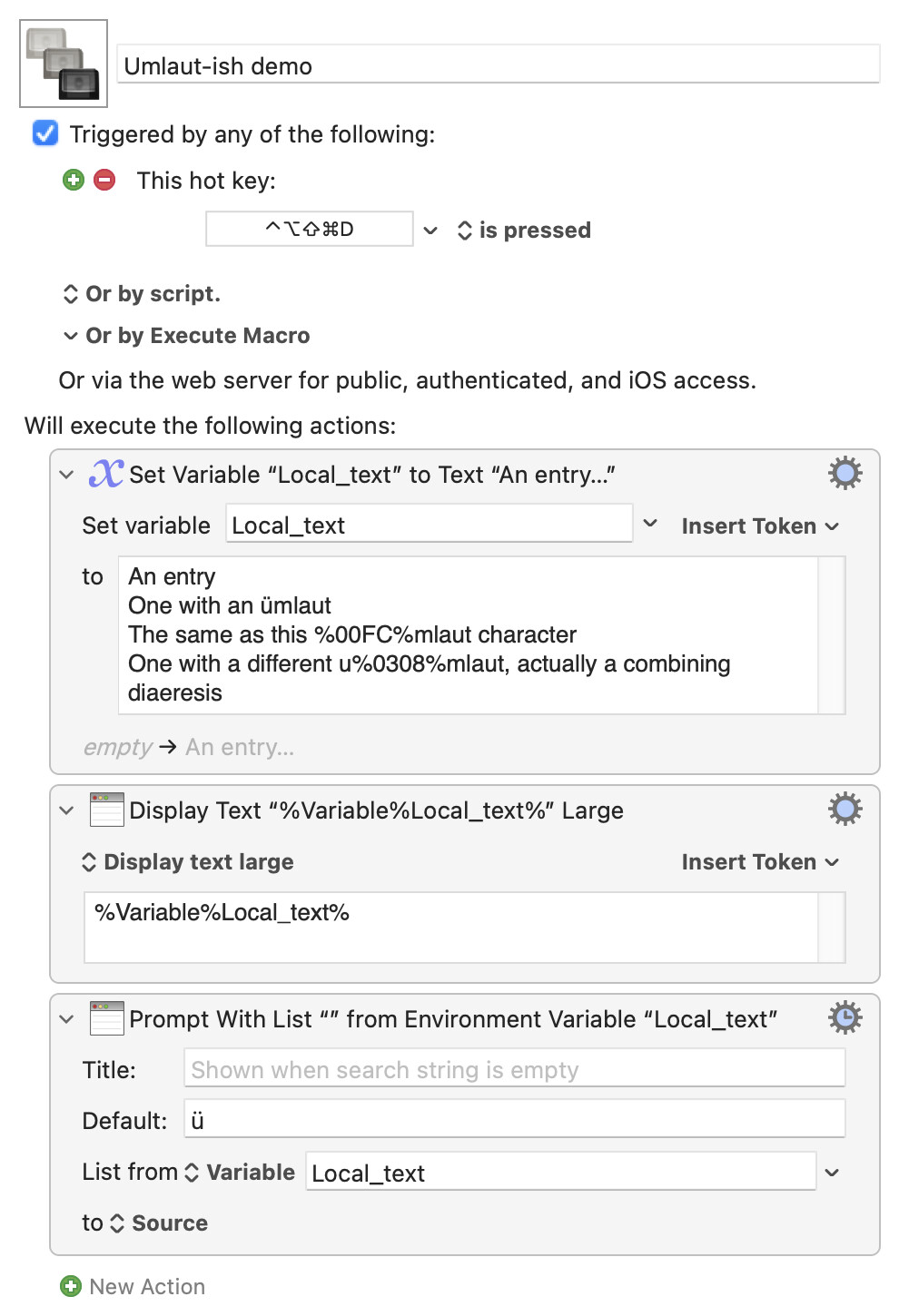
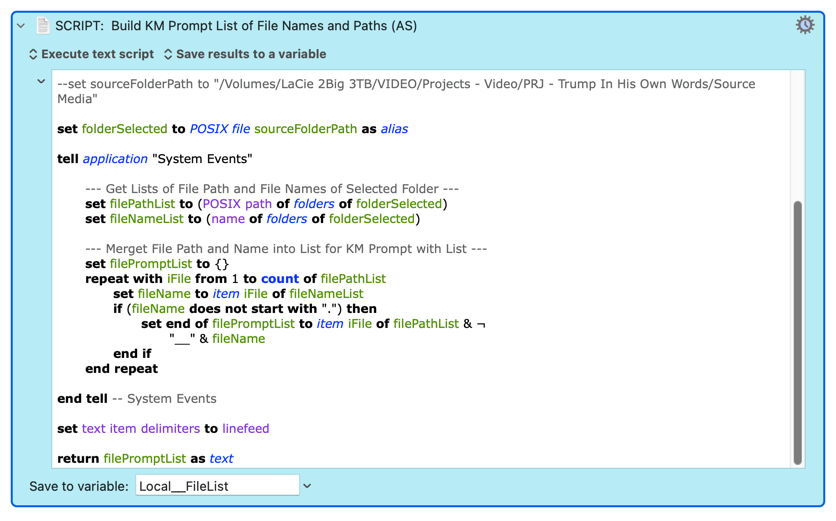
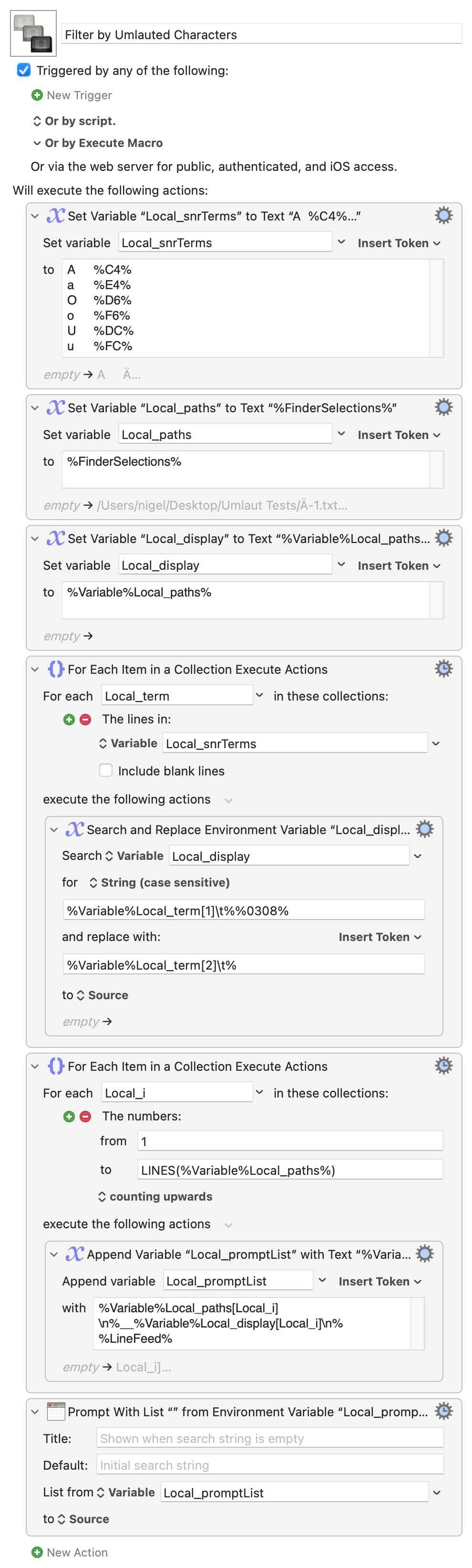
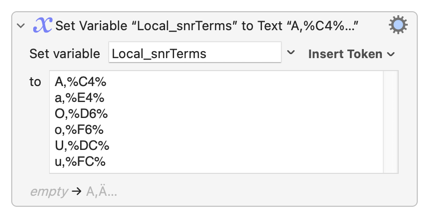
Yep -- it isn't part of the Search or Replace terms, it's part of the text token within them 
If you look carefully at the % symbols you'll see that the search is two tokens, a Variable and a Unicode token:
%Variable%Local_term[1]\t%%0308%
<-------Variable---------><-Uni>
KM has a neat trick where it can treat any string as an array, using the character(s) you provide as the element separators.
%Variable%Local_term[1]\t%
...can be read as
"Take the text stored in the variable Local_term and, using \t as the separator, return the first element."
Local_term holds a line from our tab-delimited Local_snrTerms table, so the first time through the loop it will contain
A<tab>%C4%
...so the search field token
%Variable%Local_term[1]\t%%0308%
...will evaluate to
A%0308%
...while the replace field token takes the second element (the [2]):
%Variable%Local_term[2]\t%
...and evaluates to
%C4%
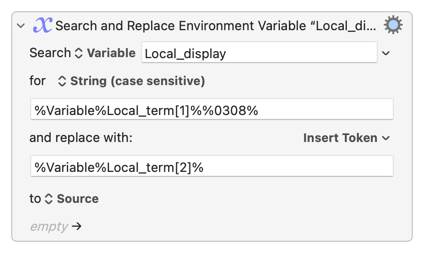
So this action
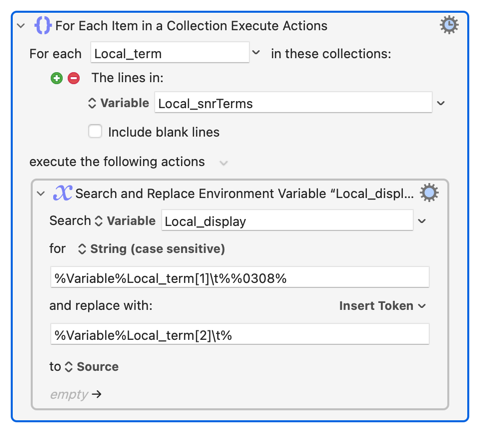
...can be explained as:
"For each line in our snrTerms table, search for the letter in column 1 followed by a combining diaeresis and replace with Unicode token in column 2."
We could have 6 individual, hard-coded, "Search and Replace" actions:
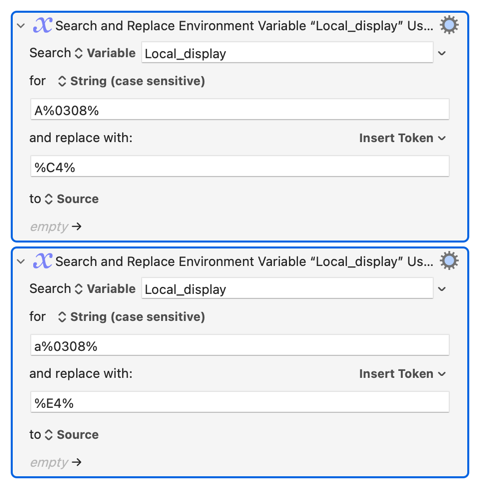
etc...
But the tab-delimited "table" is a convenient way to store our search-and-replace terms, and the "For Each" plus using variables in the search and replace fields lets us process all our terms in just two actions.
These "pseudo arrays" can be really useful when processing text -- we're also using them in the "Append Variable" action:
%Variable%Local_paths[Local_i]\n%__%Variable%Local_display[Local_i]\n%%LineFeed%
...where our separator is \n, so that can be read as "Line i of Local_paths, two underscores, line i of Local_display, and a linefeed".
See the "How to Use Custom Array Delimiter" section of "Using Variables" in the manual for more.