Some of them are for example pure JavaScript (for my Spotlight Search Prompt - based Macros.
I don’t know exactly at the moment which Text file types I have in these variables but I need to know which .txt Files I probably could change to their content based extension like .js if the contents are pure JavaScript - to mention my example.
It would be nice to know for which type of Text files I maybe will have to run any script to convert it before reading it into a KM Variable for a particular Macro‘s needs.
I would have thought any text (utf8 encoded, by default) would be legible, regardless of file extension.
Experimentally, I find that as long as the content is a legible string of some kind, I can even give the file a misleading extension like .png, and the Read File To Variable action still works fine, and imports the text.
AFAIK the action relies on the OS's file read/write APIs. If the API, using the action's options, can get/make sensible text (I think it looks for valid text encoding) or image data then you should be good.
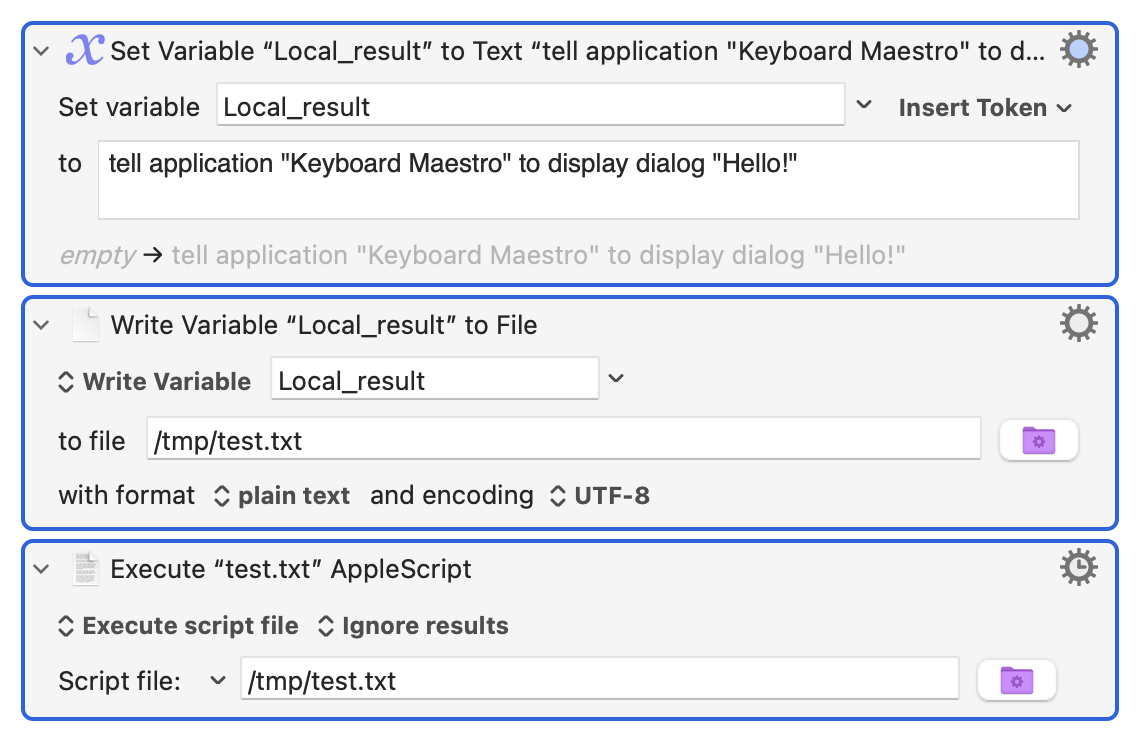
If it's a JavaScript file it makes sense to use a .js extension, especially if you might be opening it by Finder double-click, a KM "Open... with default application" action, or with an app that makes use of the extension (eg BBEdit's syntax highlighting) -- but KM will quite happily use a .txt file as the source for an "Execute whateverscript" action:
Many thanks for your information - very helpful as always…
Because the amount of Global Variables I need to Sync and the need to manually copy the contents back and forth when editing starts to grow I want to re-save the Files based on their contents with the right encoding to save me a lot of time.
The less amount of work I’ll have to do this way, the better
First of all - thanks for the hint on that variant of the Action … something I didn’t know about until today…
In my case though it makes absolutely no sense to use this Action, because I already said that every file is stored as plaintext regardless of their contents in the Format [Exact Name of Global Variable].txt ….
Maybe some of them are plaintext for real but others are JavaScript or AppleScript or JSON or something else.
I’ll maybe use this action to build a Macro that performs something like batch tagging or so - therefor this action makes really sense.
But it will not fit in my purpose I am describing here. The files are in sync over Dropbox already and new data will be passed back and forth if needed using a tagging system and Macros triggered by Hazel between my machines and VMs.
For backing them up and Version Control I also already have Macros which I use every time I need to.
Not sure I quite understand your “for real” distinction.
Source code utf8 seem to me as much plain text as paragraph utf8, with or without MD markup, but clearly the distinction is at work, and useful, somehow, in what you are doing.
With “for real” I mean it like I said it - just text without markup - and to make it clear absolutely no code in any language.
Information that is stored aas Binary code or Base64 is the only thing that I use to keep with the .txt Extension for now unless I have a solution for that as well like maybe a sql lite database or so.
Is the following text with or without markup? It's actually impossible to know if a text file contains markings because many markings were specifically designed to look like symbols commonly in use in plain ASCII files, like we see in the example below.
My Resume
=========
I founded Apple Computer, Inc.
Hmm, this reminds me of one of my great accomplishments in life. It took me scores of hours of work, but I once managed to create a text file using the MS-DOS echo command which created an executable COM file. If I showed you that file as an ASCII file, how would you know it's an ASCII file or a COM file? It's all a matter of whether the data works or not.
I‘ll not respond any further on this type of conversation because it goes to far off topic and is drifting into something like what I maybe think or don’t think is plain text or any other thing like if I know if a text contains Markup or not from just seeing….
This is a topic where I wanted to know about supported or unsupported text-based Files for the Read a File Action so that I can re-save my Files with the right extensions based on the contents to safe me a lot of time.
This topic is not marked as solved because it contains more than one suggestion or reply that was helpful. - If you have more helpful suggestions for me what’s supported or not then I am open for those.
Yes. I agree, you wanted to know how to read the contents of a file to determine what type of file it "really" is. That's an extremely tough task. You might want to look online to see if there are any apps that can do this.
There is a built-in macOS utility called "file" which does this, but I'm not sure how accurate it is. Then there are other tools you can get online that also claim to do this, such as:
That’s wrong … I said that I not know the contents of each of the Files because I have many of them and if I am editing I copy the contents into a Texteditor or IDE every time to ensure the syntax is always correct.
I only wanted to know what types are or aren’t supported by using the files with the correct extension. So that I don’t have to do this extra work every time.
I‘ll re-save them all manually because I have some files that are JSON code which has to be in a specific order and will not work if it doesn’t get saved in the supposed order (the Macros will break).
Plain text is in the eye of the beholder, which is why your definition may differ from mine. Strictly speaking (p18 of the Unicode standard), HTML is not plain text -- it's rich text represented as a plain text stream. But most of us would consider it to be plain text because it can be processed with tools designed to do so (grep, sed, less, etc on the CLI side).
You can also see from that that the file extension has nothing to do with whether the file is "plain text" or not. It's there to give the OS and apps an idea of the contents of the file and how they should be processed, and even that's a guideline rather than a rule. And you can usually get from rich text to plain text by simply stripping all the tags, just as you can with HTML.
When it comes to file naming you can do what you want, even make up your own extensions! But, IMO, it makes sense to use conventional ones -- js for JavaScript, md for Markdown, txt for things that are just text with no further meaning (like an unformatted Read Me) -- because then your OS and apps will be able to make sense of what's going on. You can double-click the js file and have it open in your preferred IDE, or Spotlight search for Markdown files and know yours will be included.
When it comes to the "Read File" action, it (and the underlying APIs) will do its best. Even an RTF file will be read in as the actual RTF, complete with formatting codes, although you'd have to do some fun stuff to extract actual readable text! So I've yet to find a text file that it won't open. You certainly should be safe with the "usual suspects" for portable structured data storage like JSON, XML, YAML...
And if you are writing them out, you'll know how to read them back in later.