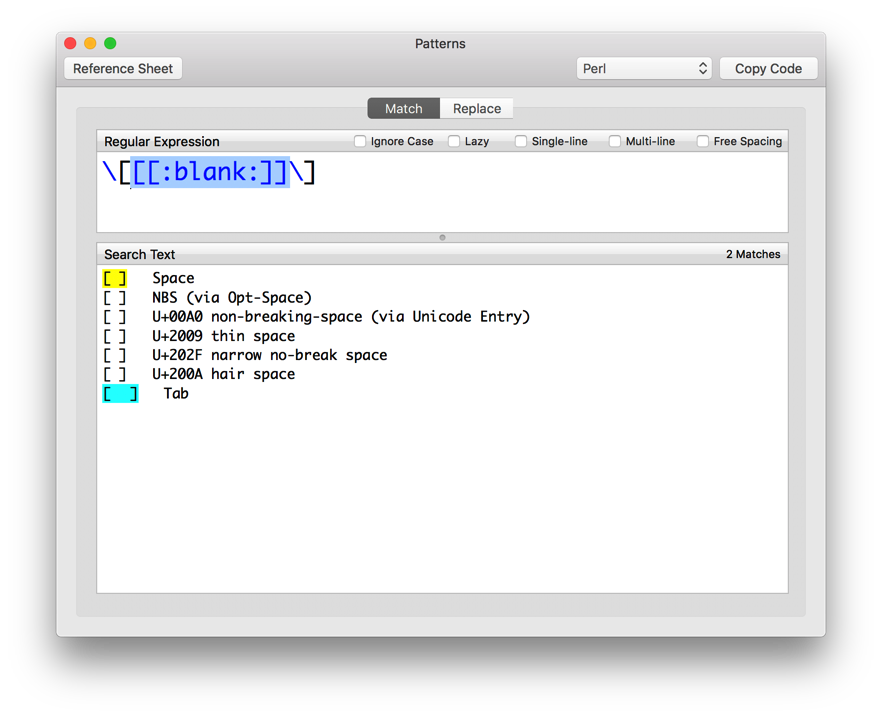
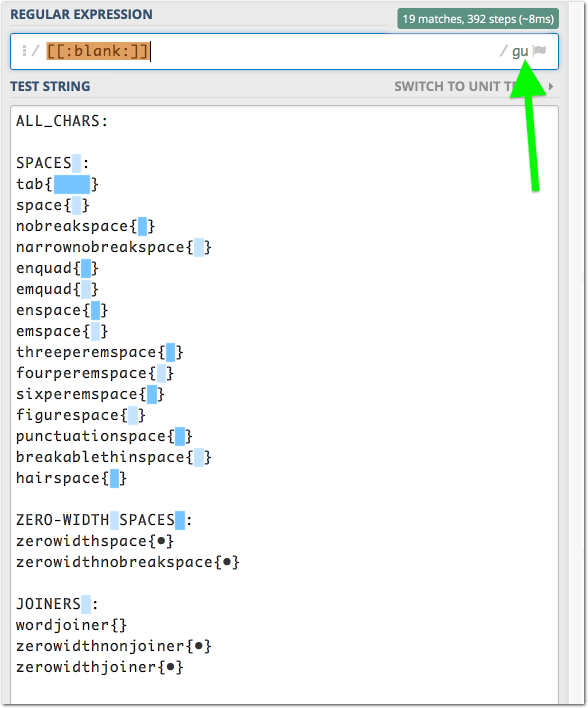
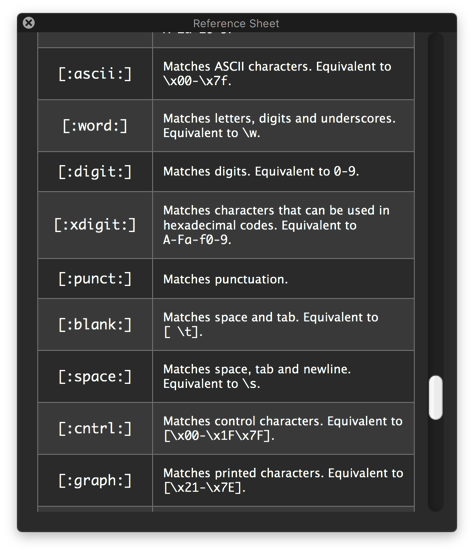
If you open the Help ➤ ICU Regular Expression Reference entry in Keyboard Maestro, you can see that \h is Space_Separator plus the ASCII tab (\u0009).
If you look up Help ➤ Regular Expression Unicode Properties and search for Space_Separator, you can find that
Space_Separator is the defined as `\p{Space_Separator} aka \p{Zs} aka \p{General_Category=Space_Separator} aka \p{gc=Zs} and contains these 17 characters.
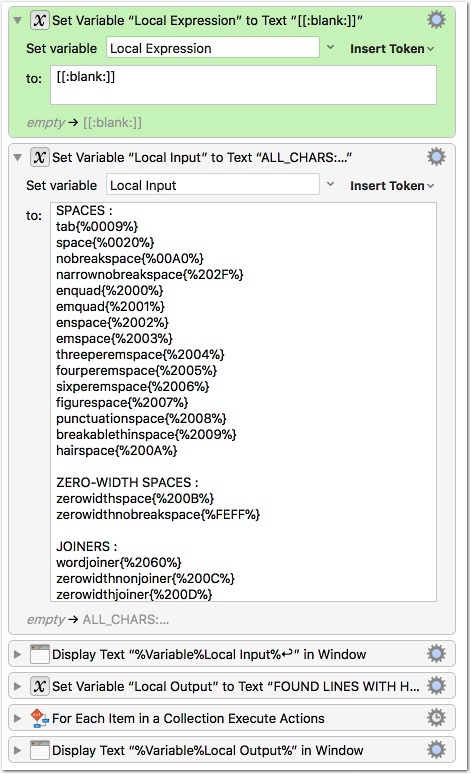
[32 SPACE][160 NO-BREAK SPACE][5760 OGHAM SPACE MARK][8192 EN QUAD][8193 EM QUAD][8194 EN SPACE][8195 EM SPACE][8196 THREE-PER-EM SPACE][8197 FOUR-PER-EM SPACE][8198 SIX-PER-EM SPACE][8199 FIGURE SPACE][8200 PUNCTUATION SPACE][8201 THIN SPACE][8202 HAIR SPACE][8239 NARROW NO-BREAK SPACE][8287 MEDIUM MATHEMATICAL SPACE][12288 IDEOGRAPHIC SPACE]
I haven’t updated the page in a while, so it is possible the category may have been extended somewhat.
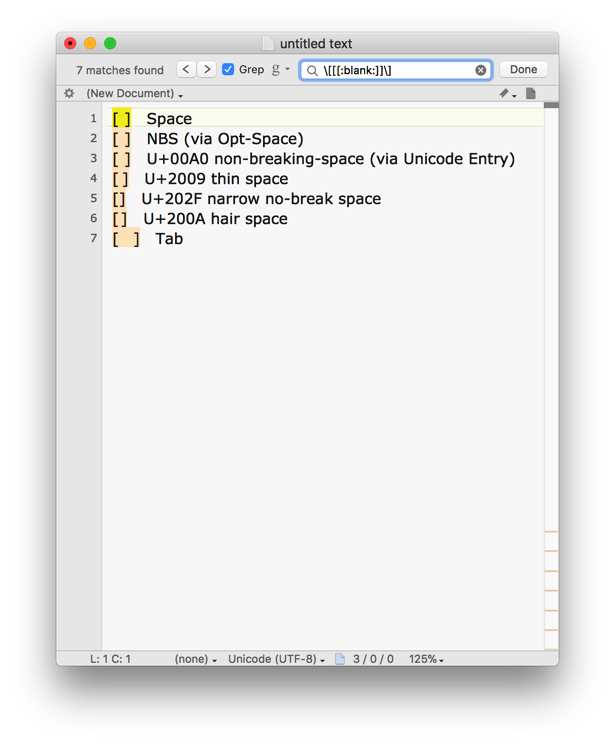
The same page will find the value of blank which is exactly the above set plus Tab, which should be exactly what \h uses.
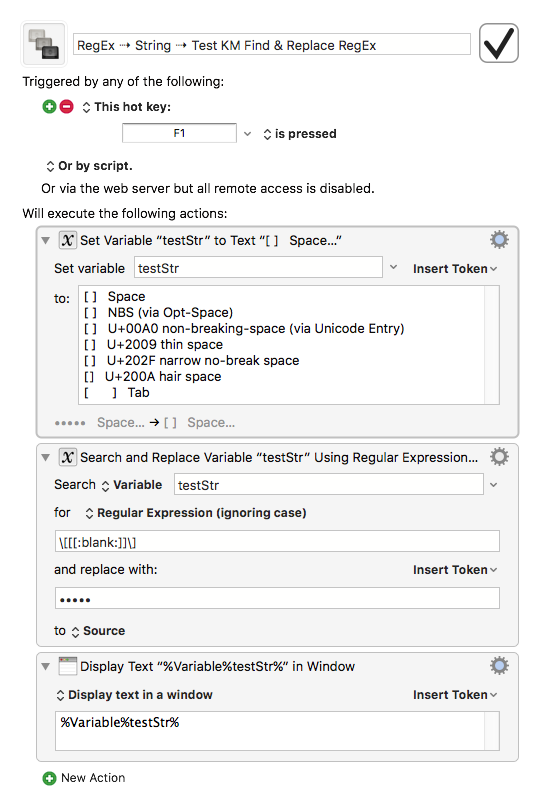
So [[:blank:]] or \p{blank} should be perfect, or [\p{Zs}\t]. All of which work on 10.10 (I checked ;- ).
\s matches [\t\n\f\r\p{Z}].
So [^\S\r\n] should match [\t\f\p{Z}]
But \f is form feed which should not be included, and \p{Z} is a different set.
[32 SPACE][160 NO-BREAK SPACE][5760 OGHAM SPACE MARK][8192 EN QUAD][8193 EM QUAD][8194 EN SPACE][8195 EM SPACE][8196 THREE-PER-EM SPACE][8197 FOUR-PER-EM SPACE][8198 SIX-PER-EM SPACE][8199 FIGURE SPACE][8200 PUNCTUATION SPACE][8201 THIN SPACE][8202 HAIR SPACE][8232 LINE SEPARATOR][8233 PARAGRAPH SEPARATOR][8239 NARROW NO-BREAK SPACE][8287 MEDIUM MATHEMATICAL SPACE][12288 IDEOGRAPHIC SPACE]
Which includes [8232 LINE SEPARATOR][8233 PARAGRAPH SEPARATOR] which should not be included.
So, all that, use [[:blank:]] or \p{blank} or [\p{Zs}\t] or take your changes with \h or a less accurate set.