The new OCR feature is pretty darn good. And it used tesseract which is particularly interesting for me, as that widens the spectrum of possibilities.
I am curious, is it possible to OCR an entire PDF file with Keyboard Maestro? I imagine it won't be very straight forward. Anyone tried it yet?
Yep, it's possible. Nope, I have not tried it, but you can use this Action:
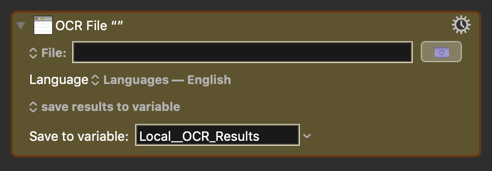
2 Likes
Duh... How did I miss that? Thanks for answering and sorry for the silly question.
1 Like
Not really, no.
The OCR can OCR images, which a PDF is sort of, but only the first page is OCRed.
And when people talk about OCRing a PDF, generally what they really mean is creating a “searchable PDF”, which is a PDF with text inlayed that can be searched and selected. Keyboard Maestro cannot generate this sort of thing.
So you can extract the text from a single page PDF using the OCR Image file action, but that is the limit to it. Otherwise you'll need a tool that works with PDF files.
Would it be possible for it to the extract all the pages in the PDF?
If you just want the text from the PDF image (as opposed to having a searchable PDF), then you could export the PDF as images. Looks like Mac Preview.app will do that.
Then run the KM OCR action on the image file.
You could use the KM Select or Show a Menu Item action to open the PDF and do the export.