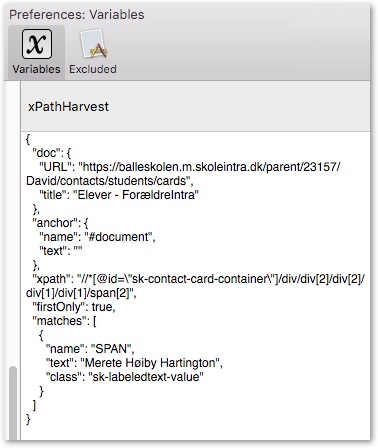
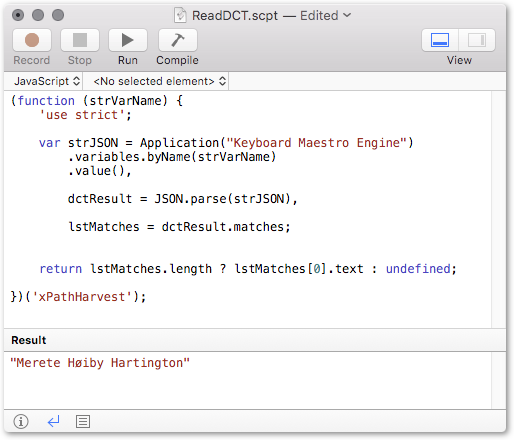
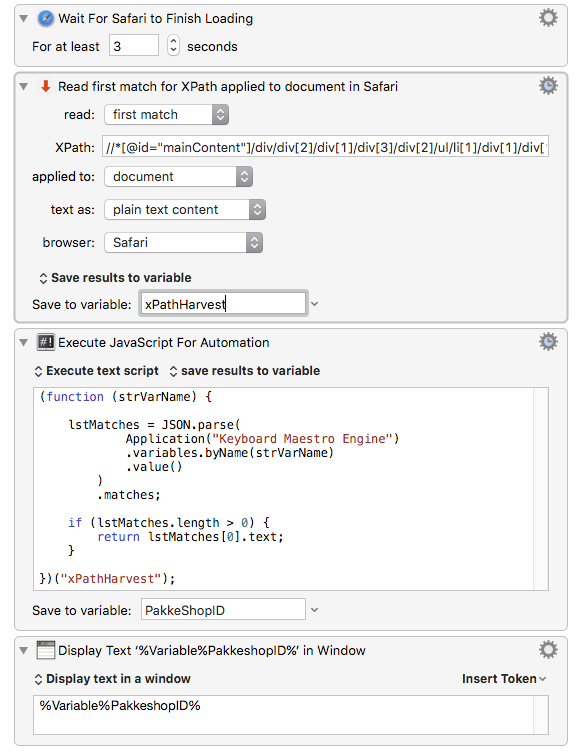
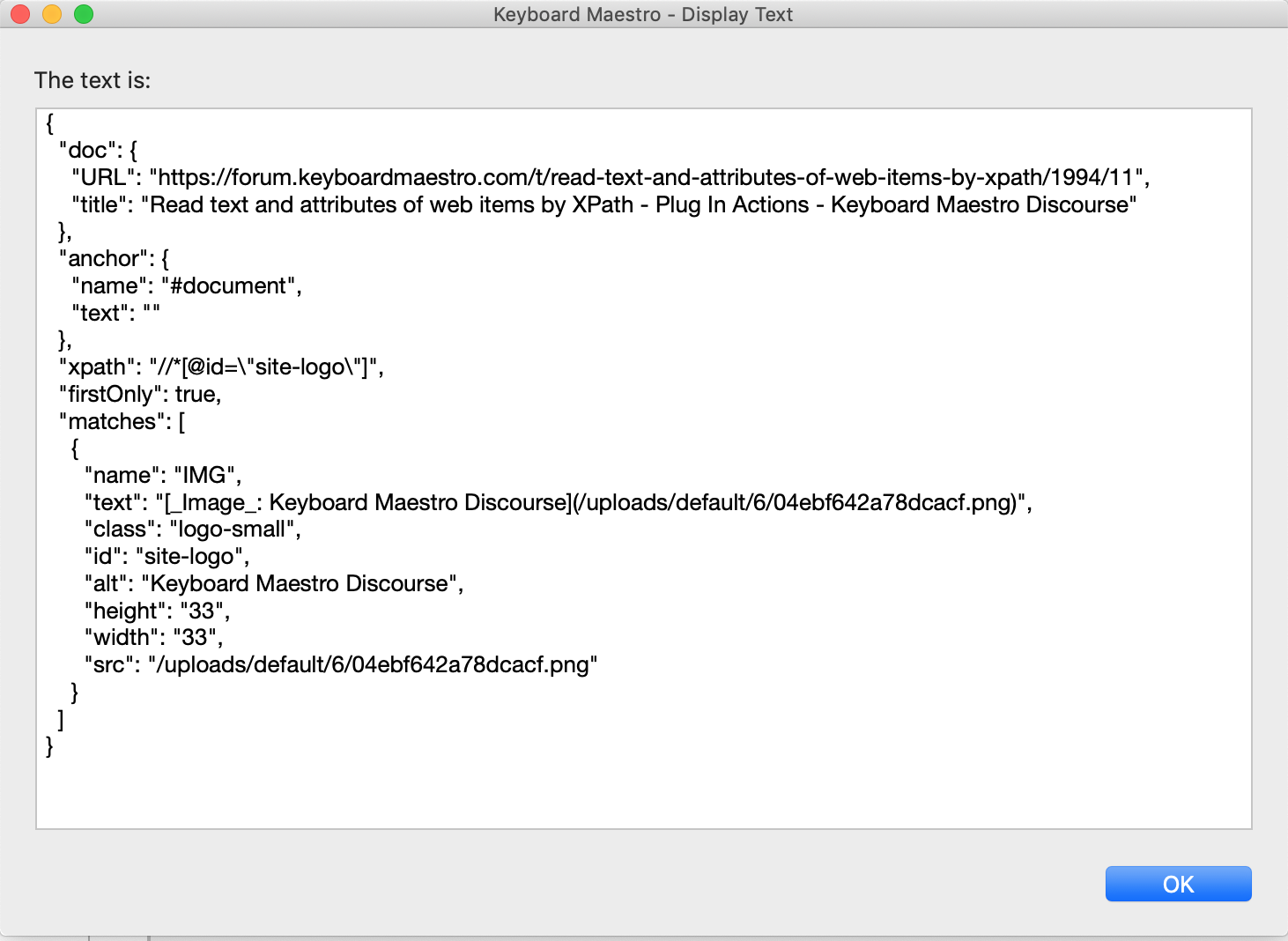
For reference, unminified .js source code:
// Rob Trew, Twitter @ ComplexPoint 2015.
// ( the mdString() function includes code adapted from David Bengoa's https://gist.github.com/YouWoTMA/1762527 )
(function () {
'use strict';
function fnAttributes(strPath, strAnchor, strFormat, blnFirstOnly) {
// PATH STARTS AT DOCUMENT ROOT, OR SELECTION ?
var nodeAttribs = function (oNode) {
varType = (
oNode ?
oNode.nodeType :
null
),
varAttribs = (
(varType === Node.ELEMENT_NODE) &&
oNode.hasAttributes()
) ? oNode.attributes : null,
i = varAttribs ? varAttribs.length : 0,
dct = {};
dct.name = oNode.nodeName;
dct.text = (varType !== Node.DOCUMENT_NODE) ?
(
strFormat.indexOf('HTML') !== -1 ?
(
strFormat.charAt(0) === 'i' ?
oNode.innerHTML : oNode.outerHTML
) : (
strFormat.charAt(0) === 'M' ?
mdString(oNode, strHost) :
oNode.textContent.replace(/\s+/g, " ")
)
) : '';
while (i--) {
dct[varAttribs[i].name] = varAttribs[i].value;
}
return dct;
},
// The mdString() function includes code adapted from https://gist.github.com/YouWoTMA/1762527
mdString = function (oNode, strHost) {
function nodeMD(oNode, strContext) {
function mdEscaped(text) {
return text ? text.replace(/\s+/g, " ").replace(
/[\\\-*_>#]/g, "\\$&"
) : '';
}
function nreps(s, n) {
var o = '';
if (n < 1) return o;
while (n > 1) {
if (n & 1) o += s;
n >>= 1;
s += s;
}
return o + s;
}
function chilnMD(oNode, strContext) {
return Array.prototype.slice.call(oNode.childNodes).reduce(
function (strMD, n) {
return strMD + nodeMD(n, strContext);
}, ''
);
}
var nl = "\n\n",
strHref = '',
rgxProtocol = /^(ht|f)tp(s?)\:\/\//,
strTag = oNode.tagName,
strTagName = strTag ? strTag.toLowerCase() : '',
lngType = oNode.nodeType;
if (lngType === Node.TEXT_NODE) {
return mdEscaped(oNode.nodeValue)
} else if (lngType === Node.ELEMENT_NODE) {
if (strContext === "block") {
switch (strTagName) {
case "br":
return nl;
case "hr":
return nl + "---" + nl;
// Block container elements
case "p":
case "div":
case "section":
case "address":
case "center":
return nl + chilnMD(oNode, "block") + nl;
case "ul":
return nl + chilnMD(oNode, "u") + nl;
case "ol":
return nl + chilnMD(oNode, "o") + nl;
case "pre":
return nl + " " + chilnMD(oNode, "inline") + nl;
case "code":
if (oNode.childNodes.length === 1) {
break; // use the inline format
}
return nl + " " + chilnMD(oNode, "inline") + nl;
case "h1":
case "h2":
case "h3":
case "h4":
case "h5":
case "h6":
case "h7":
return nl + nreps("#", +strTagName[1]) + " " + chilnMD(
oNode,
"inline") + nl;
case "blockquote":
return nl + "> " + chilnMD(oNode, "inline") + nl;
}
}
// UL | OL
if (/^[ou]+$/.test(strContext)) {
if (strTagName === "li") {
return "\n" + nreps(" ", strContext.length - 1) +
(strContext[strContext.length - 1] ===
"o" ? "1. " : "- ") + chilnMD(oNode, strContext + "l");
} else {
console.log("[toMarkdown] - invalid element at this point " +
strContext.tagName);
return chilnMD(oNode, "inline")
}
} else if (/^[ou]+l$/.test(strContext)) {
return chilnMD(
oNode,
strContext.substr(
0, strContext.length - 1
) + (strTagName === "ul" ? "u" : "o")
);
}
// IN-LINE
switch (strTagName) {
case "strong":
case "b":
return "**" + chilnMD(oNode, "inline") + "**";
case "em":
case "i":
return "_" + chilnMD(oNode, "inline") + "_";
case "code": // Inline version of code
return "`" + chilnMD(oNode, "inline") + "`";
case "a":
return "[" + chilnMD(oNode, "inline") + "](" +
(
strHref = oNode.getAttribute("href") || '',
rgxProtocol.test(strHref) ? strHref : (
(strHref && (strHref.charAt(0) === '#')) ?
strPageURL + strHref :
strHost + strHref
)
) + ")";
case "img":
return nl + "[_Image_: " + mdEscaped(oNode.getAttribute("alt")) +
"](" +
oNode.getAttribute("src") + ")" + nl;
case "script":
case "style":
case "meta":
return "";
default:
console.log("[toMarkdown] - undefined element " + strTagName)
return chilnMD(oNode, strContext);
}
}
}
// Translated to Markdown
// and LF sequences normalised
function toMarkdown(oNode) {
var strMD = nodeMD(oNode, "block");
return strMD ? strMD.replace(/[\n]{2,}/g, "\n\n").replace(
/^[\n]+/, "").replace(/[\n]+$/, "") : '';
}
/*******************/
return toMarkdown(oNode);
},
oAnchor = (strAnchor === 'document') ?
document : (
(strAnchor === 'selection') ?
window.getSelection().anchorNode : null
),
// OR PATH STARTS AT MOUSE ?
nh = oAnchor ? null : document.querySelectorAll(':hover'),
iLast = (nh ? nh.length : null),
nodeHover = iLast ? nh[iLast - 1] : null,
// IF WE HAVE A STARTING POINT,
// DOES THE PATH YIELD MATCHES THERE ?
oRoot = oAnchor ? oAnchor : nodeHover,
xr = oRoot ? document.evaluate(
strPath,
oRoot,
null,
blnFirstOnly ?
XPathResult.FIRST_ORDERED_NODE_TYPE :
XPathResult.ORDERED_NODE_ITERATOR_TYPE,
null
) : null,
// XPATHRESULTS --> [match] (list of any matches)
nodesToRead = xr ? (
blnFirstOnly ? [xr.singleNodeValue] :
(function () {
var lst = [],
oNode = xr.iterateNext();
while (oNode) {
lst.push(oNode);
oNode = xr.iterateNext();
}
return lst;
})()
) : [],
oLocn = window.location,
strHost = oLocn.protocol + "//" + oLocn.host,
strPageURL = document.URL;
// HARVEST IN JSON FORMAT
return JSON.stringify({
'doc': {
'URL': strPageURL,
'title': document.title
},
'anchor': oRoot ? nodeAttribs(oRoot) : null,
'xpath': strPath,
'firstOnly': blnFirstOnly,
'matches': nodesToRead.map(nodeAttribs)
}, null, 2);
}
// Evaluate code for a function application to a named browser (Chrome | Safari)
// fn --> [arg] --> strBrowserName --> a
function evalJSinBrowser(fnMain, lstArgs, strBrowser) {
var strFrontApp = strBrowser.indexOf(' or ') !== -1 ?
Application("System Events").applicationProcesses.where({
frontmost: true
})[0].name() : '',
strTarget = (
strFrontApp && (
['Safari', 'Google Chrome'].indexOf(strFrontApp) !== -1
)
) ? strFrontApp : (strBrowser !== 'Safari' ? 'Google Chrome' : 'Safari'),
blnSafari = (strTarget === 'Safari'),
appBrowser = Application(strTarget),
lstWins = appBrowser.windows(),
lngWins = lstWins.length,
// an open window (new if none exists)
oWin = lngWins && lstWins[0].id() !== -1 ?
lstWins[0] : blnSafari ?
appBrowser.Document().make() && appBrowser.windows[0] :
appBrowser.Window().make(),
strJS = [
'(', fnMain.toString(), ').apply(null, ',
JSON.stringify(lstArgs), ');'
].join('');
return (
blnSafari ?
appBrowser.doJavaScript(
strJS, {
"in": oWin.currentTab
}) :
oWin.activeTab.execute({
"javascript": strJS
})
);
}
/***** MAIN ***/
var a = Application.currentApplication(),
sysAttr = (
a.includeStandardAdditions = true, a
).systemAttribute;
return evalJSinBrowser(
fnAttributes, [
sysAttr("KMPARAM_XPath"),
sysAttr("KMPARAM_applied_to"),
sysAttr("KMPARAM_text_as"),
sysAttr("KMPARAM_read") === 'first match'
],
sysAttr("KMPARAM_browser")
);
})();