Good day.
I am slowly working with RegEx in KM and having some success. I currently am having difficulty figuring out why RegEx isn't completely selecting everything after the first SPACE encountered.
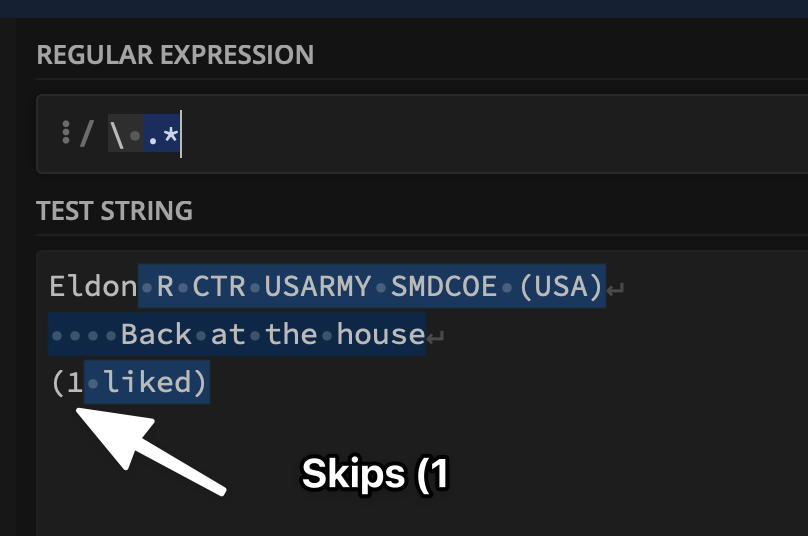
Your test string consists of 3 lines of text and the regex is running on each one independently, which is why the 1st and 3rd lines look similar in terms of the match.
By the way your regex isn’t finding everything AFTER the first space, as it is including the first space in the match.
So the regex you want needs to treat your input as a single line: (?-m)
Then the dot "." wildcard needs to match all newlines too: (?s)
Regex then looks like this: (?-m)(?s)^.*? (.*)$
where
^ means begin at the start of the text .*? (there's a space at the end of that) means match all characters up to and including the first space (.*)$ means return as a result everything else that follows up to the end of the text
As @tiffle indicates, the default scope of any regular expression is a single line.
Two special symbols ^ and $ allow you to match line start and line end respectively.
It may be worth:
searching for discussions of multiline (regex | regular expressions),
looking at the special regex character \R which can match an end of line delimiter,
and remembering that the details of line-delimiters vary a bit, depending on the source of the text, and may consist of one or two characters.
Most cases can be matched by a pattern like [\n\r]+
On the other hand, I would personally hesitate to use regular expressions anyway where the pattern is multi-line, or has any degree of complexity.
A scripting language like JavaScript or Python will give you more flexibility, and will tend to make your life a little easier, letting you split a string more easily into named parts.