I am an academic that uses bibliographic management software called Papers. After I highlight my manuscripts Papers allows me to export all my highlights and comments as a single file.
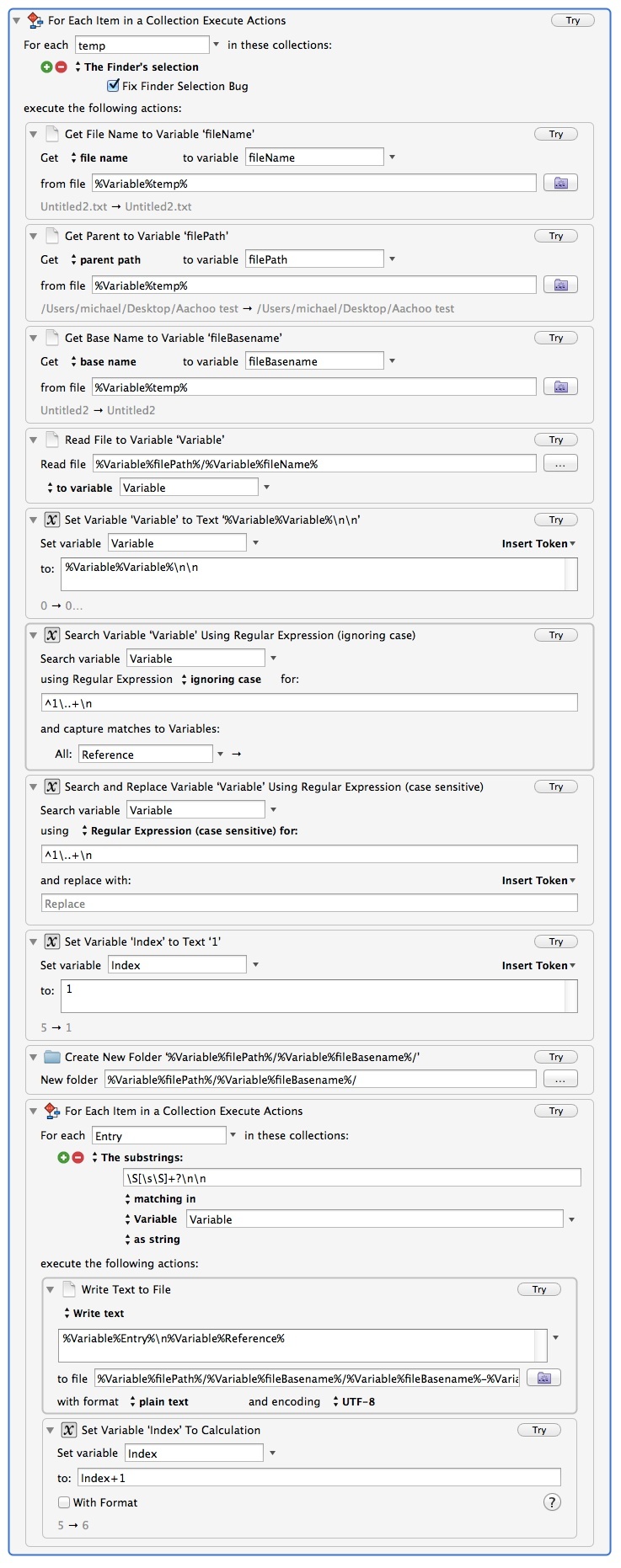
I am trying to figure out how to parse that single file into individual files (each highlight or comment as its own file) using KM. I am stuck, unable to parse the single file in multiple files–I thought I’d ask the group for ideas. Below is a sample of the single exported note that I’m trying to break into pieces.
Peter tried to help me–but I’m a novice with KM and haven’t been able to get the script to work over the last 2 days. I think I need to be told explicitly the name of each command and submenu. Sorry I’m such a neophyte.
Thanks!
Rosen MA, Dietz AS, Yang T, Priebe CE, Pronovost PJ. An integrative framework for sensor-based measurement of teamwork in healthcare. Journal of the American Medical Informatics Association. 2014:amiajnl–2013–002606. doi:10.1136/amiajnl-2013-002606.
p.1: The large, multidisciplinary science of teams has informed the development of measurement systems.7–9 – Highlighted jul 24, 2014
p.1: Breakdowns in teamwork and communication are an independent cause of, and a cross-cutting theme in, many of the system failures leading to patient harm.1–3 – Highlighted jul 24, 2014
p.1: Past reviews of team performance measurement in healthcare indicated a lack of tools with strong theoretical grounding and methodologically rigorous development and validation processes.17 – Highlighted jul 24, 2014
Thanks Michael! I’ll send you some of the output files.
To answer your question: For the time being I will select the file in the Finder and have the script work from there. I would like all of the individual notes, once parsed, moved into a folder that has the same name as the original notes file.
I need to append the citation reference to the end of each individual file (the first entry of each full notes file) so it would look something like this:
Highlight or Note:
xxxx
Comment:
xxxxx
Citation Reference
Just so you’re aware, I will move the folder containing the parsed files into a Devonthink Database. I use this database to search for relevant snippets when writing grants or manuscripts.
As I’m reading this impressive macro, I found myself saying "Holy ^#@$, you can have KM do something with every selected file in Finder?! Then, “HOLY ^&#@(*%^#@, you can have KM take action on every substring found in a variable?!?!?!”
This is exciting stuff. I really need to get better at regular expressions…!
%Variable%temp% is the same as %Variable%filePath%/%Variable%fileName%, so I would have used that when reading the file. And since that’s the only use of fileName, that means that variable can be eliminated entirely.
I would be tempted to have:
Set Variable folderPath to %Variable%parentPath%/%Variable%fileBasename%
and use that in the Create New Folder and Write to File actions. That avoids the duplication which is always a potential future problem (what if you decide to name the folder something different, then you have two places to make the change).
The regex looks OK (although its always dependent on how variable the input is, but that is the nature of parsing text). I would have used \n\n+ at the end (so that it would cope with more than one blank line), but thats about it. I’m not really sure what [\s\S] is, it that just “match everything including line endings”? For that I would generally turn on the (?s) flag and then use “.”, but really it doesn’t matter.
[\s\S] was for all white space and non-white space characters.
The purpose of this (via trial and error) was to match both of the following as two separate matches for the way he has his notes:
some text here in a single string followed by two line returns (this is one match)
as well as
a line of text with only one line return
a line of text with only one line return
another line of text with one line return
a final line of text with two line returns (all four lines are one match)
I’m not as knowledgeable about the different flags. I’ll have to study them.
i — case insensitive (often Keyboard Maestro provides a default for this).
x — allows white space in patersn, and #commentotendofline comments.
s — “single line” mode. “.” matches any character instead of any character except eol (\n).
m — “multi line’ mode. “^” and “$” match the start and end of lines within the text.
Generally, you would only use (?x) for very complex regular expressions that you wanted to try to document inline.
You use them like this:
(?i)insensitive (?-i)CaseSenSiTive
\A.*\n(?s)(.*HERE) — matches the entire document (multiple lines) except the first line, until it finds the text.
(?m)^.HERE.$ — matches a single line containing the text.
The flags apply to the regex from that position onwards. You can also use them to apply to specific parts of the regular expression, like this:
(?i:insensitive) (?-i:CaseSenSiTive)
So [\s\S]+? should be the same as (?s:.+?) or even (?s:.)+?
Although this worked initially, I’m having trouble with the script recognizing new references.
It parses each individual note properly, but instead of appending the correct reference, it appends the same (old) reference left over from another paper. The old reference is not overwritten with the new.
This is hugely helpful. Please excuse me if this is basic–I’m new to KM–but can I append text to every file as it’s created? I’d like to include the bibtex citekey (from the clipboard) at the end of every one of the newly generated text files. Having a little trouble figuring it out.
Sorry. The above macro takes a single text file, parses it into a number of different files and adds them to a new subdirectory. What I would like to do is copy the clipboard to the end of each of those files as they are created.