I'm so excited that I just got a new macro working, (it's still in prototype stages) that I have to share my progress. Perhaps there's no need for a macro like this, but I just wrote a macro that can "execute text-based code." To do this I had to create two macros:
- A macro called Parse that splits/stores code with braces into "atoms" of code in a dictionary;
- A macro called Interpret that executes the parsed code.
Here's how it works. You can create some "code" in a variable that looks like the following, and you pass the variable to the Parse macro.

The Parse macro is primarily concerned with finding all matched parentheses and placing individual statements into a dictionary called Code. The keys used for each block of code are random UUIDs. The root of the Code is remembered in a variable called LocalCodeRoot. In the example above, the dictionary that will be created will contain the following items, and the first line of this dictionary is the root.
358AE1F7-DB0F-4E65-B193-F03E2A10A0BF=set a1 to 3
if 5421EFCA-CA3E-46E3-885F-7D7FEAEA8088 then 9C676483-DAC9-4C54-A99B-CC96971EE0DE else 395C125E-14A9-4BAA-800E-009520C5F975
while 16AE0508-A4F2-48BB-998F-61623D19C411 do BD8DA623-69BE-414C-8ED4-43E1286A1FCE
repeat 489C6D12-F912-4EDA-A8FD-E2EEF72066EA until 9ABB13EF-9D2D-4DF5-BCB5-CBB681FF84B6
9ABB13EF-9D2D-4DF5-BCB5-CBB681FF84B6=RAND(3)=1
9C676483-DAC9-4C54-A99B-CC96971EE0DE=set a2 to 3
16AE0508-A4F2-48BB-998F-61623D19C411=a2>0
358AE1F7-DB0F-4E65-B193-F03E2A10A0BF=set a1 to 3
if 5421EFCA-CA3E-46E3-885F-7D7FEAEA8088 then 9C676483-DAC9-4C54-A99B-CC96971EE0DE else 395C125E-14A9-4BAA-800E-009520C5F975
while 16AE0508-A4F2-48BB-998F-61623D19C411 do BD8DA623-69BE-414C-8ED4-43E1286A1FCE
repeat 489C6D12-F912-4EDA-A8FD-E2EEF72066EA until 9ABB13EF-9D2D-4DF5-BCB5-CBB681FF84B6
395C125E-14A9-4BAA-800E-009520C5F975=set a2 to 4
489C6D12-F912-4EDA-A8FD-E2EEF72066EA=say goodbye
5421EFCA-CA3E-46E3-885F-7D7FEAEA8088=a1<3
BD8DA623-69BE-414C-8ED4-43E1286A1FCE=say hello
I know that's hard to read because of all the UUIDs, but basically it's just a tree of statements, with each branch being named by a UUID. I'm not sure if this is the most elegant design, but it works.
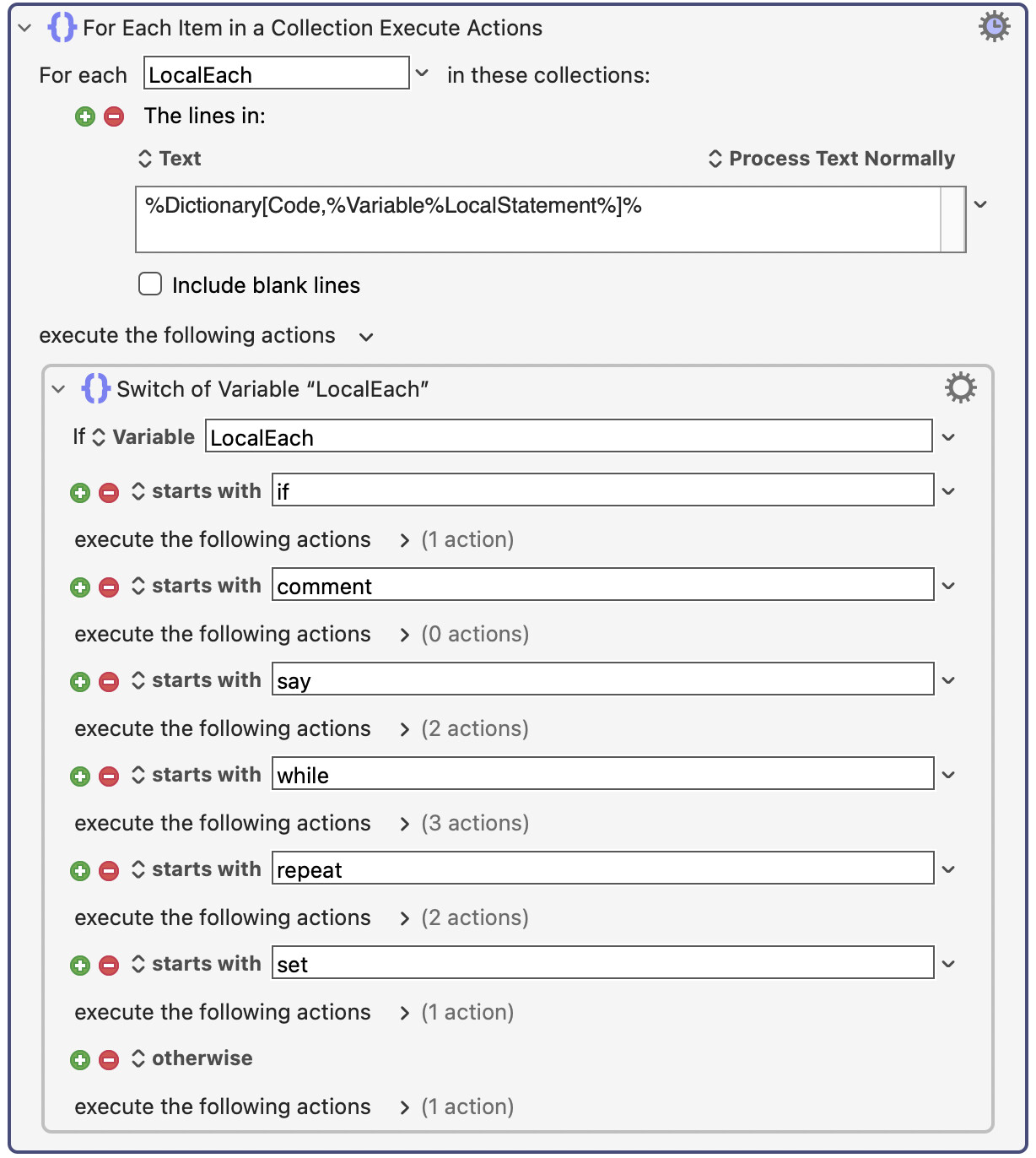
Then the root of this tree is passed to the "Interpret" macro, which starts at the root and executes each line in each branch, but calls itself recursively if it comes across another UUID. Processing each line is also performed. I currently have about five different kinds of statements implemented (while, if, repeat, say, set) but this will expand now that the Parse macro works.
At the very highest level, the Interpret macro looks like this:
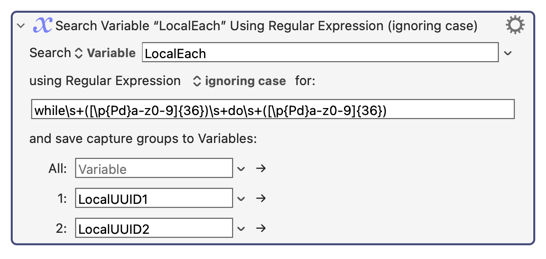
Then, as an example, here's the code that handles the While statement. The first thing it does is extract the two UUIDs representing the condition and the code of the While statement, like this:
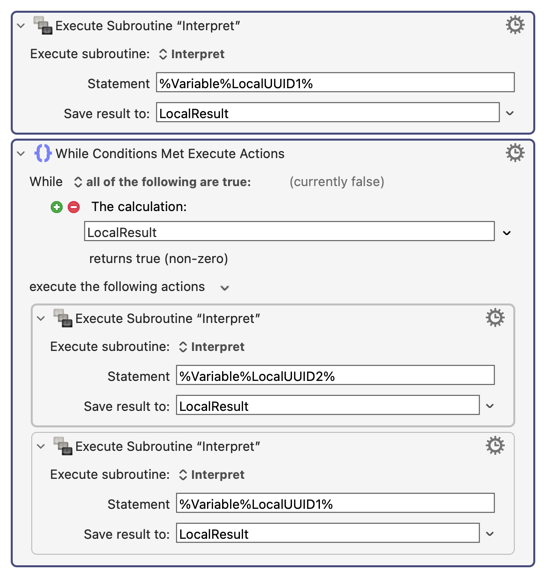
Then the UUIDs for the condition and the code are passed recursively to another instance of the Interpret macro, like this:
So I'm not really creating or compiling a new language, it's more like using KM's abilities to implement text-versions of KM actions. I'm not sure if this approach has any usefulness at this time, it's just an area of research that I'm undertaking.
This wouldn't be possible if KM didn't have some amazing features, like the Calculate Filter. Without such features, this sort of thing would be much more difficult.
Ideally, I would like to implement dozens of KM actions using this approach, and also support a large number of KM's tokens. Why? Well, one of the last things I was working on in university before I found a full time job was a compiler. This is giving me a sense of accomplishment for failing to finish that task.