misspoke.
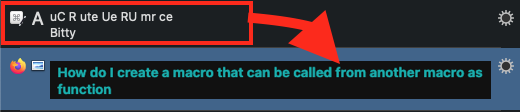
As an experiment, I optimized just the teal text in your image, enlarging it, reducing it to grayscale and increasing the contrast:
This allowed the second line to be OCRed accurately but not the first: "De CE Bue Race un Rieu Um ed function"
So I reset the type in an image editing program, recreating the image:

That delivered accurate results: "How do I create a macro that can be called from another macro as a function"
Then it occurred to me to reverse the optimized version of the original image:
That's pretty blurry, but it was easily readable: "How do I create a macro that can be called from another macro as function"
I think this shows the quality of the text in the image to be OCRed is the determining factor in this case. While it's easy for human eyes to read the original, even a version of the image optimized for OCR wasn't legible to the software while a reset version with a little more clarity in the type was converted correctly.
So in this case it isn't Keyboard Maestro's engine or the OCR package but the image.
Update: 18 August 2021
For a deeper dive into optimizing images for OCR see Tesseract's Improving the Quality of the Output. Tesseract is the OCR engine Keyboard Maestro uses.

