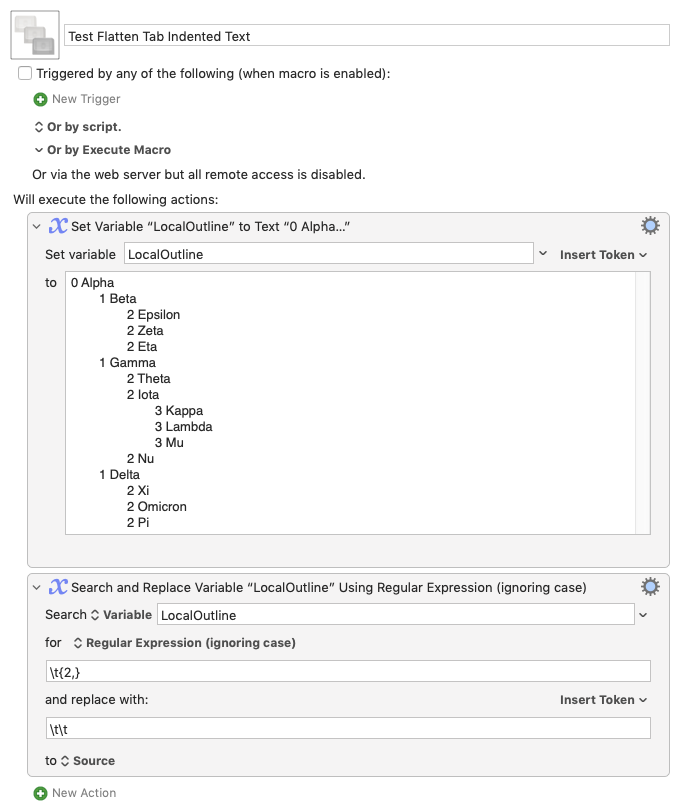
I regularly create mind maps that are n-levels deep. I want to convert them into an outline in another app that is flattened to three levels: topic, subheads & details. So level 0 and level 1 would stay the same, and levels 2-n would all be converted to level 2.
The mind map can be exported in outline form in a text file. The text file expresses the hierarchy as a return, a number of tabs for the outline level, and the outline node string.
So far, so good. All I have to do is search for the number of tabs which represent level n down to level 2 and replace them with the tabs that represent level 2.
Unfortunately, I don't know how to determine the level I'm supposed to start with -- level n. How do I figure out how many tabs is the maximum for the outline?
Also, is there a more elegant way to approach this conversion?
(() => {
"use strict";
// ----------- PARTIALLY FLATTENED OUTLINE -----------
// Ver 0.01
const main = () => {
const
kme = Application("Keyboard Maestro Engine"),
kmVar = kme.getvariable,
maxDepth = kmVar("maxOutlineDepth"),
maxDepthInt = parseInt(maxDepth, 10);
return isNaN(maxDepthInt) ? (
Left(`Expected integer maxOutlineDepth, saw ${maxDepth}`)
) : (() => {
const
inputOutline = kmVar("inputOutline"),
lineLevels = indentLevelsFromLines(
lines(inputOutline)
),
minimumIndent = Math.min(
...lineLevels.map(fst)
);
return lineLevels.map(
([indent, text]) => {
const
n = Math.min(
maxDepth, indent - minimumIndent
);
return `${"\t".repeat(n)}${text}`;
}
)
.join("\n");
})();
};
// -------------------- OUTLINES ---------------------
// indentLevelsFromLines :: [String] -> [(Int, String)]
const indentLevelsFromLines = xs => {
const
pairs = xs.map(
x => bimap(
cs => cs.length
)(
cs => cs.join("")
)(
span(isSpace)([...x])
)
),
indentUnit = pairs.reduce(
(a, [i]) => 0 < i ? (
i < a ? i : a
) : a,
Infinity
);
return [Infinity, 0].includes(indentUnit) ? (
pairs
) : pairs.map(first(n => n / indentUnit));
};
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
// A pair of values, possibly of
// different types.
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2,
*[Symbol.iterator]() {
for (const k in this) {
if (!isNaN(k)) {
yield this[k];
}
}
}
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => m.Left ? (
m
) : mf(m.Right);
// bimap :: (a -> b) -> (c -> d) -> (a, c) -> (b, d)
const bimap = f =>
// Tuple instance of bimap.
// A tuple of the application of f and g to the
// first and second values respectively.
g => tpl => Tuple(f(tpl[0]))(
g(tpl[1])
);
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => e.Left ? (
fl(e.Left)
) : fr(e.Right);
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
([x, y]) => [f(x), y];
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// isSpace :: Char -> Bool
const isSpace = c =>
// True if c is a white space character.
(/\s/u).test(c);
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single string
// which is delimited by \n or by \r\n or \r.
Boolean(s.length) ? (
s.split(/\r\n|\n|\r/u)
) : [];
// span :: (a -> Bool) -> [a] -> ([a], [a])
const span = p =>
// Longest prefix of xs consisting of elements which
// all satisfy p, tupled with the remainder of xs.
xs => {
const i = xs.findIndex(x => !p(x));
return -1 !== i ? (
Tuple(xs.slice(0, i))(
xs.slice(i)
)
) : Tuple(xs)([]);
};
// sj :: a -> String
const sj = (...args) =>
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0]) ? [
args[1], null, args[0]
] : [args[0], null, 2]
);
// MAIN ---
return main();
// return sj(main());
})();