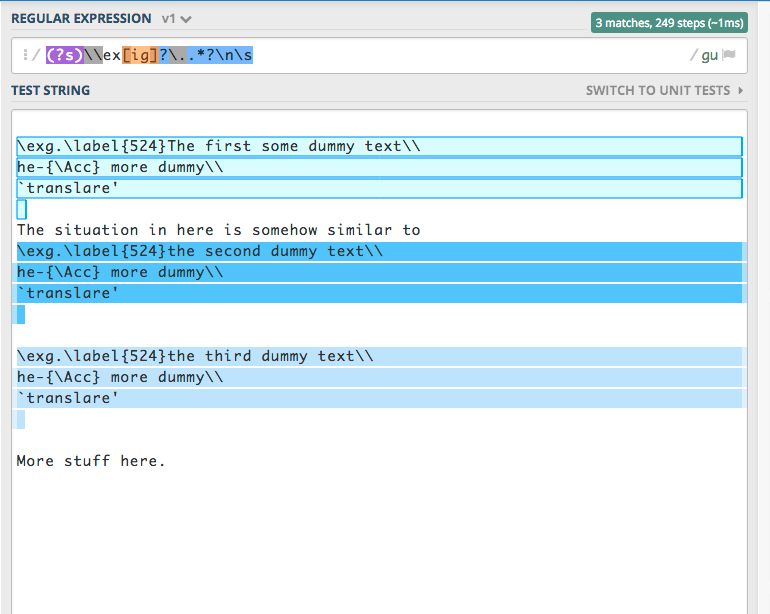
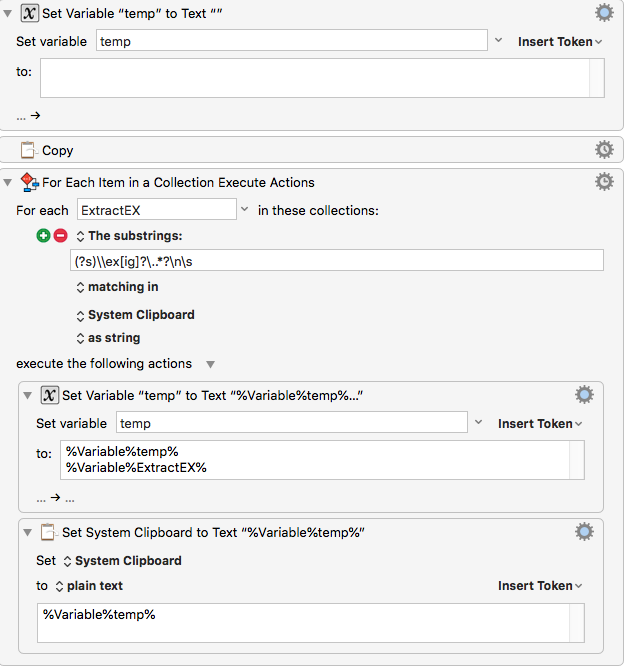
Why is this Regex matching only the first instance in KM?
It is getting only the line with the "the first dummy text", while other regex tools including https://regex101.com/r/jR5VA6/1. get all the matches?
I have to make the match non-greedy by adding "?" after ".*" because I want to filter out the texts in between the lines. The greedy one matches everything. I don't want that. But, making the match non-greedy seems to force KM to target only the first match.
You can use the same RegEx pattern to find each match, and for the subsequent Search Regex to extract the variables. OR, you can use a simpler RegEx in the For Each.
You can test the macro with the following examples.
I have a large text above this. I would like to pick just the examples.
\ex.\label{417}The first Dummy sentence\\
CAUS-{\Antic}-sleep\\
`interpretation '
I have a lot of text here.
\ex.\label{417}The second Dummy sentence\\
CAUS-{\Antic}-sleep\\
`interpretation '
The situation in here looks like more stuff is coming up.
I'm not sure what you mean. Exactly HOW does it not work?
If you mean that you are getting more matches than you want, then you will need to tell me what is unique about the two cases that you do want to match.
I looked at your macro, but it does not contain any sample data.
To determine the RegEx, we need:
A great, extensive, example of the real-world data to be searched.
(if it is too large to post, just zip it and upload the zip file)
A way to identify the cases you want to match:
Provide a real-world examples of the data to match.
OR
Provide a detailed description of what is unique, what is different, about these cases from all the rest of the text.
We're pretty good here, but reading minds is a skill we're still working on.
I am sorry that I didn't make myself clear. The lower part of the text (I put it under Formatted text) is supposed to be a sample, not part of my question.
Using the regex in SublimeText worked for me for now.
This macro extracts only the example sentences written in Linguex (Latex) format.
This package itself can extract examples (handout). But, it needs a lot of tweaking, and has some inherent weaknesses. The above macro solves the problem.